記事公開日
【AWS re:Invent 2025】「Amazon Bedrock AgentCore」で実現するAIエージェント構築

DXソリューション営業本部の山本です。AWS re:Invent 2025の会場から引き続きお届けしています。
生成AI(GenAI)の波は「チャットボット」から、自律的にタスクを遂行する「エージェント(Agentic AI)」へと急速に進化しています。
しかしエージェントの実装は「テナント間のデータ横断のリスクはどうする?」「推論コストの按分は?」「長時間実行時のステート管理は?」等、PoCはできるが、本番環境への適用には困難な壁が多かったのも事実です。
そんな悩みを一掃するかもしれない、「Amazon Bedrock AgentCore」を活用したマルチテナントSaaS構築のセッション(SAS407)に参加してきました。
本記事では、新発表のAgentCoreの正体と、それを活用したSaaSアーキテクチャの勘所を、技術的な深掘りを交えてレポートします。
主要なアップデートと発表のハイライト
本セッションでは、Amazon Bedrock AgentCore という新しいプラットフォーム(一連のサービス群)が、いかにしてSaaSの複雑な要件(マルチテナント)を解決するかが語られました。
-
Amazon Bedrock AgentCore Runtime:
-
エージェントコードをサーバーレスで実行する環境。最大8時間の長時間実行や非同期処理をサポートし、インフラ管理を大幅に削減します。
-
-
Amazon Bedrock AgentCore Gateway:
-
MCP (Model Context Protocol) をフルマネージドで提供。既存のAPIやLambdaを「ツール」としてエージェントに公開し、一元管理・セキュアな接続を実現します。
-
-
Amazon Bedrock AgentCore Identity:
-
エージェントのためのID管理。ユーザー(Inbound)の認証だけでなく、エージェントが外部ツールを叩く際(Outbound)の代理認証もハンドリングします。
-
-
AgentCore Memory:
-
セッションごとの「短期記憶」と、会話を跨いでユーザーの好みを記憶する「長期記憶(Long-term Memory)」を提供。SaaS向けに論理分離が可能です。
-
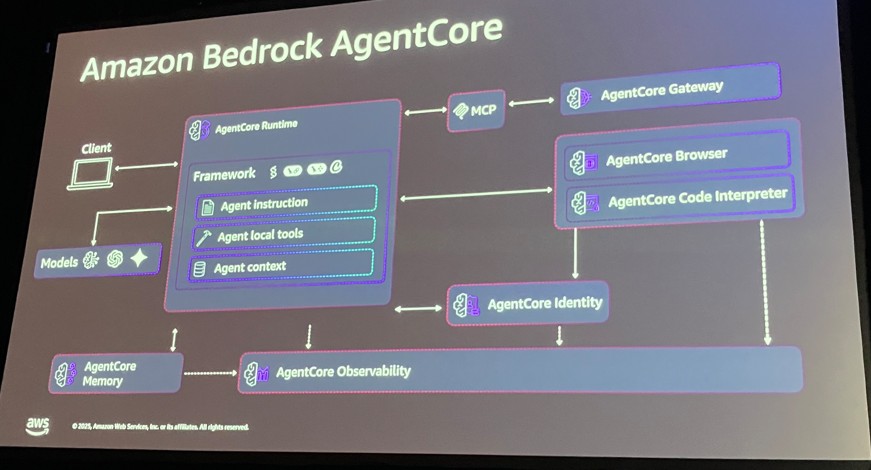
詳細解説:AgentCoreで解く「SaaS × AIエージェント」の5つの壁
講演では、SaaS × AIエージェント構築における「5つの壁」に対し、AgentCoreがどうアプローチするかを解説しました。
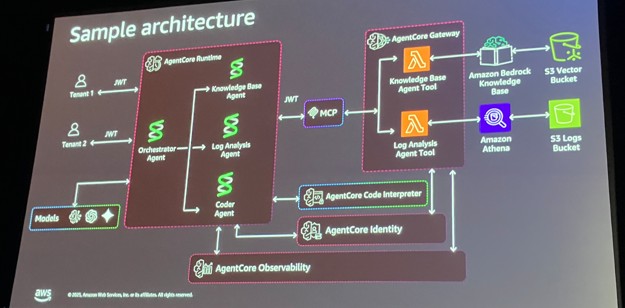
1. テナントの初期設定(Tenant Onboarding)
これまで、LangChainなどのフレームワークでエージェントを作ると、それを動かす「コンピュート環境(FargateやLambda)」、「メモリ管理(DynamoDBなど)」、「ツール接続」を全て自前で設計・運用する必要がありました。
AgentCoreの革新性は、これら「エージェントに必要な周辺インフラ」をAWSがマネージドサービスとして提供した点にあります。特にMCP (Model Context Protocol) のネイティブサポートにより、ツールの標準化が一気に進みます。開発者は「エージェントのロジック」だけに集中でき、SaaS特有の「テナント分離」の実装コストが劇的に下がります。
2. Identity(アイデンティティ):エージェントに「誰」を認識させるか
SaaSでは「誰が(ユーザー)」「どのテナントに属して」アクセスしているか管理が必須です。
-
Inbound Authorization(入り口):
-
Cognito等で発行されたJWTトークン(テナントIDやTier情報を含む)を
AgentCore Identityが検証し、エージェントに渡します。
-
-
Outbound Authorization(出口):
-
これが重要です。エージェントがSaaSのAPIやDBを触る際、「Workload Identity」 を使用して一時的なクレデンシャルを発行します。
-
これにより、エージェントは「テナントAのユーザー」として振る舞い、テナントBのデータにはアクセスできないよう制御されます。
-
3. Data Partitioning(データパーティショニング):メモリの壁
エージェントの「記憶(Memory)」がテナント間で混ざることは致命的です。セッションでは2つのモデルが示されました。
-
Siloモデル(分離重視): テナントごとにAgentCore RuntimeやMemoryリソースを物理的に分ける。プレミアムTier向け。
-
Poolモデル(共有重視): リソースは共有し、論理的に分離する。
-
AgentCore Memoryの活用:
Actor IDという識別子に「テナントID」や「ユーザーID」を組み込むことで、物理的には1つのDBでも、論理的に完全に分離された会話履歴を管理します。
-
4. Tenant Isolation(テナント分離):リソースアクセスの制御
エージェントが「Knowledge Base(RAG)」や「S3」にアクセスする際の制御です。他テナントにはアクセスさせないようにする必要があります。
-
RAGの分離: PoolモデルのKnowledge Baseでは、データ取り込み時にメタデータ(テナントID)を付与します。検索時、AgentCore GatewayがJWTからテナントIDを抽出し、自動的にMetadata Filteringを適用。他テナントのドキュメントが検索結果に出ないようにします。
-
ABAC(属性ベースアクセス制御): S3やDynamoDBへのアクセスには、IAMのABACを活用し、動的に生成されたクレデンシャルでアクセス範囲を絞ります。
5. Observability(可観測性):コストと挙動の追跡
AIエージェントは高コストになりがちです。SaaSビジネスでは「どのテナントがどれだけトークンを使ったか(Unit Economics)」の把握が重要です。
-
AgentCoreはOpenTelemetry (OTEL) を標準サポートしており、CloudWatch等にメトリクスを送れます。
-
Custom Metrics:
TenantIDをカスタムメトリクスとして埋め込むことで、CloudWatch Logs Insights等で「テナントごとのトークン消費量」を集計可能になります。これをQuickSightで可視化すれば、テナントごとの請求金額の算出も容易です。
所感・まとめ
「エージェントは作れるが、本番のSaaSに組み込むのは怖い」と感じていた開発者にとって、このセッションは希望の光でした。特に AgentCore Gateway が MCP をサポートしたこと は、今後のエージェント開発の標準が「MCPベース」になることを決定づける動きだと感じます。
「データレイクに全てのデータを集めてからAIをやる」——それが理想ですが、現実はそう簡単にいきません。データは散らばったまま、サイロ化し続けています。
今回の発表を聞いて、Amazon Bedrock AgentCoreは、「データは分散したままでいい。エージェントが安全にそこへ出張して、情報を取ってくる」という、極めて現実的かつ実用的なアプローチを提示していると感じました。
開発者はエージェントの「賢さ」に集中し、インフラ担当は「コストと安全性(ガードレール)」に集中する。
AgentCoreは、チームの役割分担をより健全な形に再定義してくれるかもしれません。
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください。 複雑な内容に関するお問い合わせの場合には直接営業からご連絡を差し上げます。 また、よろしければ以下のリンクもご覧ください!
<QES関連ソリューション/ブログ>
<QESが参画しているAWSのセキュリティ推進コンソーシアムがホワイトペーパーを公開しました>
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。

