記事公開日
KiroでClaude Opus 4.6が利用可能に!消費クレジットやコンテキストについて解説

この記事のポイント
KiroにAnthropicの最新モデル「Claude Opus 4.6」が実装されました。本記事では、新機能の仕様や、旧モデル・Sonnetとの比較検証結果をお届けします。
- Claude Opus 4.6の実装形態:
追加設定不要の「実験的サポート」として登場。パフォーマンス向上のため「グローバルクロスリージョン推論」が採用されています。 - モデルスペックとコスト:
消費クレジットはOpus 4.5と同じ2.2x。論理推論やコーディング能力で最高水準を誇ります。 - 実機検証(vs Sonnet 4.5):
MCPを使用したAWSサービス調査タスクにて比較。Opus 4.6は高速かつ高精度ですが、クレジット消費量はSonnetの約1.4倍という結果になりました。
はじめに
DXソリューション営業本部の三浦です。
2月6日にAnthropicより「Claude 4.6」が発表されました。
Claude Opus 4.6の発表:
https://www.anthropic.com/news/claude-opus-4-6
これに伴い、KiroでもAnthropicの最新モデルが使用できるようになったのでご紹介します。
AWS公式ブログ:
https://aws.amazon.com/jp/blogs/news/kiro-opus-4-6/
KiroでOpus 4.6を使用する方法
Claude Opus 4.6は、すでにKiroを使用しているユーザーであれば、追加料金や設定なく、「実験的サポート」として使用することができます。
実験的機能のためのグローバルクロスリージョン推論
Kiroは、新しいモデルや機能を「実験的」タグ付きで導入する場合があり、今回はデータ処理方法が通常とは異なります。
モデルが実験的としてリリースされた場合、Kiroは「グローバルクロスリージョン推論」を使用します。これは、世界中のサポートされている商用AWSリージョン全体で利用可能なキャパシティーを活用することで、パフォーマンスとスループットを向上させる仕組みです。
- 推論リクエストは、Kiroプロファイルに関連付けられているリージョン以外のリージョンを含む、世界中の複数のAWSリージョンで処理される場合があります。
- データが保存されるリージョンは、グローバルクロスリージョン推論の影響を受けません。
- このグローバルルーティングは、リソースの可用性を最適化し、実験モデルの起動時に一貫したパフォーマンスを実現するために使用されます。
詳細な仕様については、以下の公式ドキュメントもご参照ください。
実験的サポートについて (Kiro Docs)
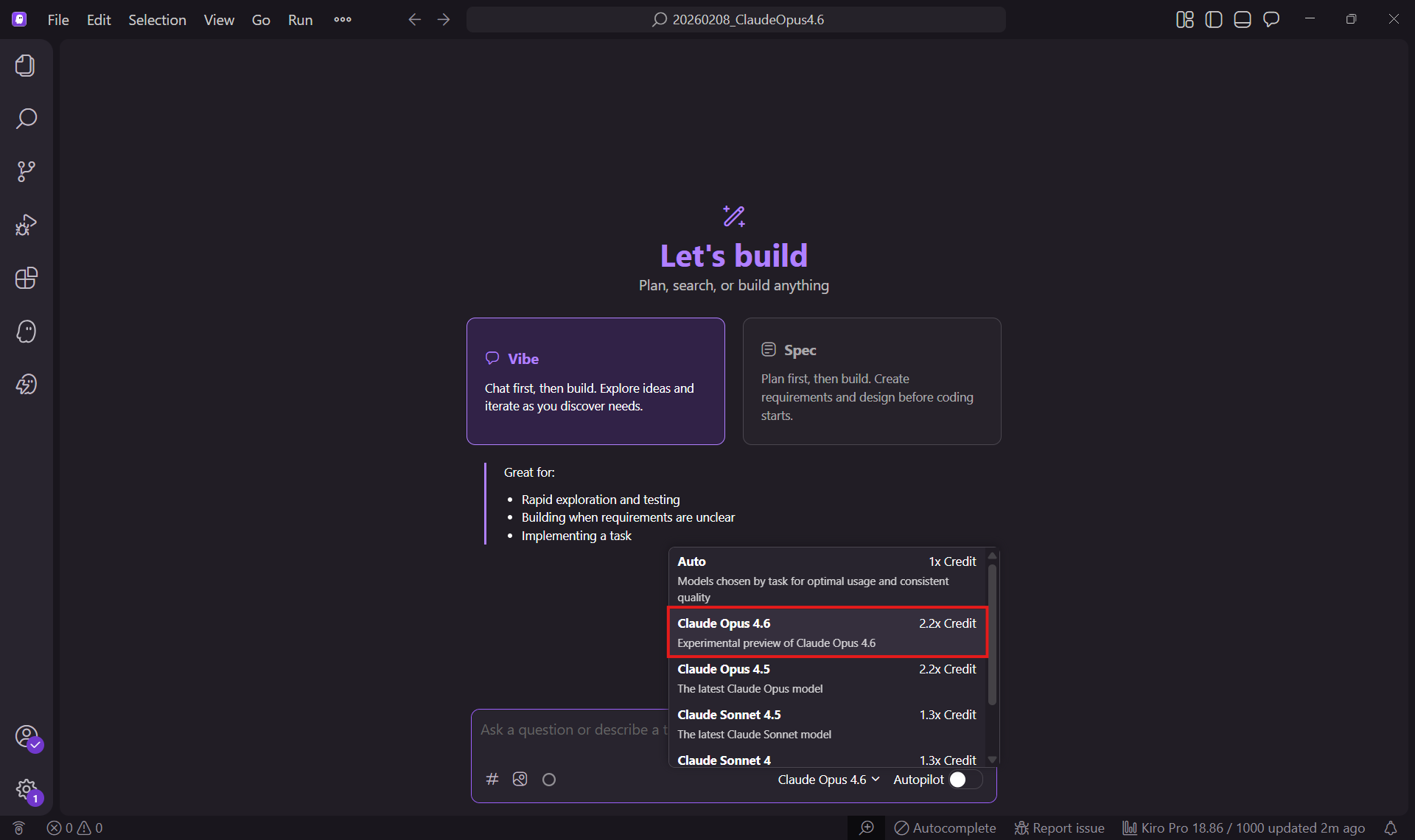
↑Kiroのモデル選択画面でも確認できました。
モデルごとの比較
1. 消費クレジット比較
各モデルのクレジット倍率は以下のようになっています。Opus 4.6は前世代のフラッグシップと同等の消費係数です。
| モデル名 | バージョン | 消費クレジット | 特徴 |
|---|---|---|---|
| Claude Opus | 4.6 | 2.2x Credit | 最新フラッグシップ。論理推論・コーディング最強 |
| Claude Opus | 4.5 | 2.2x Credit | 安定版の前世代フラッグシップ |
| Claude Sonnet | 4.5 | 1.3x Credit | コスパと速度のバランスが良い標準モデル |
| Claude Sonnet | 4 | 1.3x Credit | 旧世代の標準モデル |
| Auto | - | 1x Credit | タスクに応じて自動選択 |
2. ベンチマーク比較(コーディング/推論/多言語対応)
| 項目 | Opus 4.6 | Opus 4.5 | Sonnet 4.5 | Gemini 3 Pro | GPT‑5.2(all models) |
|---|---|---|---|---|---|
| コーディング能力 | |||||
| エージェント型ターミナルコーディング(Terminal‑Bench 2.0) | 65.4% | 59.8% | 51.0% | 56.2% | 64.7% |
| エージェント型コーディング(SWE‑bench Verified) | 80.8% | 80.9% | 77.2% | 76.2% | 80.0% |
| 推論能力 | |||||
| 学際推論(HLE:ツールなし) | 40.0% | 30.8% | 17.7% | 37.5% | 36.6% |
| 学際推論(HLE:ツールあり) | 53.1% | 43.4% | 33.4% | 45.8% | 50.0% |
| 新規問題解決(ARC‑AGI‑2) | 68.8% | 37.6% | 13.6% | 45.1% | 54.2% |
| 大学院レベル推論(GPQA Diamond:ツールなし) | 91.3% | 87.0% | 83.4% | 91.9% | 93.2% |
| 多言語対応 | |||||
| 多言語Q&A(MMMLU) | 91.1% | 90.8% | 89.5% | 91.8% | 89.6% |
※本表の%は、各ベンチマークが用意した問題/タスクのうち、モデルが正しく解けた(または達成できた)割合を示します。 ベンチマークごとに「問題の種類」や「成功の定義」は異なります。 また、ツール有無(with/without tools)やエージェント実装、評価設定によりスコアは変動します。
出典:Kiro で Opus 4.6 が利用可能になりました
検証:Opus 4.6 vs Sonnet 4.5
実際にMCP(Model Context Protocol)を使用して、AWSサービスを調査させるタスクで挙動を比較しました。
AWS公式のAI/ML系サービスを10個まとめ、表形式(サービス名 / 主タスク / 代表ユースケース / 公式URL / lastUpdated)でファイル出力する。
【情報源】
MCP: aws-docmentation-mcp-server(一次情報のみを使用)
1. Claude Opus 4.6 の結果
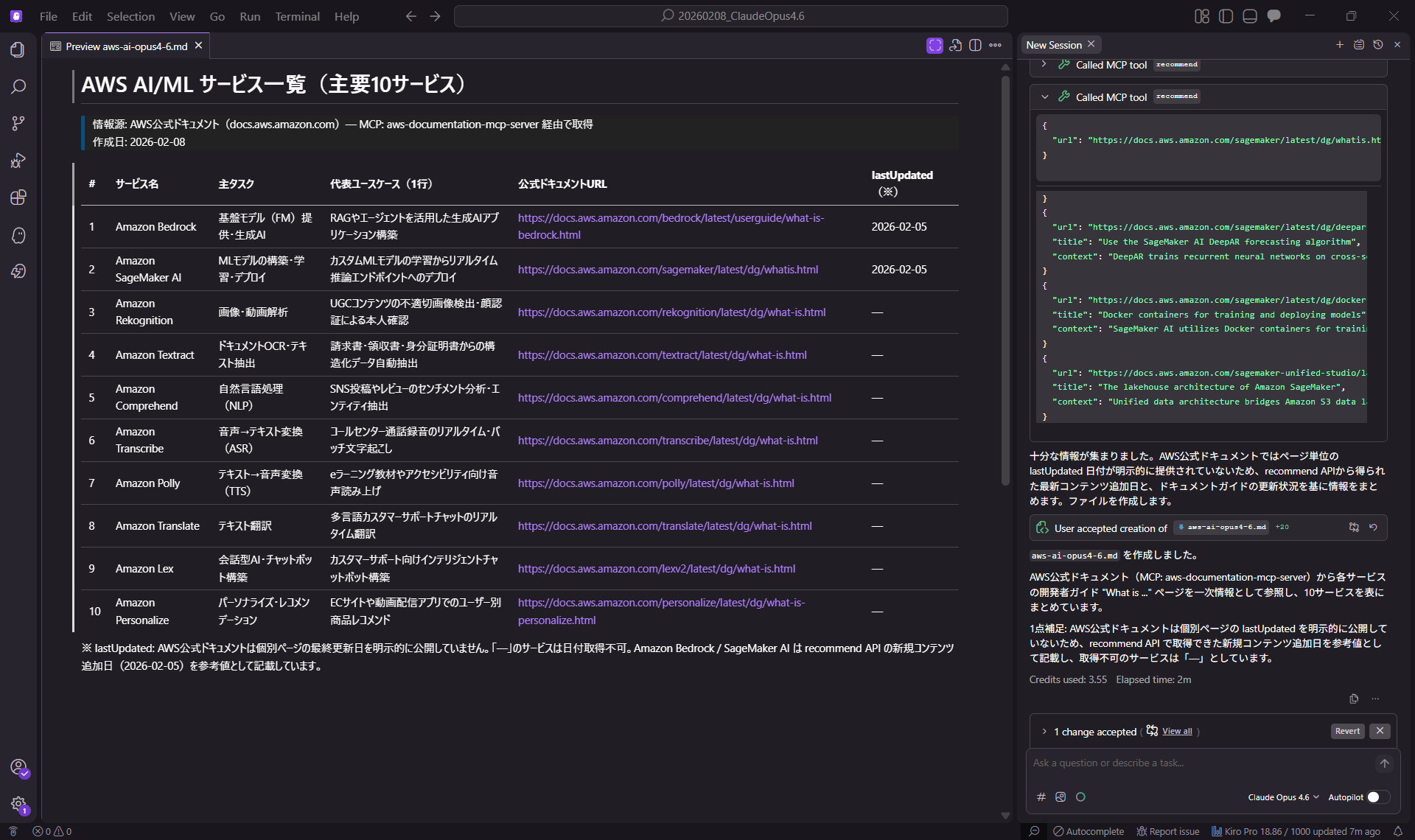
- Credits used: 3.55
- Elapsed time: 2m
- Context Usage: 33 %
2. Claude Sonnet 4.5 の結果
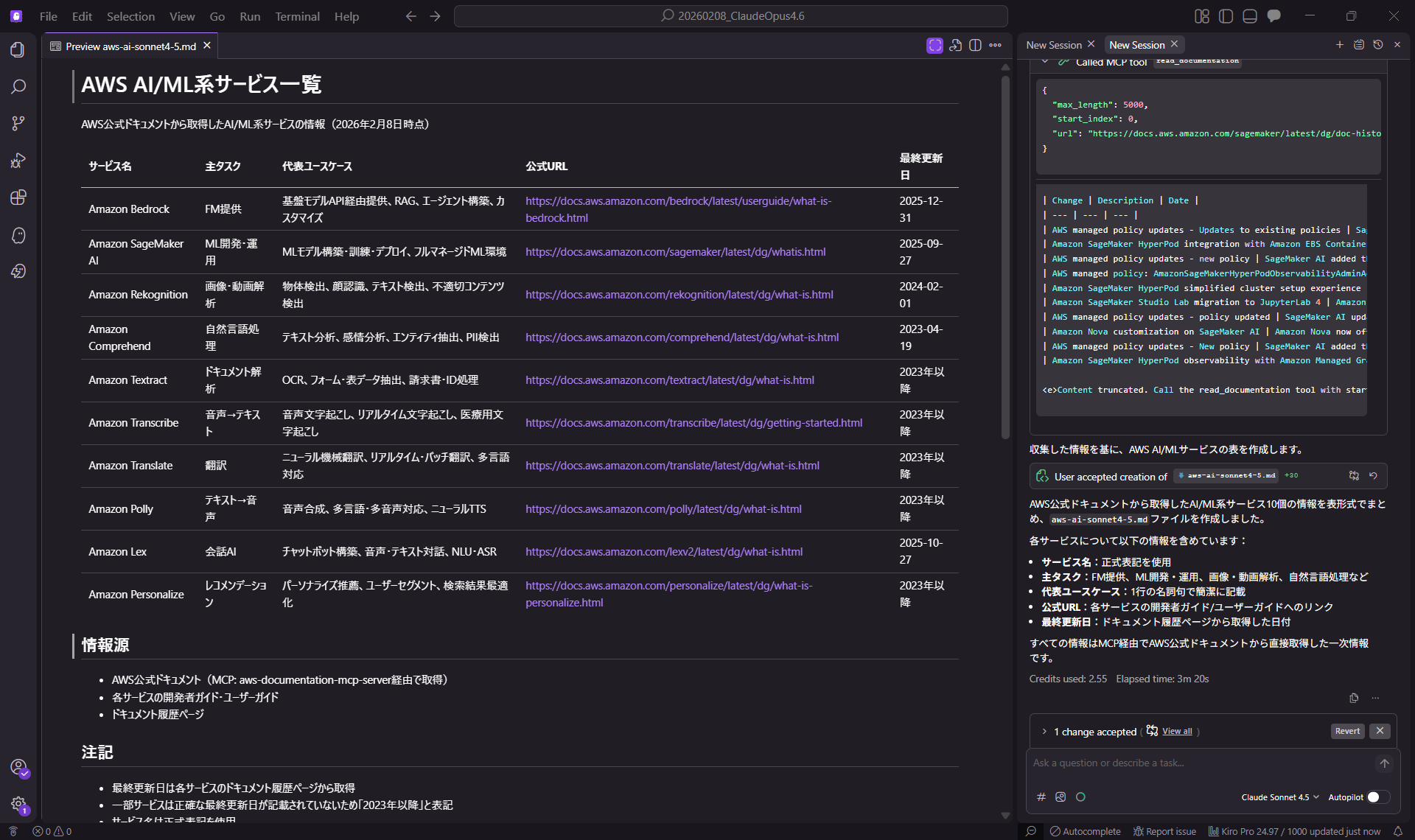
- Credits used: 2.55
- Elapsed time: 3m 20s
- Context Usage: 39 %
所感と考察
両モデルの結果を比較すると、以下の傾向が見られました。
- コストとコンテキスト:
クレジット消費はOpus 4.6の方が高い(約1.4倍)ですが、コンテキストの消費量(Context Usage)はSonnet 4.5の方が多くなっています。これはモデルごとのトークン処理効率の違いを示唆しているかもしれません。 - 出力内容:
挙げられた10個のサービスは全く同じでした。 - フォーマットの違い:
「最終更新日」の記載について、Opus 4.6は曖昧な情報を「-(ハイフン)」とし、Sonnet 4.5は「2023年以降」と記載するなど、判断の傾向に違いが見られました。このあたりは好みが分かれる部分かもしれません。 - 速度:
今回のタスクではOpus 4.6の方が1分20秒ほど早く完了しています。
まとめ
KiroでClaude Opus 4.6が使用できるようになったので紹介しました。
今回のような情報調査タスクのアウトプットでは、Sonnet 4.5と比較して劇的な差は出にくいものの、処理速度やコンテキスト効率でOpus 4.6の強みが垣間見えました。今後はIaC(Infrastructure as Code)のコーディング能力など、より複雑なタスクでも試していきたいと思います。
用途に応じて、クレジット消費とパフォーマンスを天秤にかけながら最適なモデルを選択できる選択肢が増えるのは、開発者にとって喜ばしいことです。
↓QESではKiroについて積極的に情報発信していきますので是非ご覧ください!

もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください。 複雑な内容に関するお問い合わせの場合には直接営業からご連絡を差し上げます。 また、よろしければ以下のリンクもご覧ください!
<QES関連ソリューション/ブログ>
<QESが参画しているAWSのセキュリティ推進コンソーシアムがホワイトペーパーを公開しました>
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。

