記事公開日
最終更新日
Azure AI Search の統合ベクトル化を試してみた

こんにちは。今回は、2023年11月にプレビュー機能として公開された Azure AI Search の 統合ベクトル化(Integrated vectorization)を試してみます。(本記事は、2023年12月の状態で検証しています。)
Azure Portalから利用できる機能であるため、ノーコードでデータを取り込んで検索したいという方には、便利な機能です。もともと取り込むだけの機能(「データのインポート」)はありましたが、さらにテキスト分割+ベクトル化がセットになったことでとても楽になりました。
今回の検証では、QESの技術ブログをスクレイピングしたテキストデータを用意しました。用意したテキストデータを Azure Storage に投入します。
今回はテキストデータを使用していますが、PDFファイルやOfficeファイルも取り込むことができます。
上部の「データのインポートとベクター化」をクリックします。
データを格納したストレージアカウントのコンテナーを指定します。
ベクトル化に必要な Azure OpenAI の設定を行います。デフォルトの状態ですが、セマンティックランカーも有効にします。AIスキルを使用すれば、画像データから文字を読み取ることもできるようですが、今回は読み込みデータがテキストなので使用しません。
オブジェクトのプレフィックスは、[vector-xxxxxxxxxxx] のような名称が勝手につくので、分かりやすい名称に変えておきます。この名称がインデックス名になります。
[作成]ボタンをクリック後、完了を待ちます。完了後、インデクサーが起動しますので、データの取り込みが完了するのを待ちます。データ量によりますが、インデクサーが状態が完了となるまで時間がかかります。
データが取り込まれると、[検索エクスプローラー]で検索できるようになります。[検索]ボタンを押してみます。
データが格納されているのが確認できました。"vector" にベクトル化された値も確認できます。
テキスト分割スキルの内容を確認すると、言語設定[defaultLanguageCode] が英語("en")になっていました。(これは、QESブログの「Azure Cognitive Search でキーフレーズ抽出」で紹介した言語設定の件と同じです)
テキストの分割サイズ[maximumPageLength]とオーバーラップサイズ[pageOverlapLength]も記載されていますので、こちらを修正すればテキスト分割サイズを調整できることが分かります。
検索のテストは、[Simple-Cognitive-Search-Tester] を使用させていただきました。インストール不要でブラウザで開くだけで、Azure AI Searchの検索を試せて検索結果も視覚的に分かりやすい便利なツールです。GitHubで公開されていますので、使用される場合は利用条件等ご確認のうえ、ご使用ください。
こちらのツールを使用する場合、CORSが許可されている必要があります。インデックス作成時は、既定で無効化されていますので、有効にします。([インデックス] → [vector-blog](インデックス名) → [CORS] →[すべて]を選択し、[保存])。
例として、単純な全文検索で検索キーワードを「想定以上」として検索してみます。検索結果のハイライトされている箇所を見ても分かる通り、「想定以上」という検索で、仮想の「想」であったり、設定や指定の「定」がヒットしていることが分かります。
これは、「想定以上」というキーワードがアナライザにより、以下のようにトークン分割されることが影響します。どのような分割になるか試したい場合は、[Analyze API] の使用すると任意の文字列でトークン分割を確認できます。
標準アナライザでは、日本語は、ほぼバラバラになるようです。
上記例では、「日本語Lucene」と「日本語Microsoft」が同じ結果になっていますが、この二つの違いも細かいところでは結構あります。どちらが良いというわけではありませんが、アナライザの性質を理解した上で設定していただくと良いと思います。
インデックスは、フィールドの追加はできますが、フィールド名の変更やアナライザの変更等はできません。JSONエディターがありますが、[analyzer]を変更して保存しようとしても [CannotChangeExistingField] とエラーメッセージが表示され変更できません。
このため、インデックスそのものを作り直すことにします。
まずは、インデックスの [JSONの編集]を開き、JSON定義内容をコピーしてテキストファイル等に保持します。その後、インデックス自体を削除してしまいます。
コピーしたインデックスの定義内容の [title](ファイル名が入るフィールド) と [chunk](本文が入るフィールド)の [analyzer] を "ja.microsoft" に変更します。
メニューから [インデックス] に入り、[+インデックスの追加] → [インデックスの追加(JSON)] を選択します。このメニューからは、JSON定義からインデックスを作ることができるので、先ほど編集した JSON定義を貼り付けます。(そのままでは構文エラーとなる場所がマークされていますが、そのあたりは削除してしまいます。)
[保存]ボタンをクリックすると、インデックスが作成できます。
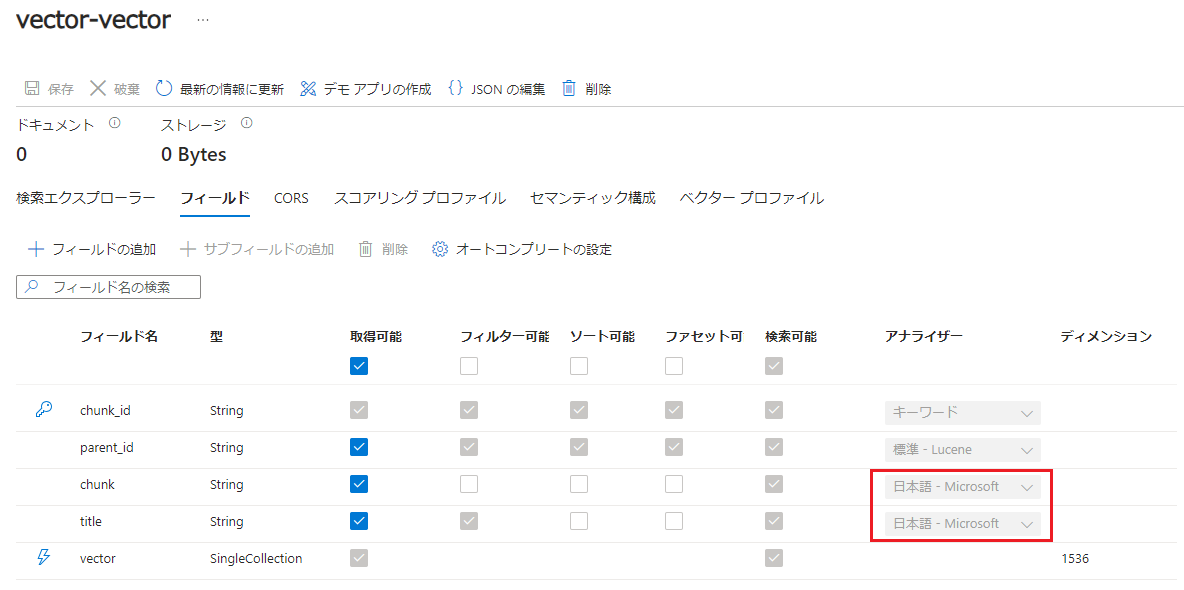
再作成したインデックスの [フィールド] を確認してみると、日本語アナライザーに変更されていることが確認できます。
続けて、スキルセットの言語設定も修正します。
[スキルセット] → [vector-blog-skillset](スキルセット名) を開き、[defaultLanguageCode] を "ja" に修正して、保存します。(こちらの対応は、先ほど紹介したQESブログの「Azure Cognitive Search でキーフレーズ抽出」と同じ対応をします。)
これで、定義の日本語化が完了しました。インデックスを再作成したため、データが失われています。インデクサーを再実行し、インデックスを再構築する必要があります。
[インデクサー] → [vector-blog-indexer](インデクサー名) を選択します。上部にある [リセット] をクリックし、続けて表示される確認ダイアログで [はい]を選択します。
インデクサーのリセットが完了後、[実行]をクリックし、続けて表示される確認ダイアログで [はい] を選択するとインデックスの再構築が始まります。
取り込むデータ量によりますが、取り込みに時間がかかりますので、インデクサーが完了するのを待ちます。
実行結果は、以下のようになります。
「Teamsはどのような記事がありますか?」と Teamsに関連する QESブログ記事を訪ねてみました。
Teamsの記事を訪ねてみると、実際に投稿されている記事が一覧表示されました。今回は特に指示していませんが、内容も要約してつけてくれました。
QESでは、「AIチャットボット構築サービス」をはじめとして、各AIサービスを利用したシステム導入のお手伝いをしております。それ以外でも QESでは様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
統合ベクトル化とは
統合ベクトル化は、データをインポートする際にチャンク分割やベクトル化もまとめて実施してくれる機能です。Azure Portalから利用できる機能であるため、ノーコードでデータを取り込んで検索したいという方には、便利な機能です。もともと取り込むだけの機能(「データのインポート」)はありましたが、さらにテキスト分割+ベクトル化がセットになったことでとても楽になりました。
データの取り込み
データの用意
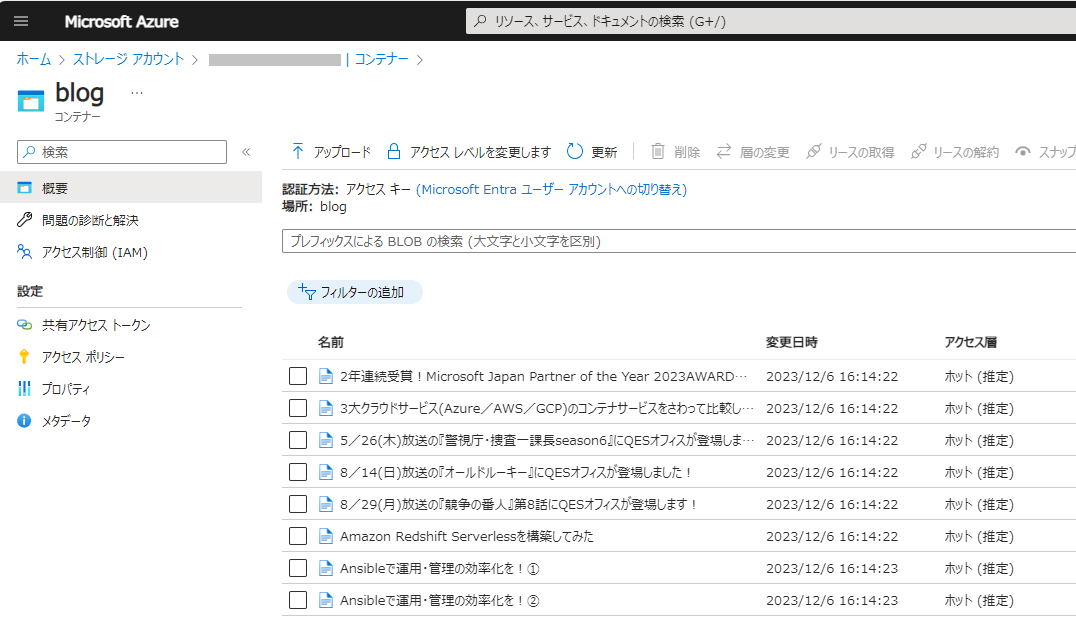
まずは、取り込むデータを用意します。データ格納用の Azure Storage Account を作成し、コンテナーを作成しておきます。作成したコンテナーに Azure AI Search に取り込みたいデータを格納します。今回の検証では、QESの技術ブログをスクレイピングしたテキストデータを用意しました。用意したテキストデータを Azure Storage に投入します。
今回はテキストデータを使用していますが、PDFファイルやOfficeファイルも取り込むことができます。
 |
データのインポートとベクター化
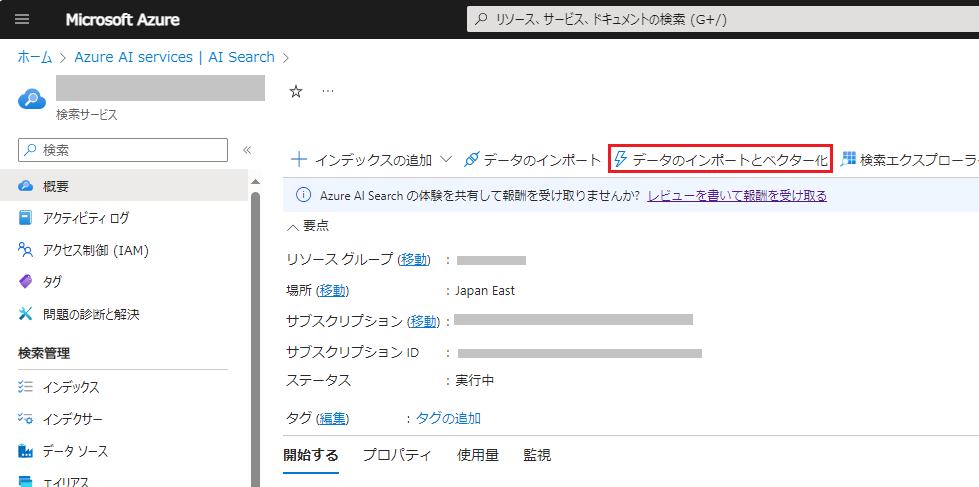
次に Azure AI Search の 検索サービスを選択し、「概要」ページを開きます。上部の「データのインポートとベクター化」をクリックします。
 |
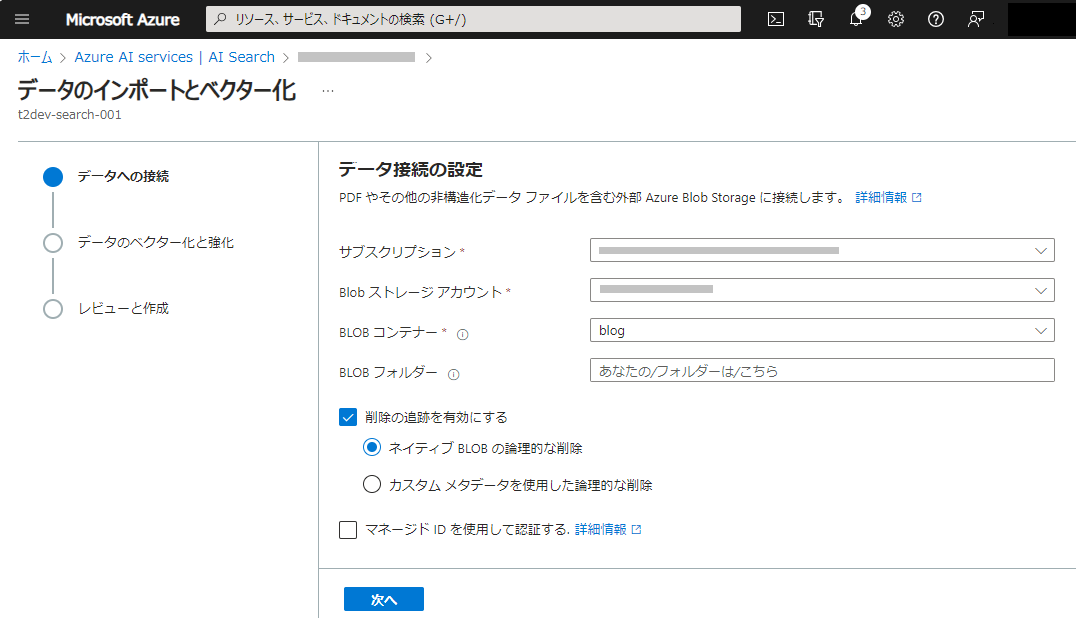
データを格納したストレージアカウントのコンテナーを指定します。
 |
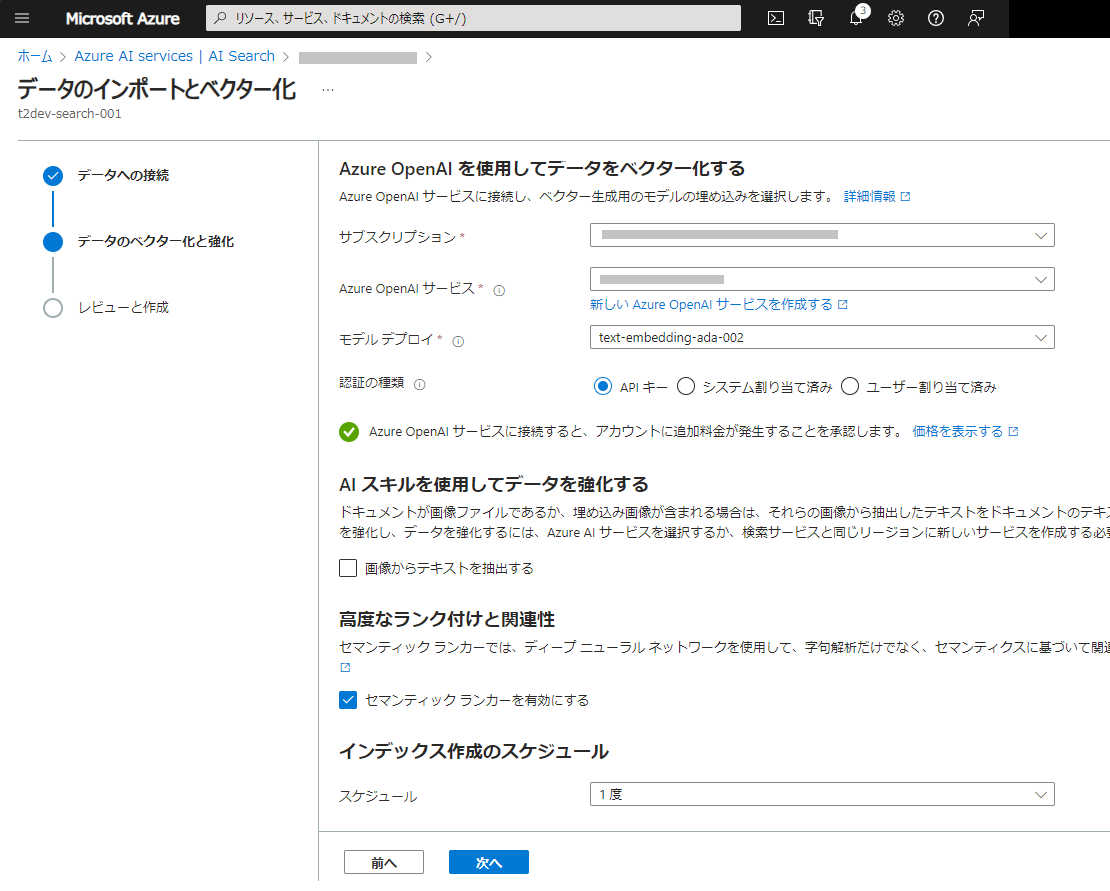
ベクトル化に必要な Azure OpenAI の設定を行います。デフォルトの状態ですが、セマンティックランカーも有効にします。AIスキルを使用すれば、画像データから文字を読み取ることもできるようですが、今回は読み込みデータがテキストなので使用しません。
 |
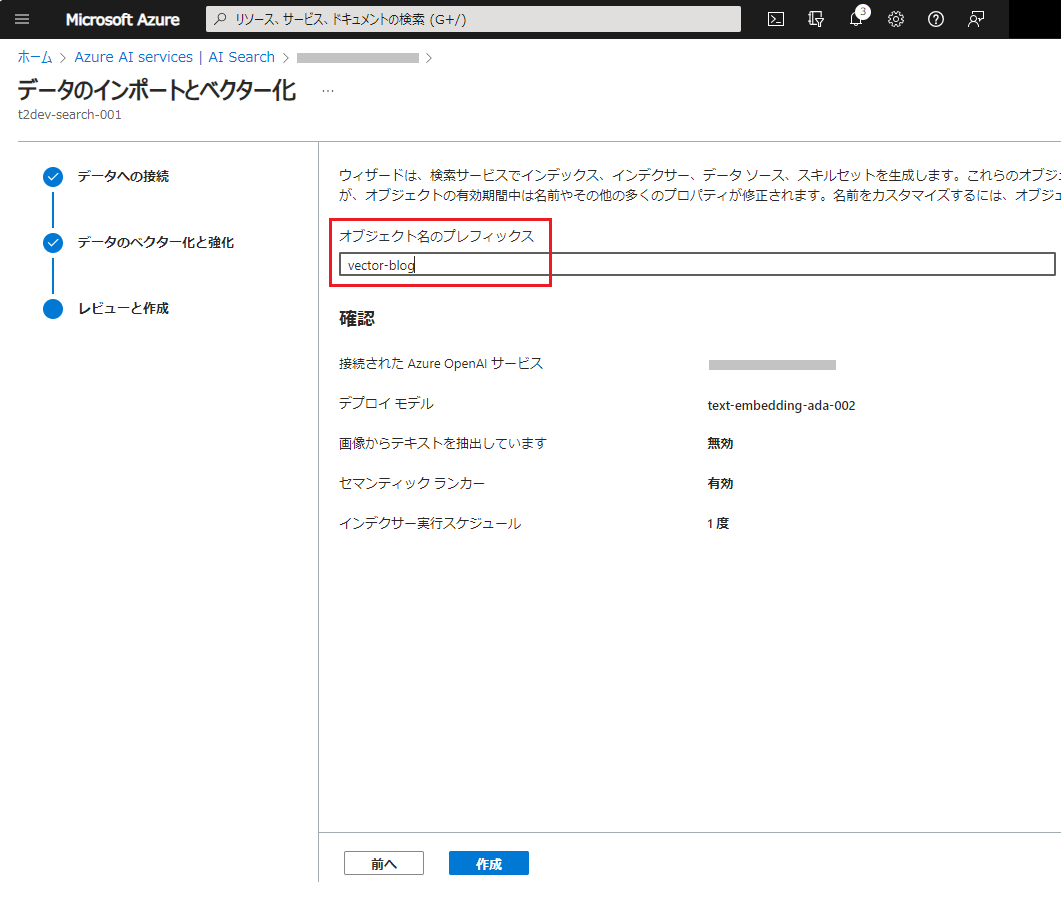
オブジェクトのプレフィックスは、[vector-xxxxxxxxxxx] のような名称が勝手につくので、分かりやすい名称に変えておきます。この名称がインデックス名になります。
 |
[作成]ボタンをクリック後、完了を待ちます。完了後、インデクサーが起動しますので、データの取り込みが完了するのを待ちます。データ量によりますが、インデクサーが状態が完了となるまで時間がかかります。
データが取り込まれると、[検索エクスプローラー]で検索できるようになります。[検索]ボタンを押してみます。
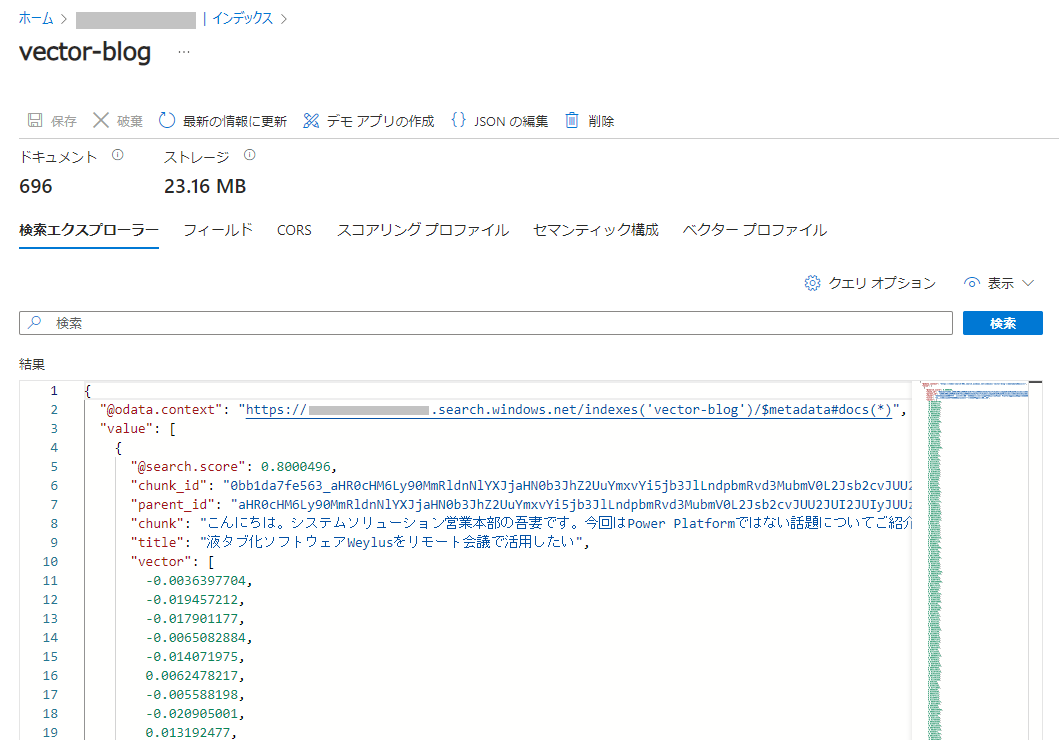 |
データが格納されているのが確認できました。"vector" にベクトル化された値も確認できます。
構成の確認
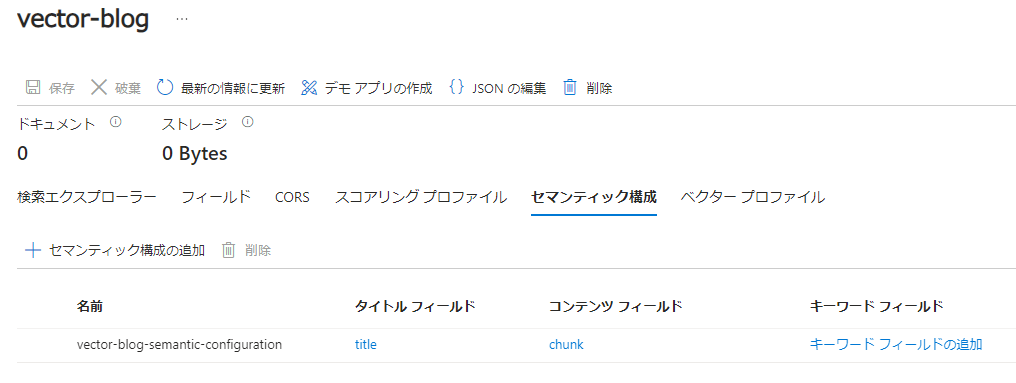
自動的に作成されたインデックスがどのような構成になっているか見てみます。インデックスの確認
インデックスの構造は、このようになっています。アナライザは、標準Luceneが設定されています。作成時に、セマンティックランカーを有効にしていますので、セマンティック構成も設定されています。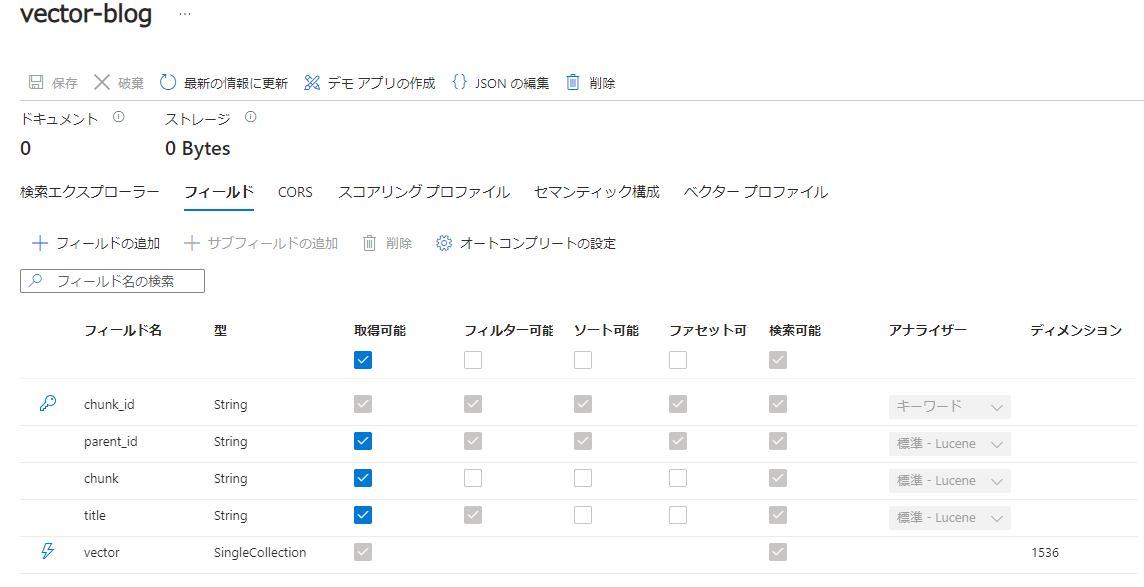 |
 |
スキルセットの確認
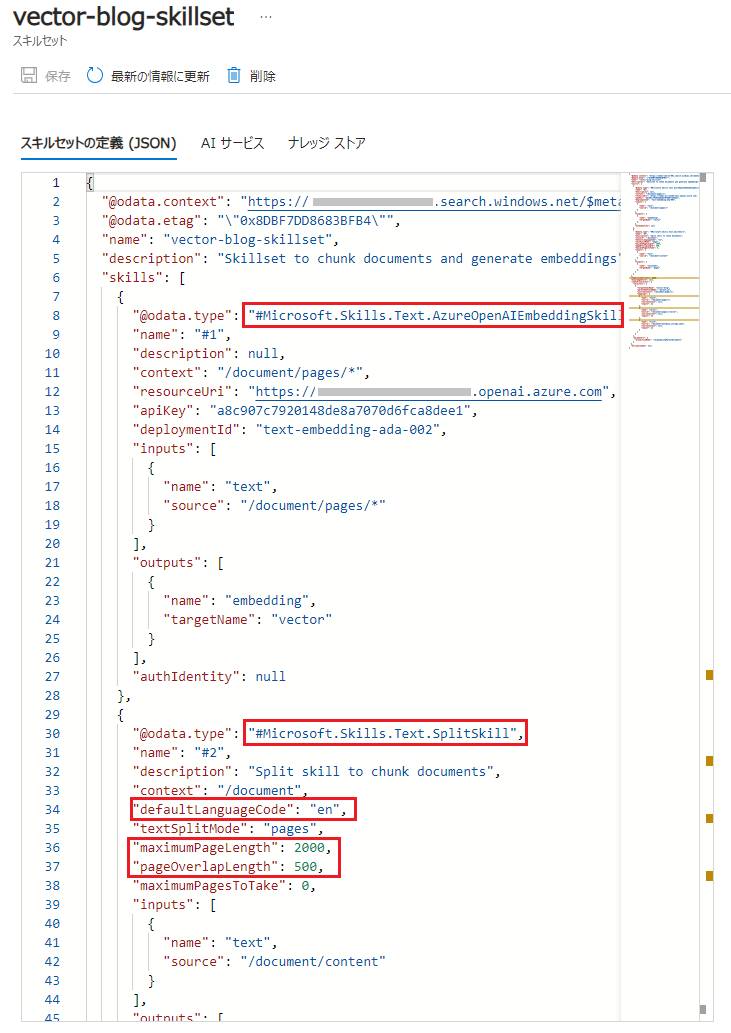
自動的に取込みのためのスキルセットも登録されています。内容を確認すると、 [Azure OpenAI Embedding スキル] と [テキスト分割スキル] が設定されていることが分かります。テキスト分割スキルの内容を確認すると、言語設定[defaultLanguageCode] が英語("en")になっていました。(これは、QESブログの「Azure Cognitive Search でキーフレーズ抽出」で紹介した言語設定の件と同じです)
テキストの分割サイズ[maximumPageLength]とオーバーラップサイズ[pageOverlapLength]も記載されていますので、こちらを修正すればテキスト分割サイズを調整できることが分かります。
 |
検索テスト
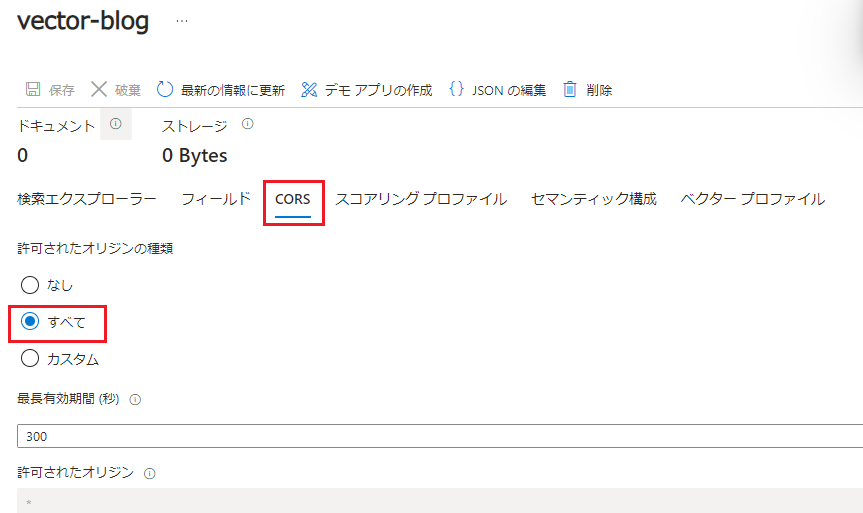
アナライザが標準Luceneのままでも利用できますが、日本語での検索に影響が出てきます。検索結果がどのように異なるか試してみます。検索のテストは、[Simple-Cognitive-Search-Tester] を使用させていただきました。インストール不要でブラウザで開くだけで、Azure AI Searchの検索を試せて検索結果も視覚的に分かりやすい便利なツールです。GitHubで公開されていますので、使用される場合は利用条件等ご確認のうえ、ご使用ください。
こちらのツールを使用する場合、CORSが許可されている必要があります。インデックス作成時は、既定で無効化されていますので、有効にします。([インデックス] → [vector-blog](インデックス名) → [CORS] →[すべて]を選択し、[保存])。
 |
例として、単純な全文検索で検索キーワードを「想定以上」として検索してみます。検索結果のハイライトされている箇所を見ても分かる通り、「想定以上」という検索で、仮想の「想」であったり、設定や指定の「定」がヒットしていることが分かります。
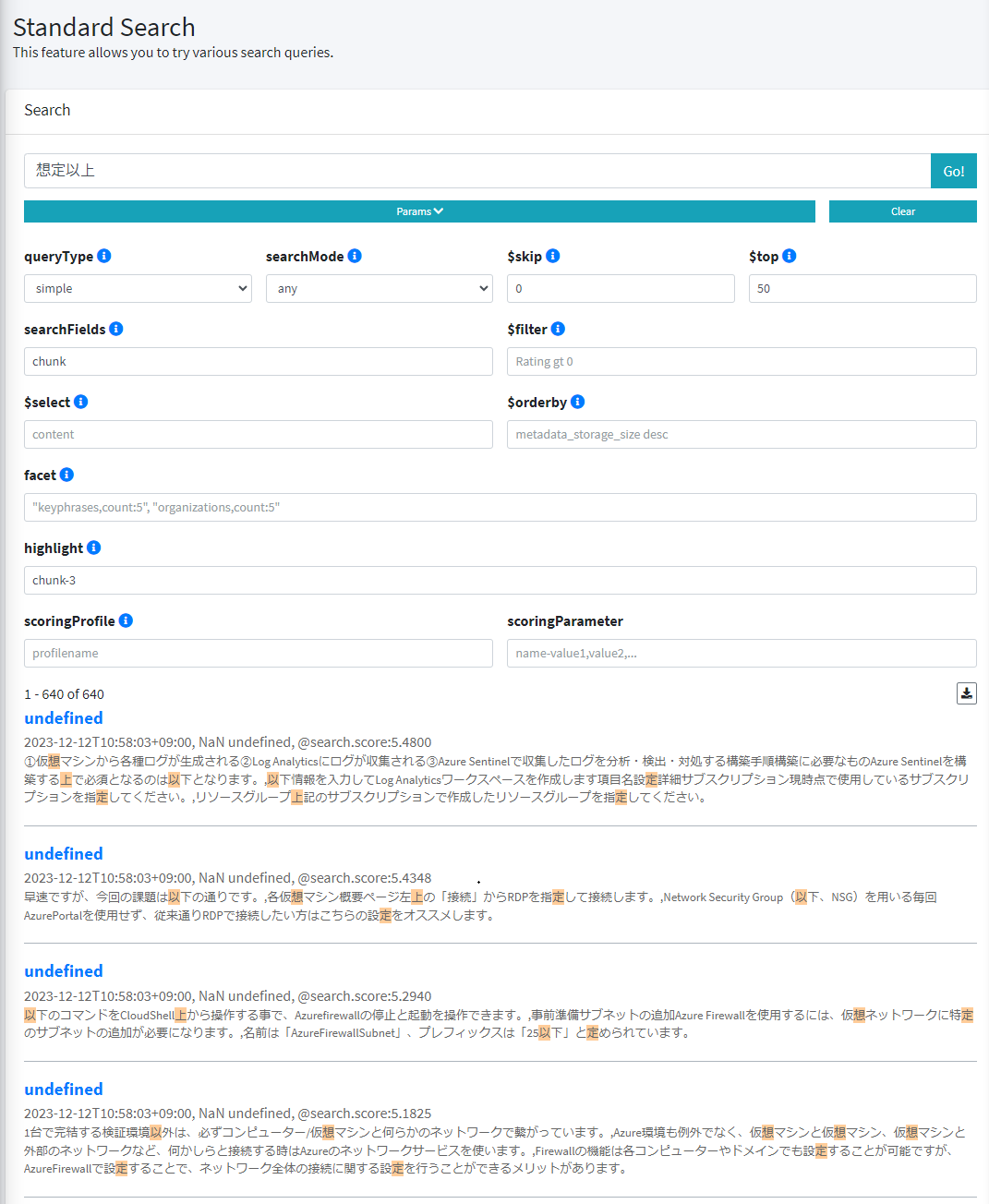 |
これは、「想定以上」というキーワードがアナライザにより、以下のようにトークン分割されることが影響します。どのような分割になるか試したい場合は、[Analyze API] の使用すると任意の文字列でトークン分割を確認できます。
| No | アナライザ | トークン分割 |
| 1 | 標準Lucene (standard.lucene) |
想、定、以、上 |
| 2 | 日本語Lucene (ja.lucene) |
想定、以上 |
| 3 | 日本語Microsoft (ja.microsoft) |
想定、以上 |
標準アナライザでは、日本語は、ほぼバラバラになるようです。
上記例では、「日本語Lucene」と「日本語Microsoft」が同じ結果になっていますが、この二つの違いも細かいところでは結構あります。どちらが良いというわけではありませんが、アナライザの性質を理解した上で設定していただくと良いと思います。
日本語対応
標準Luceneのままでは、狙っていないキーワードが上位に来てしまうなど検索結果に影響が出る可能性があることが分かりましたので、言語設定を変更してみます。インデックスは、フィールドの追加はできますが、フィールド名の変更やアナライザの変更等はできません。JSONエディターがありますが、[analyzer]を変更して保存しようとしても [CannotChangeExistingField] とエラーメッセージが表示され変更できません。
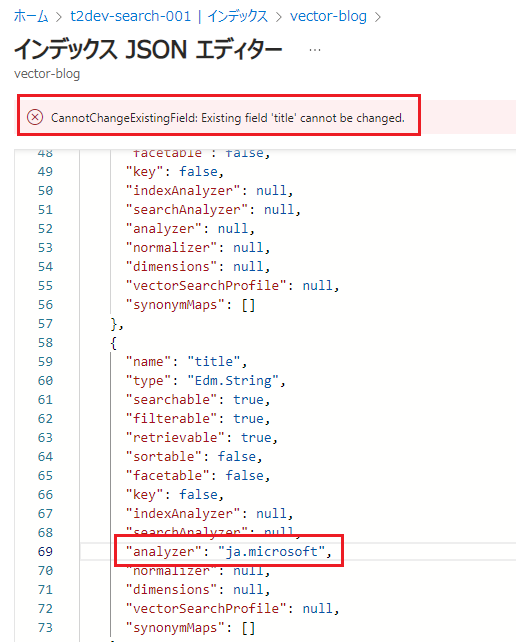 |
このため、インデックスそのものを作り直すことにします。
まずは、インデックスの [JSONの編集]を開き、JSON定義内容をコピーしてテキストファイル等に保持します。その後、インデックス自体を削除してしまいます。
 |
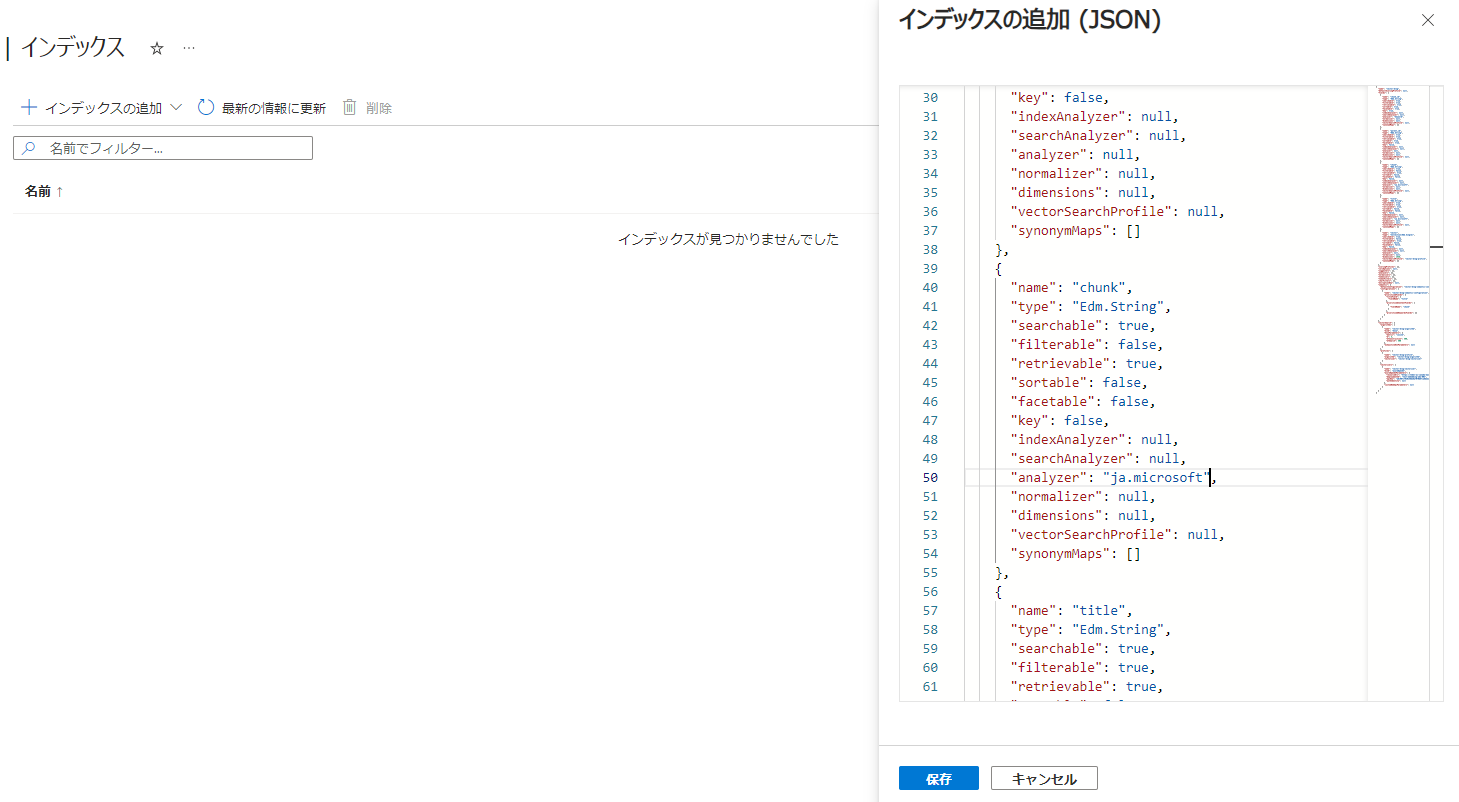
コピーしたインデックスの定義内容の [title](ファイル名が入るフィールド) と [chunk](本文が入るフィールド)の [analyzer] を "ja.microsoft" に変更します。
メニューから [インデックス] に入り、[+インデックスの追加] → [インデックスの追加(JSON)] を選択します。このメニューからは、JSON定義からインデックスを作ることができるので、先ほど編集した JSON定義を貼り付けます。(そのままでは構文エラーとなる場所がマークされていますが、そのあたりは削除してしまいます。)
[保存]ボタンをクリックすると、インデックスが作成できます。
 |
再作成したインデックスの [フィールド] を確認してみると、日本語アナライザーに変更されていることが確認できます。
続けて、スキルセットの言語設定も修正します。
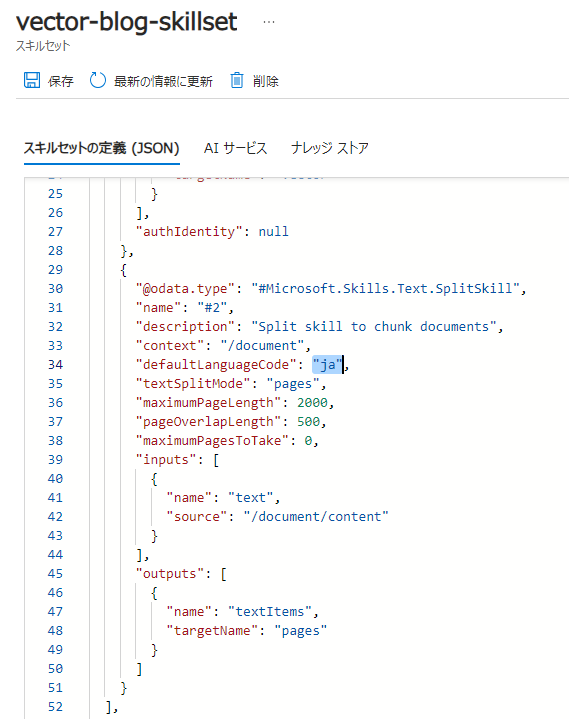
[スキルセット] → [vector-blog-skillset](スキルセット名) を開き、[defaultLanguageCode] を "ja" に修正して、保存します。(こちらの対応は、先ほど紹介したQESブログの「Azure Cognitive Search でキーフレーズ抽出」と同じ対応をします。)
 |
これで、定義の日本語化が完了しました。インデックスを再作成したため、データが失われています。インデクサーを再実行し、インデックスを再構築する必要があります。
[インデクサー] → [vector-blog-indexer](インデクサー名) を選択します。上部にある [リセット] をクリックし、続けて表示される確認ダイアログで [はい]を選択します。
 |
インデクサーのリセットが完了後、[実行]をクリックし、続けて表示される確認ダイアログで [はい] を選択するとインデックスの再構築が始まります。
 |
取り込むデータ量によりますが、取り込みに時間がかかりますので、インデクサーが完了するのを待ちます。
検索テスト(アナライザー変更後)
アナライザーが変更されたか検索ツールで検索すると、今回は「想定」と「以上」というキーワードで検索できていることが確認できました。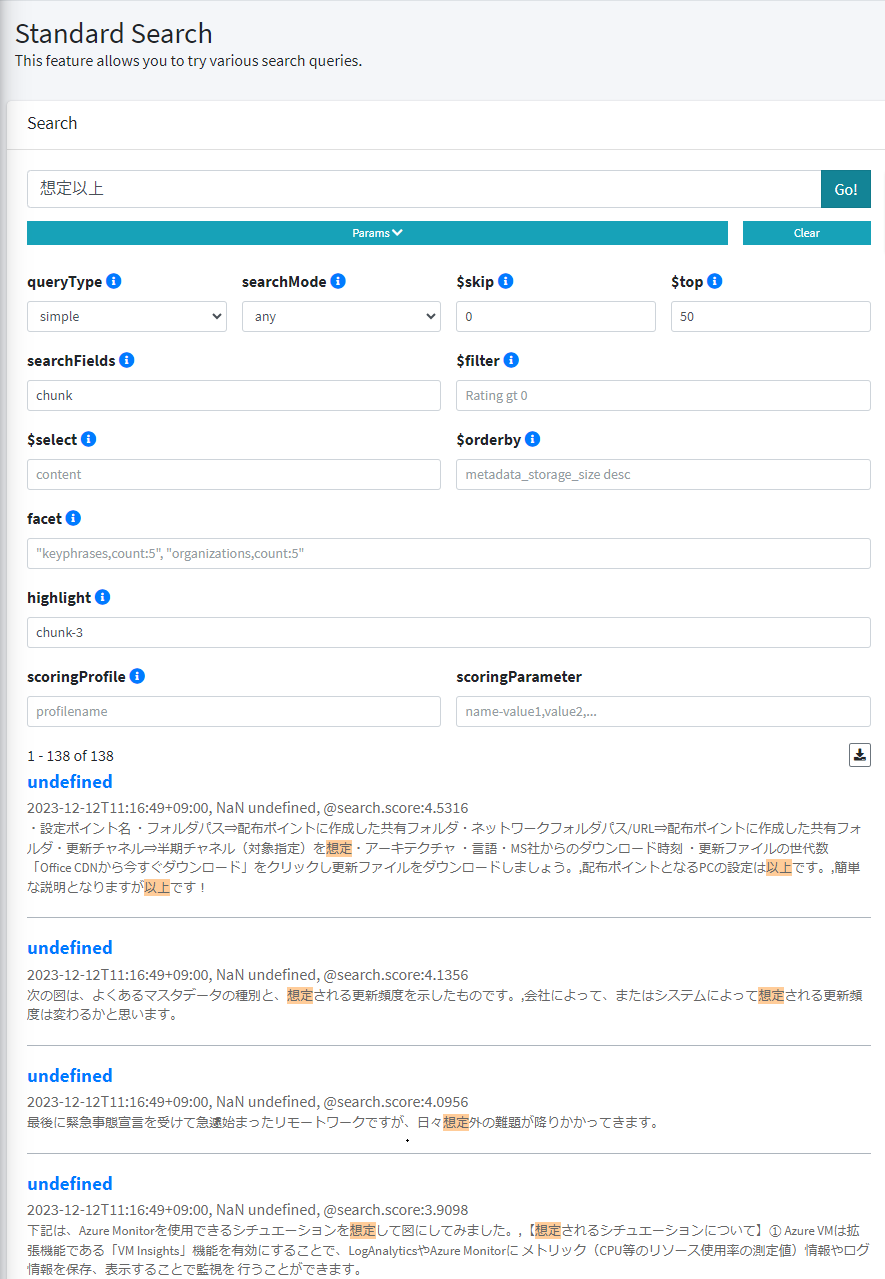 |
簡易RAG構成の構築
Azure AI Search での検索は、問題無さそうですので、質問に対して回答する 簡易的なRAGシステムのようなものを構築してみます。
(参考)Azure AI Search での取得拡張生成 (RAG)
RAG構成の基本的な処理の流れは、以下になります。
① ユーザーからの質問に対して、Azure AI Searchを検索します。
② 検索結果上位の情報とユーザーからの質問を GPTに連携し回答文を作成してもらいます。
③ 作成された回答文をユーザーに応答します。
Azure AI Seach 検索の処理
Search処理部分のサンプルコードです。ハイブリッド検索の構成となっているため、質問文をベクトル化するため、OpenAIを使用した Embedding処理も含まれています。import os
from openai import AzureOpenAI
from azure.search.documents import SearchClient
from azure.search.documents.models import VectorizedQuery
from azure.core.credentials import AzureKeyCredential
# デプロイ名
deployment_id_chat = "gpt-4"
deployment_id_embedding = "text-embedding-ada-002"
client = AzureOpenAI(
api_key=os.environ['OPENAI_API_KEY'],
api_version="2023-12-01-preview",
azure_endpoint=os.environ['OPENAI_API_BASE']
)
# Azure AI Seach関連
search_index_name = "vector-blog"
semantic_configuration_name = search_index_name + "_semantic-configuration"
service_endpoint = os.environ['SEARCH_ENDPOINT']
search_api_key = os.environ['SEARCH_API_KEY']
credential = AzureKeyCredential(search_api_key)
search_client = SearchClient(
service_endpoint,
search_index_name,
credential=credential
)
# ベクトルの生成
def generate_embedding(question):
response = client.embeddings.create(
input=question,
model=deployment_id_embedding
)
embeddings = response.data[0].embedding
return embeddings
# Searchの検索
def search(question):
# AI Searchを検索する
results = search_client.search(
search_text=question,
search_mode="any",
search_fields=["chunk"],
select=["title", "chunk"],
semantic_configuration_name=semantic_configuration_name,
top=10,
vector_queries=[
VectorizedQuery(
kind = "vector",
vector = generate_embedding(question),
k_nearest_neighbors = 10,
fields = "vector"
)
]
)
return results
LLM(Azure OpenAI)連携部分の処理
問い合わせ部分のサンプルコードは、以下になります。先ほどの検索部分の結果とユーザーからの質問文を渡し、回答を生成してもらいます。def ask_question(question):
# Azure AI Searchを検索する
results = search(question)
# 応答データを取得する
input_data = []
for result in results:
# 回答作成用の情報に
input_data.append(f"タイトル:{result['title']}\n")
input_data.append(f"本文:{result['chunk']}\n\n")
# GPTに回答をリクエスト
system_message = '''
- 以下に記載する技術ブログの内容をもとに、ユーザーからの質問に回答してください。
-
- ■技術ブログ
'''
for input in input_data:
system_message = f"{system_message}{input}\n\n"
messages = [{"role": "system", "content": system_message}]
messages.append({"role": "user", "content": question})
chat_response = client.chat.completions.create(
model = deployment_id_chat,
messages = messages,
temperature = 0.5
)
assistant_message = chat_response.choices[0].message
if assistant_message.content:
messages.append({"role": assistant_message.role, "content": assistant_message.content})
return messages
実行結果は、以下のようになります。
「Teamsはどのような記事がありますか?」と Teamsに関連する QESブログ記事を訪ねてみました。
 |
まとめ
いかがでしょうか。Azure AI Searchへのデータ取込みが簡単にできるようになり、QAシステム構築のハードルが下がりました。既存の PDFファイルや Officeファイルを取り込むだけで、ハイブリッド+セマンティックランカーの Search構成が作れますので、チャットボット等のQAシステムを構築しやすくなったと思います。QESでは、「AIチャットボット構築サービス」をはじめとして、各AIサービスを利用したシステム導入のお手伝いをしております。それ以外でも QESでは様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
※このブログで参照されている、Microsoft、Azure、Azure OpenAI、Teams、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
※その他の会社名、製品名は各社の登録商標または商標です。

