記事公開日
【AWS re:Invent 2025】セッションレポート(Chalk talk): From prototype to production: Scaling agents with Amazon S3 Vectors (STG363-R1) に参加しました

AWS re:invent 2025 は現地参加しています。
「From prototype to production: Scaling agents with Amazon S3 Vectors」に参加したのでレポートします。
Chalk talkで一部聞き取れなかった部分もありますがご了承ください。
セッション概要

・セッション ID: STG363-R1
・タイトル: From prototype to production: Scaling agents with Amazon S3 Vectors ・スピーカー
Chris Burgess, Sr. SDE, AWS
Venkata Sistla, Sr. Worldwide Specialist SA - AI/ML, Amazon Web Services
・レベル: 300 - Advanced
Break through the scaling barriers that keep agentic AI in prototype mode. With Amazon S3 Vectors now generally available, build production-ready AI agents operating at enterprise scale with up to 1 billion vectors per index and sub-second performance. Explore how S3 Vectors serves as the foundation for agentic AI, supporting continual learning, historical context retention, retraining, and fine-tuning for deeper agent intelligence. Discover practical integration patterns with Amazon Bedrock, Amazon SageMaker, and other services while learning resilient multi-agent system architectures and enterprise-scale RAG implementations. Join us for live architecture walkthroughs and actionable insights to transform prototypes into production-grade intelligent systems.
Google翻訳
エージェントAIをプロトタイプモードにとどめているスケーリングの障壁を打ち破りましょう。Amazon S3 Vectorsの一般提供が開始され、インデックスあたり最大10億のベクトルと1秒未満のパフォーマンスを備えた、エンタープライズ規模で稼働する本番環境対応のAIエージェントを構築できます。S3 VectorsがエージェントAIの基盤としてどのように機能し、継続的な学習、履歴コンテキストの保持、再トレーニング、そしてより深いエージェントインテリジェンスのための微調整をサポートするのかをご覧ください。Amazon Bedrock、Amazon SageMaker、その他のサービスとの実用的な統合パターンを発見しながら、耐障害性の高いマルチエージェントシステムアーキテクチャとエンタープライズ規模のRAG実装を学びましょう。ライブアーキテクチャウォークスルーと実用的なインサイトに参加して、プロトタイプを本番環境レベルのインテリジェントシステムに変換しましょう。
現在、多くの組織が生成AIのプロトタイプ作成(PoC)から本番環境への移行という「キャズム(深い溝)」に直面しています。このキャズムを乗り越えるための鍵として、AWSは2つの革新的な技術パラダイムを提示しました。
一つは、インフラストラクチャ層における「Amazon S3 Vectors」によるベクトルストレージの再定義であり、もう一つは、アプリケーション層における「Strands Agents SDK」による自律型エージェント開発の民主化です。
Amazon S3 Vectorsは、クラウドオブジェクトストレージであるAmazon S3にベクトル検索機能をネイティブに統合することで、従来の専用ベクトルデータベースと比較してコストを最大90%削減しつつ、数十億規模のベクトルデータを扱うスケーラビリティを実現しました。これは、RAG(Retrieval-Augmented Generation)やエージェントの長期記憶(Long-term Memory)におけるストレージの経済性を根本から変えるものです。
一方、Strands Agents SDKは、従来のコード記述量の多いオーケストレーション手法から、LLM(大規模言語モデル)の推論能力を最大限に活用する「モデル駆動型(Model-Driven)」のアプローチへの転換を促進します。Model Context Protocol (MCP) のネイティブサポートや、AWSエコシステムとの密接な統合により、開発者は複雑なエージェントワークフローを効率的に構築可能となります。
本レポートでは、これらの技術的詳細、アーキテクチャパターン、統合戦略、および実際のユースケース(ビデオ分析、プライベートアシスタント等)についてご説明します。エージェントが単なるチャットボットを超え、企業のデータを活用して自律的に計画・実行する「Agentic AI」の時代において、これらの技術がどのように統合され、実用的なビジネス価値を生み出すのかを明らかにしていきます。
セッションアジェンダ

セッション内容
1. イントロダクション:Agentic AIと本番環境へのキャズム
1.1 Agentic AIの台頭と現状
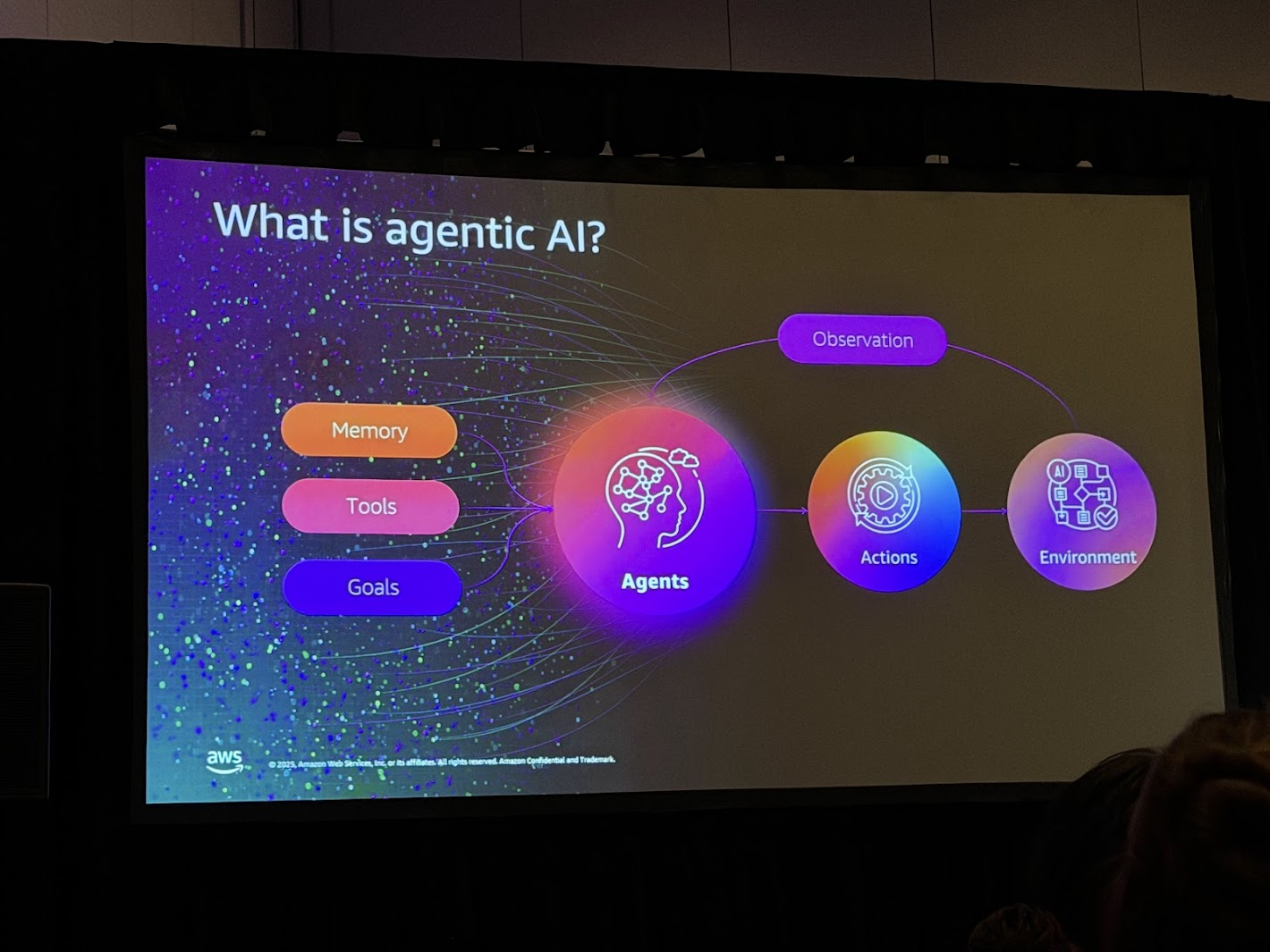
AWS re:Inventにおいて繰り返し強調されたテーマの一つが「Agentic AI(自律型AIエージェント)」の台頭です。従来の大規模言語モデル(LLM)を用いたチャットボットは、ユーザーからの質問に対して受動的に応答する存在でした。これに対し、Agentic AIは、より能動的かつ自律的な振る舞いを見せます。Chalk TalkのスピーカーであるVenkata Sistla氏(Sr. WW Specialist SA - AI/ML)は、エージェントを「自律的に行動(Act)、計画(Plan)、実行(Execute)できる存在」と定義していました。
エージェントは単にテキストを生成するだけでなく、ビジネスの成果(Business Outcomes)を達成するために、業務オペレーションを最適化し、リアルタイムでの意思決定を行う能力が求められています。しかし、現状では多くの組織がペタバイト規模のデータを保有していながら、エージェントがそれらを効果的に活用できていないという課題があります。ログデータ、製品ドキュメント、社内Wiki、長年のトランザクション履歴など、企業がこれまで多大な投資をして保存・保護してきたデータ資産と、エージェントが実際にアクセスできる情報の間に「決定的なギャップ」が存在しているのです。

AIエージェントフレームワークの全体像。デプロイ方法もAmazon Q Agents、Amazon Bedrock Agents、OSSと選択肢が広がっています。
1.2 プロトタイプからプロダクションへの「キャズム」
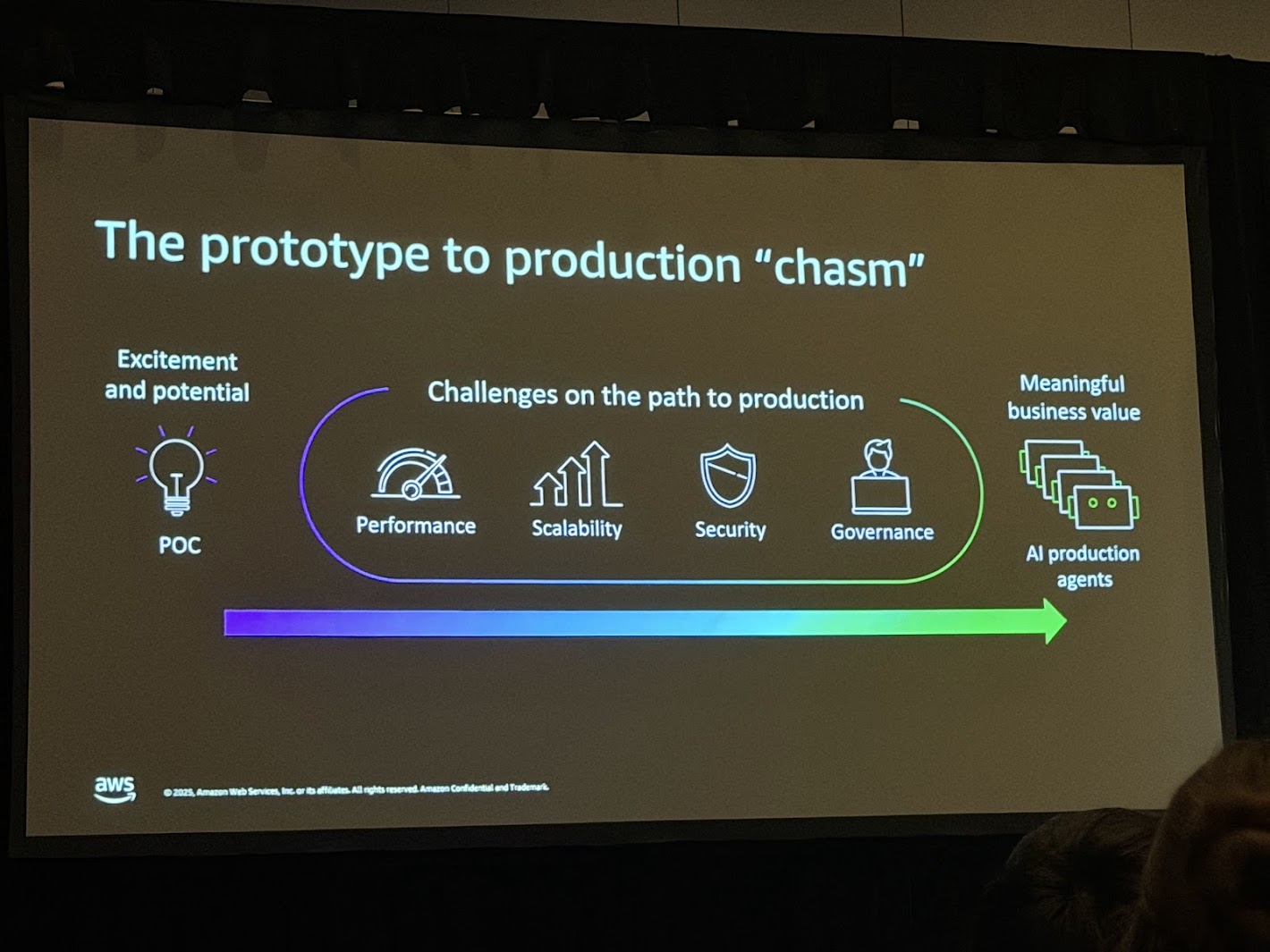
多くの企業が生成AIに可能性を感じ概念実証(PoC)に取り組んでいます。しかし、PoCの成果物を実際にビジネス価値を生み出す本番環境(Production)へと移行させる段階で、多くのプロジェクトが停滞または失敗しています。これをChalk Talkでは「The prototype to production "chasm"(プロトタイプからプロダクションへのキャズム)」と表現しています。
このキャズムを構成する主な障壁は以下の4点です:
- Performance(パフォーマンス): 単一のユーザーに対する応答速度だけでなく、同時多数のアクセスに対するレイテンシやスループットの維持。特に、エージェントが複雑な推論(Reasoning)やツール呼び出しを行う場合、応答時間が数秒から数十秒に及ぶことがあり、ユーザー体験(UX)を著しく損なう要因となる。
- Scalability(スケーラビリティ): データ量の増加に伴う検索精度の維持とコストの抑制。PoC段階では数千件のドキュメントで済んでいたものが、本番環境では数億、数十億のベクトルデータを扱う必要が出てくる。既存のインメモリ型ベクトルデータベースでは、この規模においてコストが指数関数的に増大するリスクがある。
- Security(セキュリティ): 企業データの保護。エージェントが自律的にデータにアクセスする場合、どのデータにアクセスして良いか、誰の権限で実行するかというアクセス制御(RBAC)や、データの暗号化、プライバシー保護が不可欠となる。
- Governance(ガバナンス): エージェントの挙動の追跡と制御。自律的に判断するエージェントが予期せぬ行動をとった場合、その原因を特定し(Observability)、修正するためのメカニズムが必要である。また、幻覚(Hallucination)のリスク管理もここに含まれる。
これらの課題を克服し、真のビジネス価値(Meaningful business value)を創出するためには、単にモデルの性能を上げるだけでなく、それを支えるインフラストラクチャとアーキテクチャの根本的な見直しが必要となる。本レポートで詳述するAmazon S3 VectorsとStrands Agentsは、まさにこのキャズムを架橋するために設計されたソリューションです。
4つの障壁で一番ネックになるのは2.スケーラビリティのコストではないでしょうか?
以前、OpenSearchでSIEMを構築したことがありましたが、本番環境で取り込むログが増大すると費用対効果が全く見合わなくなった、という経験があります。
2. エージェント開発のアプローチ:Managed vs Custom (Strands Agents)
2.1 マネージドエージェント vs カスタムエージェント
マネージドエージェント (Amazon Bedrock Agents)
AWSが提供するAmazon Bedrock Agentsは、インフラ管理の複雑さを抽象化し、エージェントの構築、デプロイ、スケーリングを迅速に行うためのフルマネージドサービスです。
- 利点: サーバーレスであり、インフラのプロビジョニングが不要。AWSのセキュリティ基準に準拠したガードレールや、Knowledge Basesとのシームレスな統合が提供される。運用負荷(Undifferentiated heavy lifting)を大幅に削減できる。
- 適用領域: 標準的なRAGワークフローや、特定のAWSサービスとの連携が主となるユースケースに適している。
カスタムエージェント (DIY with Frameworks)
一方、より高度な柔軟性や特定のモデル、独自の推論ロジックが必要な場合は、オープンソースフレームワークを利用したカスタム構築が選択される。ここで注目されるのが、AWSがオープンソースとして公開し、大きな話題となっている「Strands Agents SDK」です。
- 利点: 任意のLLM(Bedrock上のモデルだけでなく、OpenAIやAnthropic、ローカルLLMなど)を選択可能。推論ループやツール使用のロジックを細かく制御できる。
- 適用領域: 複雑なマルチエージェント協調、独自のメモリ管理、特殊なツール統合が必要な高度なアプリケーションに適している。
2.2 Strands Agents SDKの詳細分析
Strands Agentsは、従来のフレームワーク(LangChainの初期バージョンなど)で見られた複雑な抽象化を避け、LLMのネイティブな能力を最大限に活かす「Model-driven(モデル駆動型)」のアプローチを採用している点が革新的です。
モデル駆動型アーキテクチャ (Model-Driven Approach)
従来のエージェント開発(Code-driven)では、開発者が詳細なフローチャートや条件分岐(if-thenルール)をコードで記述する必要がありました。これに対し、Strands Agentsでは「モデル、プロンプト、ツール」の3要素を定義するだけで、あとはモデル自身が状況に応じて計画(Plan)し、ツールを選択し、実行します。
このアプローチにより「数ヶ月かかっていたエージェント開発が数日、あるいは数行のコードで実現できる」と強調しています。
The Agentic Loop (エージェントループ)
Strands Agentsの中核には、自律的な思考と行動のループが存在します。
- Observe (観察): ユーザーの入力や環境の状態を受け取る。
- Think (思考): モデルがReAct(Reasoning + Acting)パターンなどを用いて、目標達成のための計画を立てる。
- Act (行動): 適切なツール(API呼び出し、検索、計算など)を実行する。
- Reflect (内省): ツールの実行結果を評価し、目標が達成されたかを判断する。未達成であれば、修正計画を立ててループを継続する。
このループ構造により、エージェントは一度の指示で完結しない複雑なタスク(例:「このドキュメントを読んで、関連する画像を検索し、レポートにまとめてメールで送って」)を遂行できます。
Model Context Protocol (MCP) のネイティブサポート
Strands Agentsの特筆すべき点は、Anthropicらが提唱するオープン標準「Model Context Protocol (MCP)」をネイティブにサポートしていることです。MCPは、AIモデルがデータソースやツールと接続するための標準化されたインターフェース(USBのような規格)を目指しています。
- 意義: これまで、各データソース(Google Drive, Slack, GitHub, 独自DBなど)ごとに個別のコネクタを開発する必要があったが、MCPサーバーとして実装されたツールであれば、Strands Agentsから即座に利用可能となる。
- 実例: Aurora DSQL(分散SQLデータベース)のMCPサーバーを使用し、エージェントが自然言語でデータベース操作を行う。これにより、開発者はSQLクエリを記述することなく、データベースと対話するエージェントを構築できる。
3. エージェントの認知アーキテクチャとメモリの役割
エージェントが高度なタスクを遂行するためには、単なる計算能力だけでなく、「記憶(Memory)」が不可欠です。Chalk Talkのアジェンダにも「Memory」が含まれており、特に長期記憶の実装が議論の焦点となりました。
3.1 短期記憶 (Short-term Memory) と長期記憶 (Long-term Memory)マネージドエージェント vs カスタムエージェント
人間の認知モデルと同様に、AIエージェントにも二種類のメモリが必要とされる。
- 短期記憶 (Short-term Memory / Working Memory):
- 役割: 現在のセッション内での会話履歴や、直前の思考プロセスを保持する。
- 要件: 高速な読み書き(低レイテンシ)が必要。
- 実装技術: 通常はコンテキストウィンドウ(LLMの入力トークン制限内)に保持されるが、容量に限界があるため、RedisやDynamoDBなどの高速なKVS(Key-Value Store)が補助的に利用されることが多い。
- 長期記憶 (Long-term Memory / Episodic & Semantic Memory):
- 役割: セッションを超えて永続的に保持される知識や経験。過去の全ての対話ログ、ユーザーの嗜好、学習した事実などが含まれる。
- 要件: 大容量のスケーラビリティと、意味的な検索(Semantic Search)能力が必要。
- 実装技術: ここではベクトルデータベースが重要な役割を果たします。過去の膨大なログをベクトル化して保存し、現在の状況に関連する情報だけを検索して取り出す(Retrieve)ことで、エージェントに「無限の記憶」を持たせることができます。
3.2 メモリの永続化とスケーリングの課題
従来、長期記憶の実装にはPineconeやWeaviate、OpenSearchなどのベクトルデータベースが利用されてきた。しかし、これらは基本的にコンピュートリソース(CPU/メモリ)を常時稼働させる必要があり、データ量が増加するとコストが指数関数的に増大するという課題がありました。
「数年分のカスタマーサポートログ」や「全社員の数年分のチャット履歴」といったペタバイト級のデータをすべてベクトル化して保持しようとすると、インフラコストが現実的ではなくなる。これが、前述の「プロトタイプからプロダクションへのキャズム」におけるScalabilityの壁となっていました。
この課題に対するAWSの回答が、次章で詳述する「Amazon S3 Vectors」です。
4. Amazon S3 Vectors:アーキテクチャと技術的深層
Amazon S3 Vectorsは、re:Invent 2025の期間中に一般提供(GA)が開始された、クラウドストレージのパラダイムシフトとも言える新機能です。世界初のネイティブベクトルサポートを持つクラウドオブジェクトストアです。
4.1 S3 Vectorsの基本概念とアーキテクチャ
Chalk Talkにおいて、AWSのSr. Software Development EngineerであるChris Burgess氏は、S3 Vectorsの技術的な詳細について解説を行った。S3 Vectorsは、S3の持つ「耐久性(Durability)」「可用性(Availability)」「無限のスケーラビリティ」という特性をそのままベクトルストレージに適用したものです。
4.1.1 Vector Bucket (ベクトルバケット)
S3 Vectorsを使用するためには、通常のS3バケットとは異なる「Vector Bucket」と呼ばれる新しい種類のバケットを使用します。
- ネイティブ統合: ユーザーはベクトルデータ(embedding)とそれに関連するメタデータをS3にPUTするだけで構いません。バックグラウンドでAWSが自動的にインデックス化処理を行います。ユーザーはインデックスの構築、シャーディング、リバランス、パッチ適用といったデータベース管理業務から完全に解放されます。
- スケーラビリティ: 1つのインデックスあたり最大20億(2 Billion)のベクトルをサポートし、バケット全体では最大20兆(20 Trillion)という途方もない規模のベクトルを保存可能です。これは、実質的にあらゆるエンタープライズのデータ需要を満たす容量です。
4.1.2 パフォーマンス特性:レイテンシ vs コスト
S3 Vectorsの設計思想は明確なトレードオフに基づいています。「超低遅延(マイクロ秒〜数ミリ秒)」を犠牲にする代わりに、「圧倒的な低コスト」と「運用レス」を提供する点です。
- レイテンシー: クエリの応答時間は「サブセカンド(Sub-second)」、具体的には数百ミリ秒(100ms〜)程度とされます。これはインメモリ型の専用ベクトルDBと比較すれば遅いが、生成AIアプリケーション(RAG)においては、LLMの生成に数秒かかることが一般的であるため、エンドツーエンドの体験において100msの検索時間は許容範囲内である場合が多い。
- コスト効率: 専用データベースと比較して、コストを最大90%削減できるとされます。これは、高価なSSDやRAMではなく、安価なオブジェクトストレージにデータを配置し、クエリ時のみコンピュートリソースを消費するアーキテクチャによるものである。
4.1.3 APIと操作
S3 Vectorsは、S3の標準的な操作体系を拡張する形でAPIを提供する。
- PutVector: ベクトルデータとメタデータの登録。
- GetVector: キーによるベクトルの取得。
- DeleteVector: ベクトルの削除。
- QueryVector: ベクトルによる類似性検索(k-NN検索)。
- UpdateVector(将来的なロードマップとしての言及も示唆されるが、基本はPUTによる上書き)。
4.2 統合パターン:OpenSearch Serviceとの連携
S3 Vectorsは単独でも利用可能だが、より高度な検索要件に対応するために、Amazon OpenSearch Serviceとの深い統合機能が提供されています。Chalk Talkでは、以下の2つの主要な統合パターンが提示されました。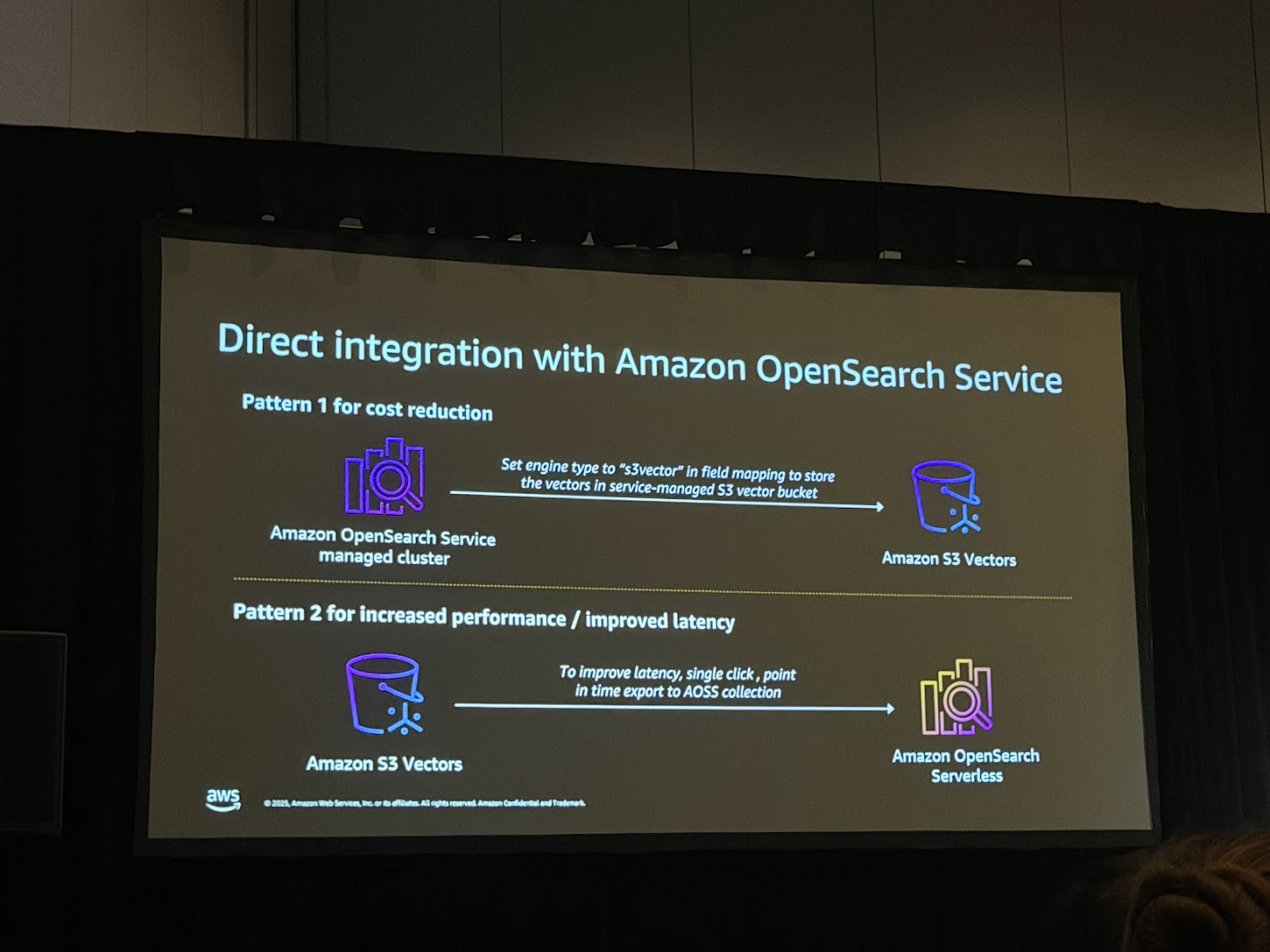
パターン1:コスト削減のための統合 (Managed Cluster Integration)
このパターンでは、OpenSearch Serviceのマネージドクラスタ(OR1インスタンスなど)を使用し、そのバックエンドストレージとしてS3 Vectorsを指定します。
- 仕組み: ユーザーはOpenSearchのエンドポイントに対して標準的なAPIでクエリを投げる。OpenSearchはクエリを受け取り、S3 Vectors上のインデックスに対して検索を実行する。
- メリット: OpenSearchの豊富な機能(ハイブリッド検索、複雑なフィルタリング、アグリゲーション)を利用しつつ、データの実体を安価なS3に置くことでストレージコストを劇的に削減できる。
- 適用シナリオ: アクセス頻度がそれほど高くない「コールド」または「ウォーム」なデータセット、アーカイブデータの検索、コスト重視の大規模ナレッジベース。
パターン2:パフォーマンス向上のための統合 (Export to Serverless)
このパターンは、S3 Vectorsをデータの「正(Source of Truth)」として利用し、必要に応じて高性能な環境へデータを展開するアプローチです。
- 仕組み: S3 Vectorsに蓄積されたインデックスから、ワンクリック(Single click)またはAPI経由で、Amazon OpenSearch Serverlessコレクションへスナップショットをエクスポートする。
- メリット: 平時は安価なS3 Vectorsでデータを保持し、キャンペーン期間や特定の分析タスクなど、高頻度かつ低遅延な検索が必要なタイミングでのみ、高性能なOpenSearch Serverlessにデータをロードできる。
- 適用シナリオ: 季節性のトラフィック変動があるECサイトのレコメンデーション、一時的な集中分析、レイテンシ要件が厳しい特定のアプリケーション。
4.3 Amazon Bedrock Knowledge Basesとの統合
また、S3 VectorsはAmazon Bedrock Knowledge Basesのバックエンドとしても選択可能です。これにより、開発者はRAGアプリケーションを構築する際、ベクトルストアの管理を意識することなく、S3の耐久性とコストメリットを享受できる。Bedrock Agentから見れば、S3 Vectorsは透過的な知識源として機能します。
5. 次世代検索とマルチモーダル統合

5.1 マルチモーダル検索の仕組み
マルチモーダル検索では、テキスト、画像、音声、ビデオといった異なる形式のデータを、共通のベクトル空間(Embedding Space)にマッピングします。例えば、Amazon Nova Multimodal Embeddingsモデル16を使用することで、「夕日が沈むエッフェル塔」というテキストと、実際の夕日の画像を、数学的に近い位置にあるベクトルとして表現できます。
S3 Vectorsは、このような高次元かつ大規模なベクトルデータを保存するのに最適な基盤となります。
5.2 ビデオ検索の革新
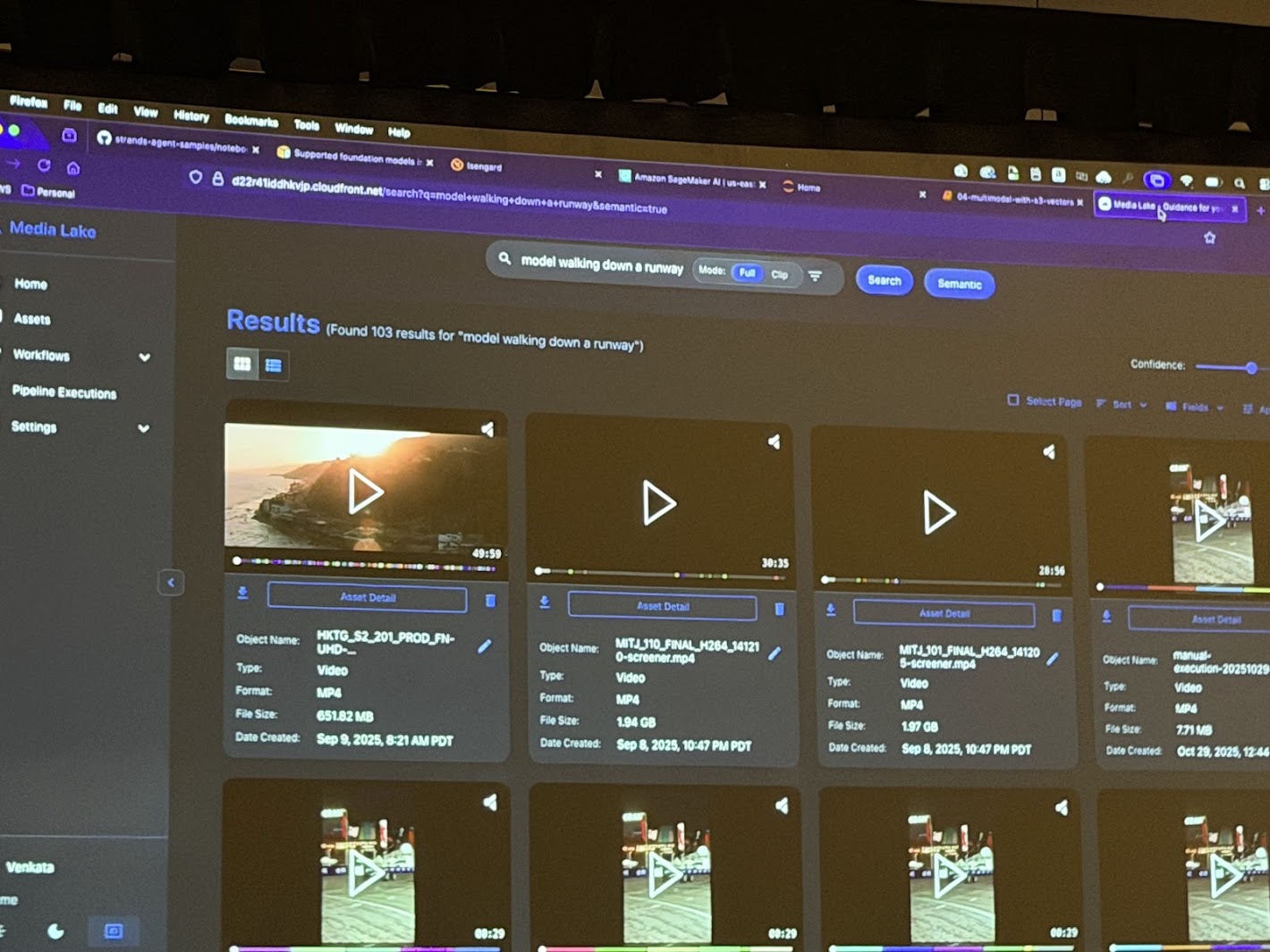
Chalk Talkのデモでは、特にビデオ分析におけるS3 Vectorsの活用が強調されていました。
従来、ビデオ内の特定のシーンを検索するためには、事前にビデオ全体にタグ付けを行うか、高価なビデオ専用分析基盤が必要でした。しかし、S3 Vectorsとマルチモーダルモデルを組み合わせることで、以下のようなワークフローが可能になります。
- Ingestion: 長時間のビデオファイルをS3にアップロード。
- Embedding: ビデオをフレーム単位(またはシーン単位)で分割し、それぞれをベクトル化してS3 Vectorsに保存。
- Retrieval: ユーザーが「モデルがランウェイを歩いているシーン(Model walking down a runway)」とテキストで検索。
- Result: S3 Vectorsから該当する意味を持つフレームのタイムスタンプが即座に返され、ピンポイントで再生が可能になる。
このプロセスにおいて、S3 Vectorsは「無限のビデオアーカイブ」に対する検索エンジンとして機能し、メディア企業やコンテンツプロバイダーにとって、過去の膨大な映像資産を低コストで再利用可能な状態にする強力なツールとなります。
6. 統合シナリオとデモンストレーション分析
Chalk Talkの後半では、これらの技術を統合した具体的なデモンストレーション「Private Assistant V2」が行われた。このデモは、Strands AgentsがS3 Vectorsをメモリとして活用し、複雑なタスクをこなす様子を示している。
6.1 デモのシナリオ構成
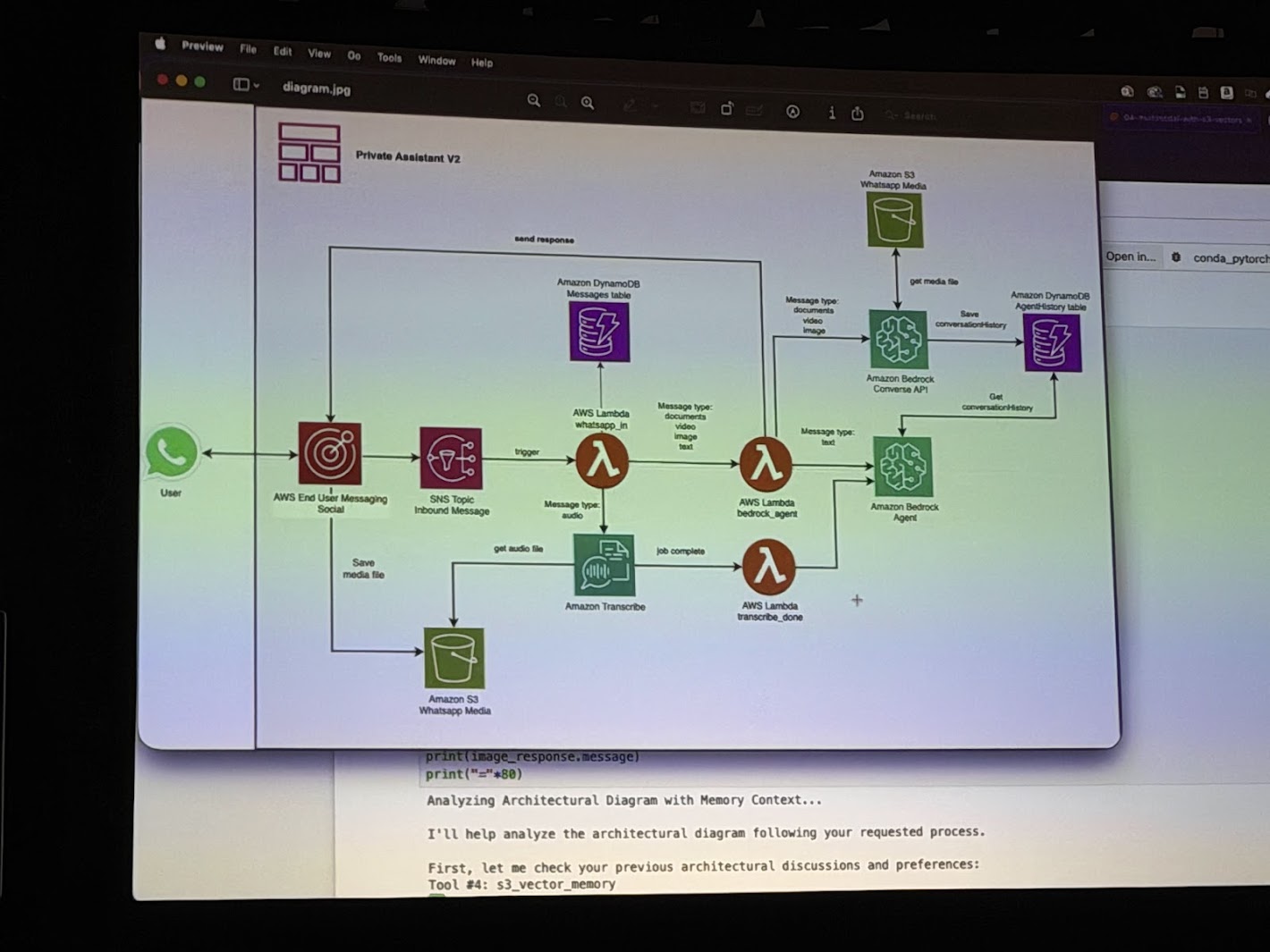
デモには以下のコンポーネントが登場します。
- User: WhatsApp等のチャットインターフェースを通じて指示を出す。
- AWS End User Messaging Social: メッセージの入り口。
- AWS Lambda: エージェントのロジック(Strands Agents)を実行するサーバーレスコンピュート。
- Amazon Bedrock Agent: 推論とツール実行の中核。
- Amazon S3 Vectors : 長期記憶として機能。
- Amazon DynamoDB: 会話履歴(短期記憶)やユーザープロファイルの管理。
6.2 実行フローの詳細分析
トランスクリプトに基づき、デモの具体的な挙動を再構成します。
- 初期化とユーザー設定:
エージェントが起動し、ユーザーIDに基づいたメモリ空間を確保する。ユーザーが「私は朝型人間で、テック企業が好きだ」といった好みを伝えると、エージェントはそれを長期記憶(S3 Vectors)に保存する。これにより、将来のセッションでもこの文脈が維持される。 - アーキテクチャ図の分析:
ユーザーがAWSのアーキテクチャ図(画像)をアップロードする。エージェントはマルチモーダルモデルを使用して画像を解析し、「Private Subnet、DynamoDB、Lambda、S3 Bucket、Bedrockが含まれている」といった構成要素を認識する。さらに、メモリ内に過去の類似したアーキテクチャ議論がないかを確認し(Retrieval)、新たな洞察を加えて応答する。 - ドキュメントとの照合:
次に、ユーザーが「Strandsのドキュメント(PDF)」をアップロードし、「このアーキテクチャ図はStrandsのベストプラクティスに沿っているか?」と質問する。エージェントはPDFを読み込み(RAG)、画像分析の結果と照らし合わせて、「サーバーレスアーキテクチャを採用しており、スケーラビリティの観点で適切である」といった評価を下す。 - ビデオ分析と文脈理解:
最後に、ランダムに見えるビデオをアップロードする。エージェントはビデオの内容を要約し、これまでの会話(アーキテクチャ、ドキュメント)との関連性を探る。さらに、過去のセッションを含めた全体の要約(Synthesis)を行い、重要な洞察を長期記憶に書き戻す。
このデモは、Strands Agentsが「画像を見る」「ドキュメントを読む」「ビデオを解析する」「記憶を検索する」という複数のモダリティとツールを自律的に切り替えながら、一貫した文脈の中でタスクを遂行できることを証明し、S3 Vectorsは、その裏側で増え続けるマルチモーダルな記憶を支える基盤として機能しています。
7. セキュリティ、ガバナンス
7.1 本番環境に向けた考慮事項
「プロトタイプからプロダクションへのキャズム」を越えるためには、機能だけでなく非機能要件も重要です。
- セキュリティ: S3 VectorsはS3のセキュリティ機能を継承しており、IAM(Identity and Access Management)による詳細なアクセス制御、KMSによる暗号化、VPCエンドポイントによるネットワーク分離が可能である。エージェントがアクセスできるデータをバケットポリシーで厳密に制限することで、情報漏洩リスクを最小化できる。
- ガバナンス: Strands Agentsのようなフレームワークを使用する場合、エージェントがどのツールをいつ使用したかというログ(Trail)が重要になる。AWS CloudTrailやCloudWatchとの統合により、エージェントの思考プロセスと行動を監査可能な状態で記録する必要がある。
- コスト管理: S3 Vectorsの料金体系(PUT, Storage, Query)を理解し、不要なインデックス化を避けるためのライフサイクルポリシーの設定や、OpenSearch Serverlessへのエクスポート頻度の最適化が求められる。
Chalk Talk 質疑応答
1. Amazon S3 Vectors の仕様と機能
| 質問 (Question) | 回答 (Answer) |
| ベクトルの種類やデータ形式に制約はあるか? |
制約は少なく、汎用的に利用可能です。 現在は浮動小数点(Float)のベクトルに対応しており、最大4,096次元までサポートしています。テキストや画像だけでなく、バイオインフォマティクス(遺伝子解析)などで用いられるバイナリベクトルのような特殊なユースケースも想定されており、埋め込みモデルの種類(Embedding Model Agnostic)を問わず利用できます。 |
| 扱えるベクトルの規模(最大数)は? |
数十億規模に対応しています。 現時点(GA直後)での仕様として、1つのインデックスあたり最大20億(2 Billion)ベクトルまでサポートしています。バケット全体ではさらに大規模なデータ(最大20兆ベクトル)を保存可能です。 |
| バッチクエリ(複数一括検索)は可能か? |
現時点では未対応です。 「4つの検索を1回のリクエストで行う」といったバッチ処理機能は現在提供されていません。必要な回数分、個別にAPIコールを行う必要があります。 |
| 集計機能(Aggregation)はあるか? |
現時点ではありません。 SQLの |
2. パフォーマンスとコスト
| 質問 (Question) | 回答 (Answer) |
| レイテンシ(応答速度)は今後改善されるか? |
はい、改善に向けた取り組みが進んでいます。 公式には「サブセカンド(1秒未満)」としていますが、バックグラウンドでの分散キャッシュレイヤーの最適化などにより、頻繁にアクセスされるインデックス(Warm状態)では50ms〜200ms程度の応答速度が期待できます。 |
| OpenSearchとの統合(パターン1)におけるコスト削減の仕組みは? |
ストレージコストの適正化が主因です。 OpenSearch Serviceのマネージドクラスターを使用する場合でも、ベクトルデータの実体を高価なインスタンスストレージではなく、安価なS3 Vectorsに配置することで、ストレージコストを最大90%削減可能としています。 |
3. 実装とアーキテクチャ
| 質問 (Question) | 回答 (Answer) |
| バケット内のアクセス制御(Segregation)は可能か? |
バケットレベルでの制御が基本となります。 S3 VectorsはS3のセキュリティモデルを継承しているため、基本的にはバケットポリシーでの制御となります。バケット内部でデータを細かく分離(Segregation)したい場合は、複数のインデックスへの分割やパーティショニングといった設計上の工夫が必要です。 |
| 検索結果の関連性(Relevancy)をどう高めるか? |
メタデータの戦略的な活用が鍵です。 ベクトルデータそのものだけでなく、メタデータフィールドに「S3のファイルパス」「ページ番号」「著者ID」「元のテキスト」などの属性情報を付与することが重要です。これにより、検索結果に対してアプリケーション側でフィルタリングを行ったり、正しい参照元へユーザーを誘導したりすることが可能になります。 |
| エージェントのモニタリングはどうすればよいか? |
使用するフレームワークやレイヤーに依存します。 Bedrock Agentsのようなマネージドサービスを使う場合はAWSの標準機能で監視できますが、Strands Agentsのようなカスタム実装を行う場合は、エージェントの思考プロセスやツール使用ログを独自のログ基盤(CloudWatch等)に出力・分析する設計が必要です。 |
まとめ
AIエージェントはもはや未来の技術ではなく、現在のビジネス課題を解決するための実用的なツールセットとなりつつあります。
Amazon S3 Vectorsは、データの「量」と「コスト」の制約を取り払い、企業が保有するすべてのデータをエージェントの知識として活用可能にするインフラストラクチャです。これにより、「とりあえずデータをS3に入れておけば、後からAIで検索・活用できる」というデータレイクの価値が飛躍的に向上します。
Strands Agents SDKは、エージェント開発の「複雑性」の制約を取り払い、モデルの知能を直接的にビジネスロジックへと変換するアプリケーションフレームワークである。MCPによる標準化は、エージェントがアクセスできるツールとデータの世界を無限に広げる可能性を秘めています。
これら二つの技術を組み合わせることで、企業は「スケーラブル」で「コスト効率が高く」、かつ「高度に自律的」なAIエージェントを本番環境で運用することが可能となります。キャズムを越えた先にあるのは、AIが人間のパートナーとして真に機能する、新しい生産性の時代です。
今後は、OpenSearchとS3 Vectors の連携パターン1と2について、どのようなユースケースで有効なのか、検証を進めていこうと思っています。
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください。 複雑な内容に関するお問い合わせの場合には直接営業からご連絡を差し上げます。 また、よろしければ以下のリンクもご覧ください!
<QES関連ソリューション/ブログ>
<QESが参画しているAWSのセキュリティ推進コンソーシアムがホワイトペーパーを公開しました>
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。

