記事公開日
最終更新日
第2回 機械学習を試してみる(1/3)
第1回では機械学習の解説と、学習を始める前準備としてプロジェクトまでを説明しました。
第2回では実験とよばれる機械学習の中身を構築し、サンプルデータを用いて実際に機械学習を行ってみたいと思います。
通常機械学習においては、学習を行う前の「事前処理」と実際の「学習処理」に分けることができます。AzureMLにおいても同様で、事前処理と学習処理を合わせた「実験(Experiment)」を作成していきますが、全体のイメージとしては以下のような流れとなります。
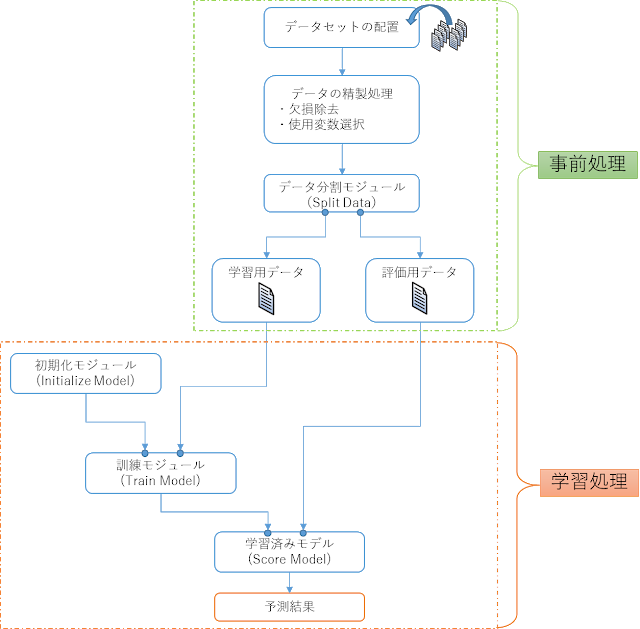
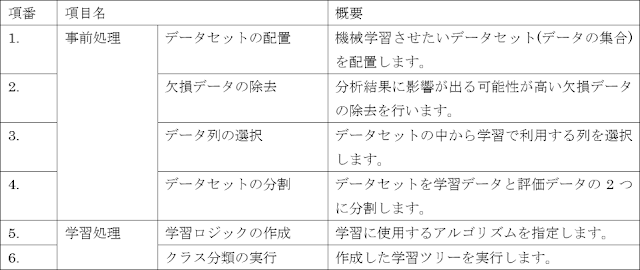
第1章 事前処理(前編)
学習を行う前にデータセットを配置し、データの精製処理等を行う必要があります。
もちろん手作業でそれらを行うことも可能ですが、AzureMLには、それらを行うためのモジュールも用意されています。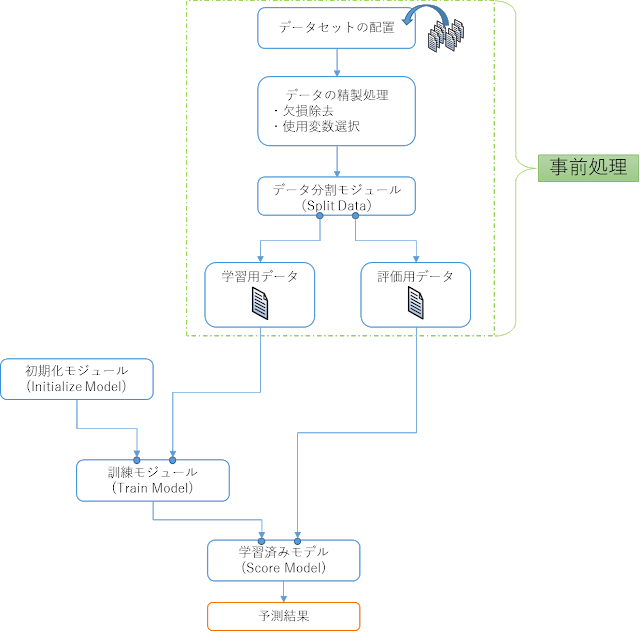
1.1.実験の作成手順
AzureMLでは上の図のような記述を「実験(Experiment)」と呼ばれる箱の中に配置していきます。
それでは空の実験(Experiment)を作成します。
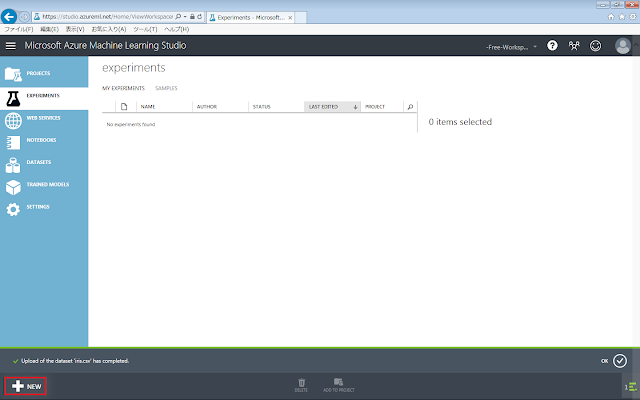
左側のメニューから「EXPERIMENT」を選択し「+NEW」ボタンをクリックします。
開いた画面で「Blank Experiment」ボタンをクリックします。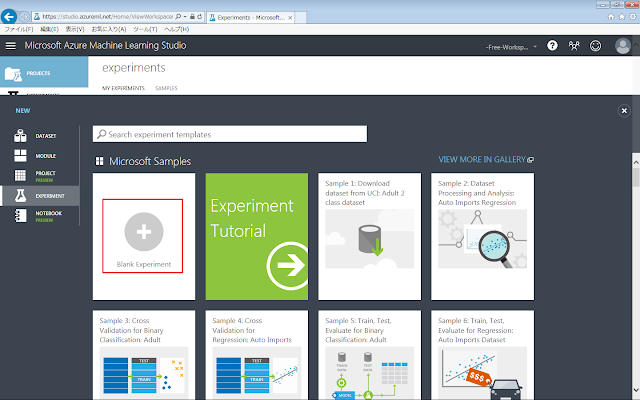
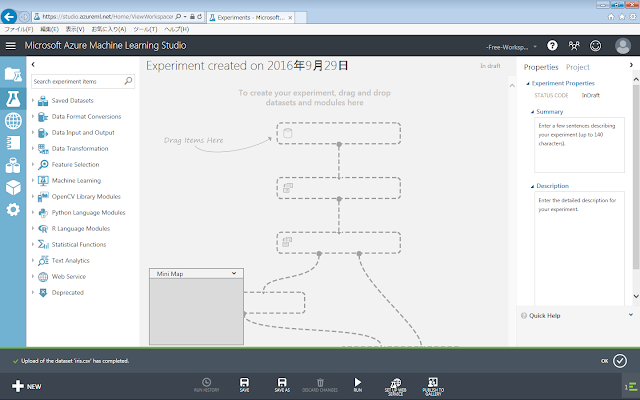
実験が作成されると、初期画面が表示されます。灰色の破線の図は、何らかのアイテムを置けば消えます。
実験名をクリックすると、変更することができます。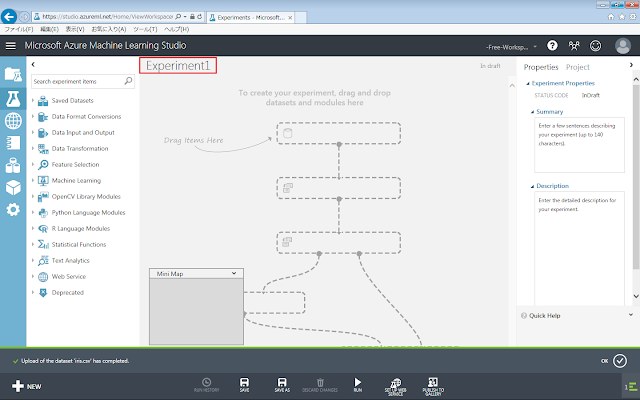
1.2.データセットの配置
実験で使用するデータセットを配置します。
1.2.1.データセットの内容
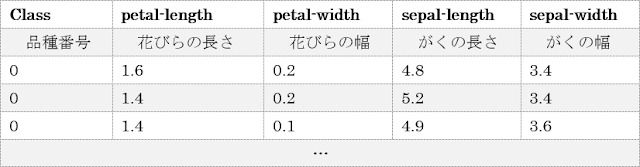
機械学習を行う上で最も手間のかかる作業がデータ収集ですが、今回は機械学習による予測の部分を重点的に紹介するために、予めAzure ML上に用意されている、アヤメの統計データを用いることにします。この統計データには、アヤメの花びらの長さと幅、がくの長さと幅、そして品種を示す数字(「0」または「1」)が含まれています。クラス分類の場合、これらの長さと幅から、品種名を分類させる学習モデルを作ることになります。
今回の実験では、最低限のデータにて機械学習を行いますが、さらに発展的な学習を行うには、分析手法の特徴に合わせ、データを用意しておく必要があります。
1.2.2.データセットの配置手順
AzureMLではAzure ML上に予め用意されている統計データもありますが、ローカルにあるファイルをアップロードして使用することも可能です。
今回の学習ではAzureML上のデータを使用するので、アップロードは不要ですが、参考情報として、ローカルデータのアップ方法を記載します。
(参考情報)
■ローカルデータセットのアップロード
※ただし、作成途中の実験を残したまま以下の手順を行うと、保存されていない内容が破棄されてしまうので、注意してください。
「Datasets」タブを開き、「+NEW」ボタンをクリックします。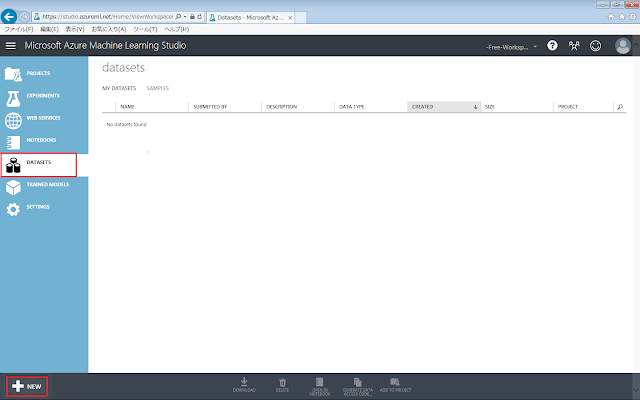
「FROM LOCAL FILE」をクリックします。表示される画面にある「参照」ボタンをクリックしてファイルを選択したあと、「☑OK」ボタンをクリックします。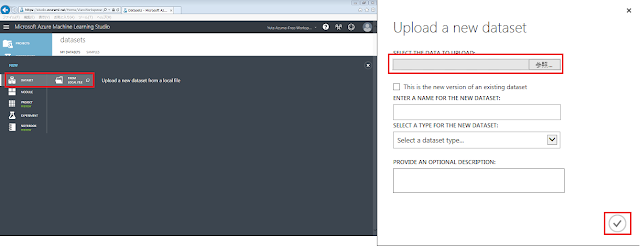
それでは本筋に戻って、AzureML上のデータセットとして利用する手順を説明していきます。
まず、「Saved Datasets」→「Samples」→「Iris Two Class Data」モジュールを、灰色破線の図に向けてドラッグアンドドロップします。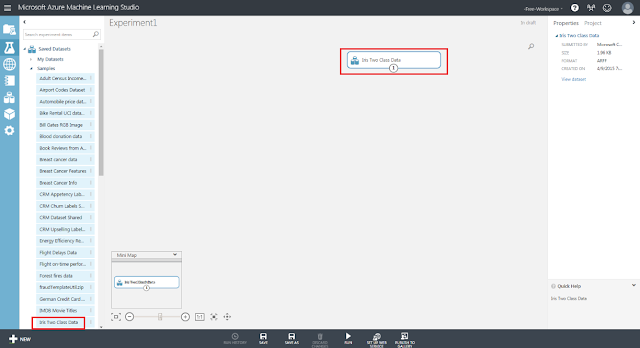
データセットの下部の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックして、データセットを確認します。 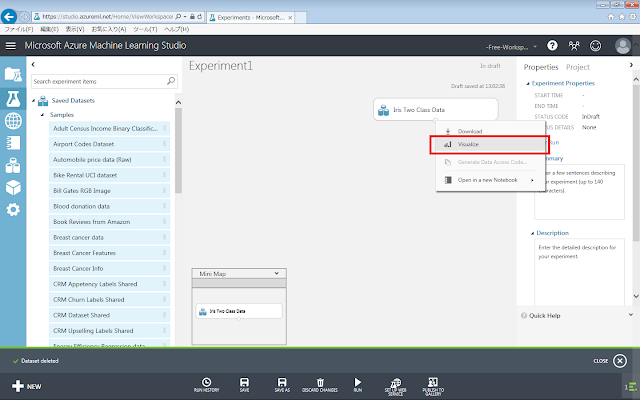
データセットに含まれるデータが表示されます。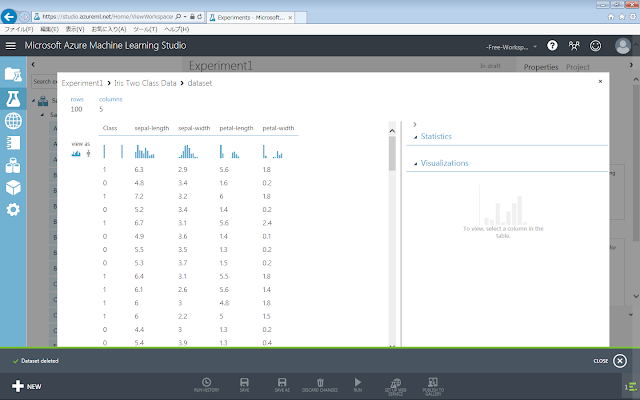
1.3.データ列の選択
配置したデータセットの中から、実際に使用するデータ列を指定します。
1.3.1.データ列の選択手順
「Select Columns in Dataset」モジュールを用いて、データセットにあるデータ列のうち、学習に使用するデータ列のみを選択できます。
このとき、学習に使用する列の名前だけでなく、学習の結果として求める列の名前も選択します。後者は学習自体には用いません(用いてしまうと学習の意味がなくなってしまうため)が、学習をどれくらいの精度で行うことができているのかを評価するために使用します。
まず、「Data Transformation」→「Manipulation」→「Select Columns in Dataset」モジュールを、画面中央の灰色の領域に配置します。
データセットの下部の丸印から「Select Columns in Dataset」モジュールに向けてドラッグアンドドロップします。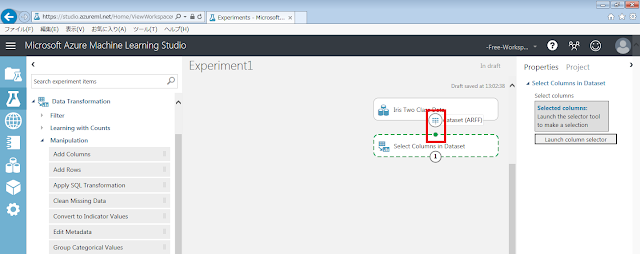
「Select Columns in Dataset」モジュールに!マークが出ています。
これは値が設定されていないために表示されます。次の手順を行うことで、!マークを消すことができます。
「Select Columns in Dataset」モジュールが選択された状態で、右側にある「Launch column selector」ボタンをクリックします。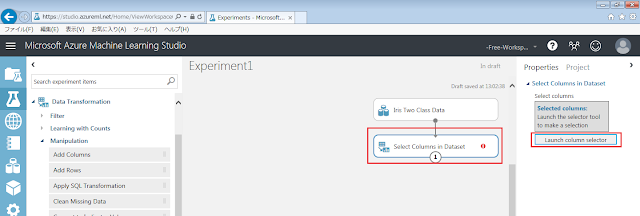
必要なデータ列のタイトルを選択後、「>」ボタンをクリックします。ここでは、評価に使用するための品種「Class」に加えて、がくの長さ「sepal-length」と幅「sepal-width」を選択しました。評価のために使用する品種「Class」以外の列は最低1つ選択されていれば良いため、選択するパターンを替えながら、精度を比較してみるのも良いでしょう。
その後、「☑OK」ボタンをクリックします。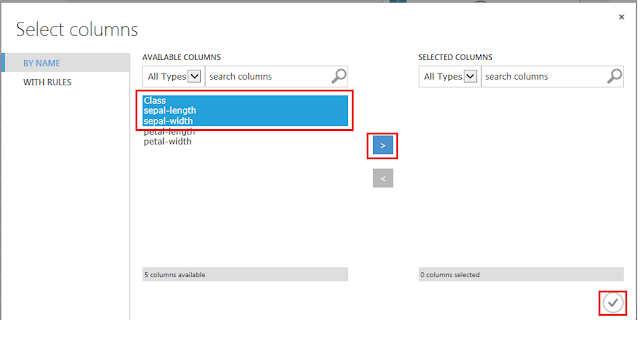
1.3.2.解説
1.3.2.1処理内容
学習に使用するデータ列を制限するというのがどういうことか、グラフを使いながら示したいと思います。
例えばアヤメのsepal-length, sepal-width, petal-lengthからなるデータと、この3つのうちから2つずつ取り出したデータ3種類を比較すると以下のグラフのようになります。グラフの軸1本がデータ列1本に対応し、点の色は、黒と赤がそれぞれ品種(Class)の0と1に対応しています。最初の段階で4つではなくて3つしかデータ列を使用しないのは、グラフに示すことができないためなので、基本的な考え方はより多くのデータ列を使用する場合も同様です。
① petal-lengthとsepal-lengthの組み合わせ
② petal-lengthとsepal-widthの組み合わせ
③ sepal-lengthとsepal-widthの組み合わせ
選択するデータ列の組み合わせが適切な場合には境界がはっきりするために分類の正答率が高くなりますが、組み合わせが不適切な場合は点の散らばっている領域が重複してしまう(特徴が似通ってしまう)ため、分類の正答率が低くなってしまいます。下のグラフを見てみると、①番のグラフや②番のグラフではそれぞれの色の点の群が大きく離れていますが、③番のグラフではそれほど大きく離れていないので、③番の選び方だと正答率が低そうだと考えられます。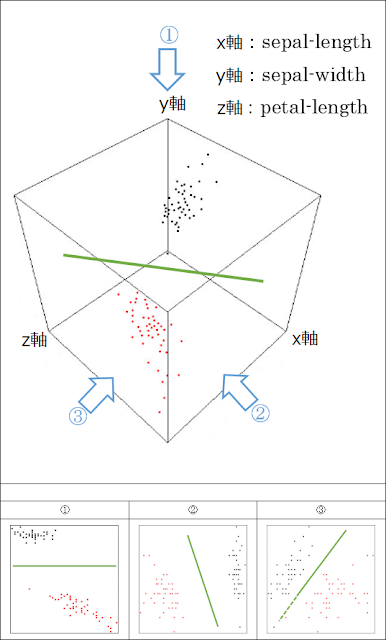
実際に予測して求めた結果を以下に示しますが、①番と②番ではほぼすべての予測が正解しているのに対して、③番では正答率が8割程度になっていて、だいたい直感通りの結果になっています。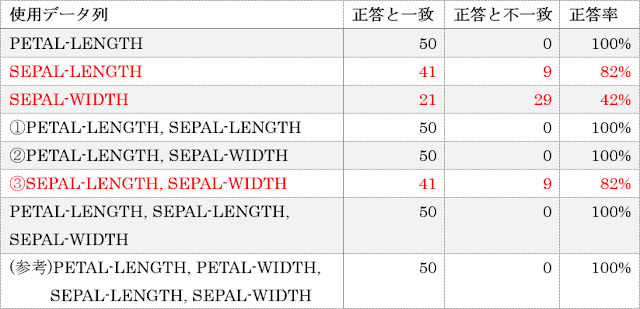
次に注目したいのが、組み合わせるデータ列の数を増やせば必ず正答率が向上するというわけではないことです。
例として、Sepal-LengthとSepal-Widthの組み合わせに関して、個別の正答率を見てみます。先ほどは、データセット同士の重なり具合のみに注目してグラフを描きましたが、ここでは、予測値と正答値の一致具合に注目してグラフを描いてみます。分類結果が正答と一致した場合を青色の丸印、一致しなかった場合を赤色の×印で色分けした散布図を以下に示します。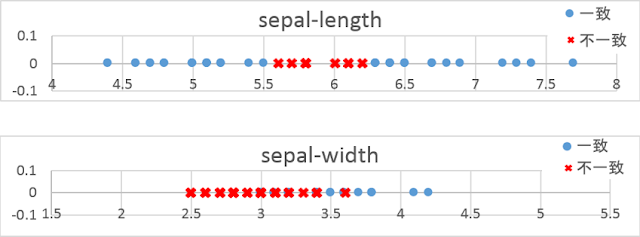
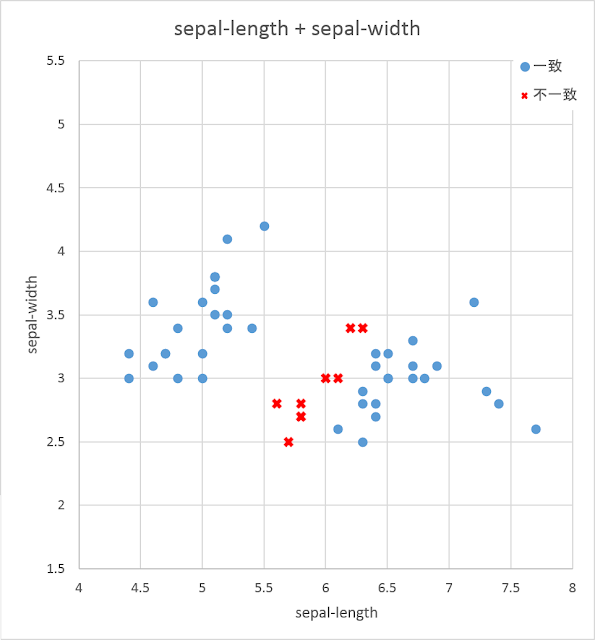
いずれのグラフでも、異なる品種のデータ同士が交わる境界の近くで不一致のデータが多く発生していることがわかります。
各データセットの領域が重複しないように分割するためには、次元を上げて奥行き方向できれいに分割できるように特徴量を追加したり、グラフの平面自体を変形させてきれいに分割できる線を引けるようにしたりといった手法がとられます(後者は初期化モジュールの側でのアルゴリズムの話です)。
使用するデータ列を抽出するという作業によって、学習に大きな影響を及ぼすデータ列だけを取り出すことができればより正答率を高めることができる一方で、ノイズとなるような余計なデータ列を取り出してしまうと正答率が低くなってしまいます。
逆に、データセットに新しいデータ列を追加する作業では、種類が多ければ多いほど正答率が上がりそうだと考えてしまいがちですが、適切なものを選んで追加しないと正答率が悪化することがあると言えます。
Azure Machine Learningには、どのデータ列を学習させるのが適切か判定する「Filter Based Feature Selection」モジュールが用意されていますが、また別の回にでもご紹介したいと思います。
1.3.2.2.変数
これまでデータセットに含まれる「データ列」のようにご紹介してきましたが、それらデータの要素を「変数」と呼びます。変数のうち、学習モデルに入力するデータ列のことを「独立変数」または「説明変数」、「特徴量」と呼びます。対して、学習モデルには入力せずに、学習結果として出力される値に相当するデータ列を「従属変数」または「被説明変数」、「予測量」と呼びます。
アヤメのデータセットをもとに品種を分類する例を、以下の表に示します。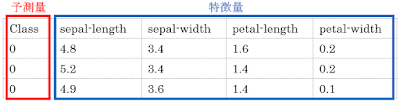
予測量には1種類の変数しか使用できませんが、特徴量には複数の変数を使用できるので、それらの変数の組み合わせも様々なものが考えられます。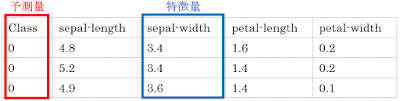
上の表では、データセットに含まれる変数のうち、予測量以外のすべての変数を特徴量として使用していますが、下の表のように、特徴量を1種類だけ入力することも考えられます。
特徴量として学習モデルに入力する変数の種類が増えるにつれて、計算量・計算時間が大きくなってしまうという問題があります。
また、前項でお伝えした通り、直感的には特徴量を増やしたほうが正答率を上げられるように考えがちですが、実際には、予測に対する影響度が小さい特徴量を学習モデルに入力してしまうことで、それら無関係なデータにも意味を見出してしまい、却って正答率が下がってしまう場合があります。さらに、特徴量の数が増える(次元が上がる)と、学習用データセットに対する予測精度は上がっても評価用データセットに対する予測精度は上がらなくなる場合があります。これは「次元の呪い」と呼ばれます。加えて、高次元のデータセットでは、グラフなどの形で可視化して人間が確認することができないという問題点もあります。以上の理由から、なるべく少ない特徴量から正確に予測量を求められる学習モデルを作ることが望ましいです。

