記事公開日
【AWS】RedshiftServerlessによる外部テーブルへのクエリ(Spectrum)を最小権限で実行する方法

はじめに
こんにちは。DXソリューション営業本部の後藤です。
この記事では、S3に格納されているデータに対してRedshift Spectrumの機能を使ってクエリする方法について解説します。
Redshift Spectrumとは
Amazon Redshift Spectrum を使用すると、効率的にクエリを実行し、Amazon Redshift テーブルにデータをロードすることなく、Amazon S3 のファイルから構造化および半構造化されたデータを取得できます。Redshift Spectrum クエリでは超並列処理を採用しており、大きなデータセットに対する処理が非常に高速で実行されます。https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c-using-spectrum.html
構成図
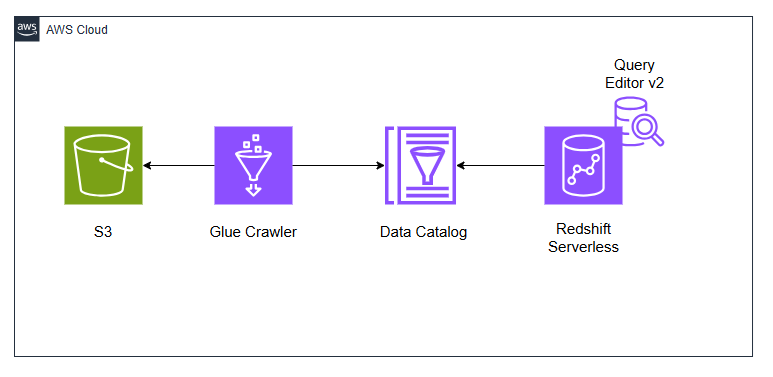
環境構築
今回の検証に必要なリソースを作成していきましょう。作成するリソースは以下の通りです。
・S3
・Glue Crawler
・IAMポリシー
・IAMロール
・Redshift Serverless
外部テーブルの作成
S3に対してデータを読み込む場合、Glue Data Catalogに外部テーブルを作成する必要があります。
外部テーブルの作成にはGlue Crawlerを利用します。
Glue Crawlerの使用方法を知りたい方は以下ブログを参考にしてみてください。
今回は以下ブログで作成したGlue Crawlerを利用しますので、作成手順等は割愛します。
↓【AWS】Glue Crawlerで外部テーブルを作成してみた

Glue Crawlerの実行
指定のS3をデータソースにしたGlue Crawlerを選択してください。右上のRunをクリックし実行します。
しばらく経ってステータスがcompleteになることを確認してください。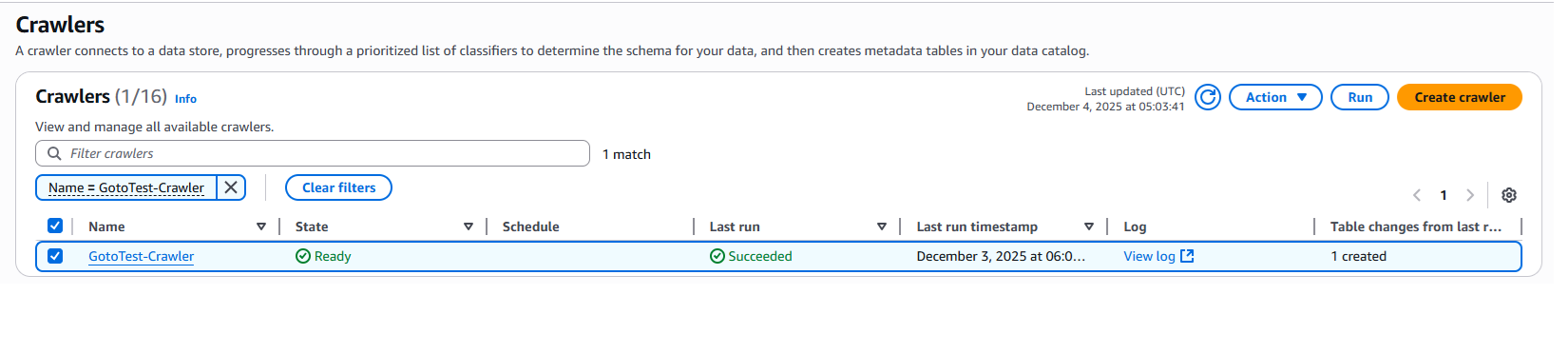
ステータスがcompleteになることを確認できたら、左ペインからData bases⇒Tablesに移動してください。
するとGlue Crawlerで外部テーブルが自動作成されていることが確認できると思います。
Spectrum実行時にこの外部テーブル(スキーマ定義)を利用してS3にあるデータに対してクエリを実行します。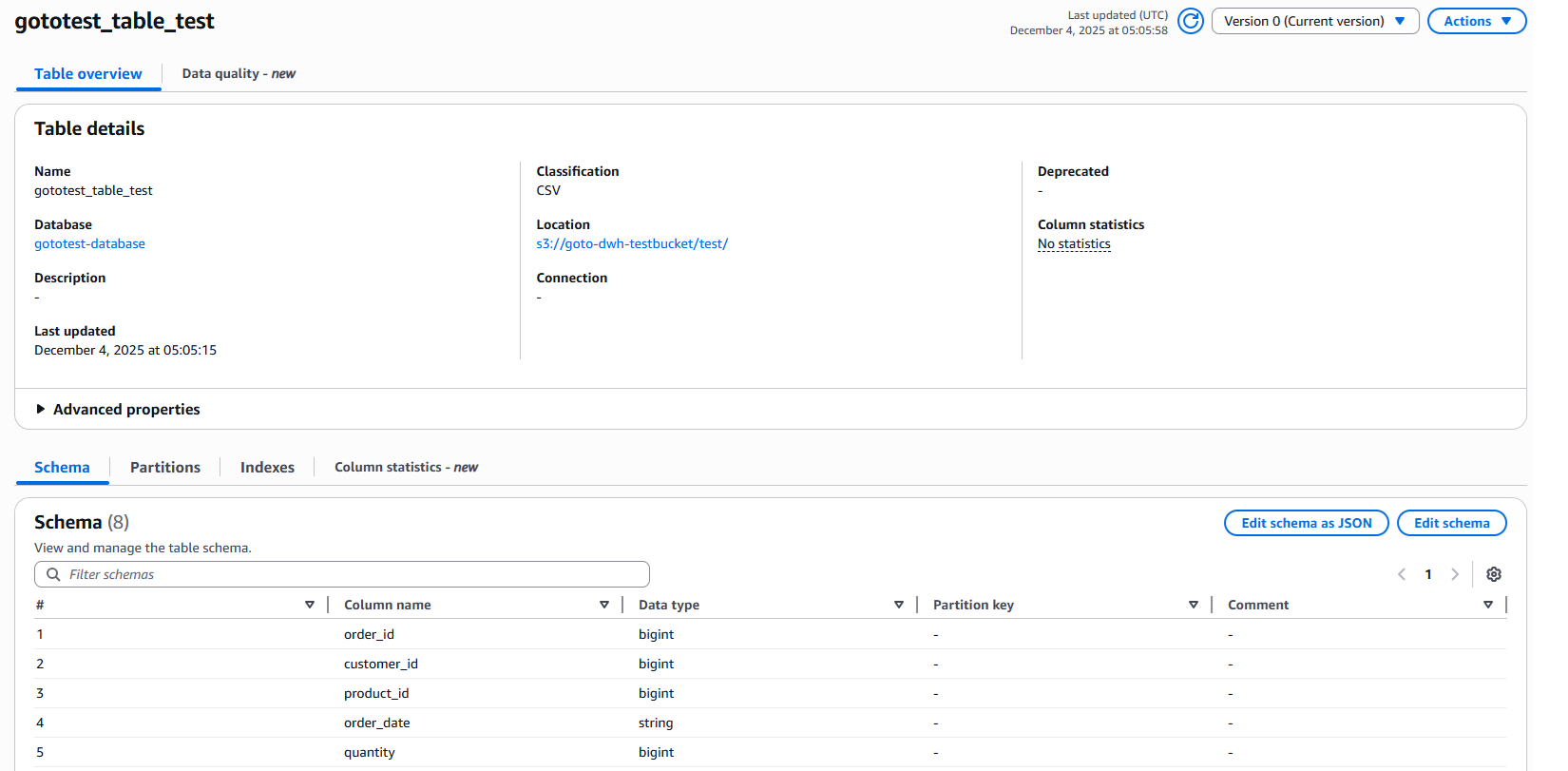
Redshift ServerlessにアタッチするIAMロールの作成
続いてRedshift ServerlessにアタッチするIAMロールを作成していきましょう。
IAMポリシーの作成
まずはIAMポリシーを作成します。以下ポリシーがSpectrumを実行する上で必要な権限になります。
S3のARNを変更して作成してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucketVersions",
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::goto-dwh-testbucket",
"arn:aws:s3:::goto-dwh-testbucket/test/*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:CreateDatabase",
"glue:DeleteDatabase",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:UpdateDatabase",
"glue:CreateTable",
"glue:DeleteTable",
"glue:BatchDeleteTable",
"glue:UpdateTable",
"glue:GetTable",
"glue:GetTables",
"glue:BatchCreatePartition",
"glue:CreatePartition",
"glue:DeletePartition",
"glue:BatchDeletePartition",
"glue:UpdatePartition",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition"
],
"Resource": "*"
}
]
}
IAMロールの作成
次にIAMロールを作成していきましょう。
Redshiftにアタッチするためには以下の信頼ポリシー権限が必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシーには先ほど作成したものを選択します。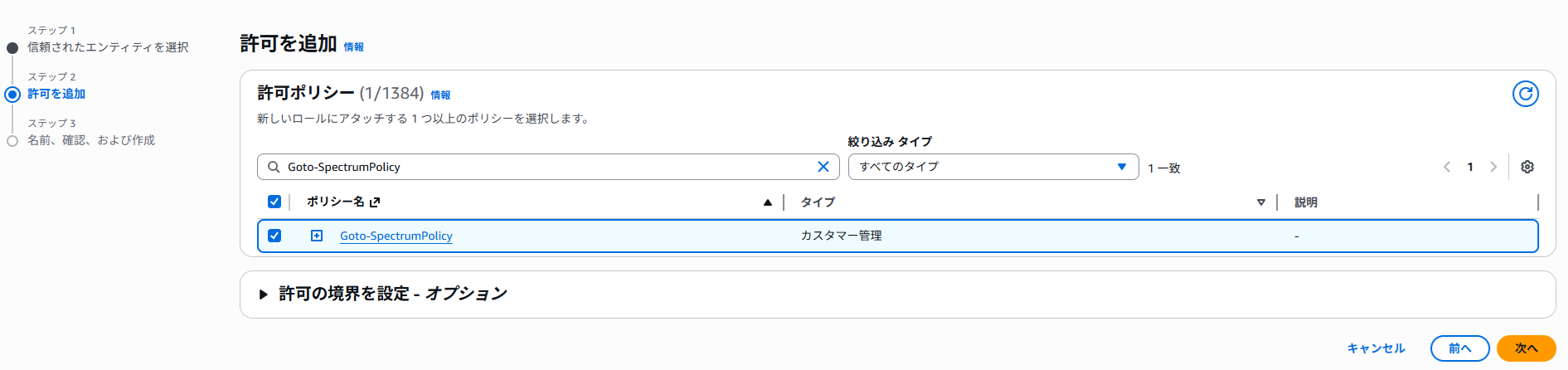
名前を入力してIAMロールを作成します。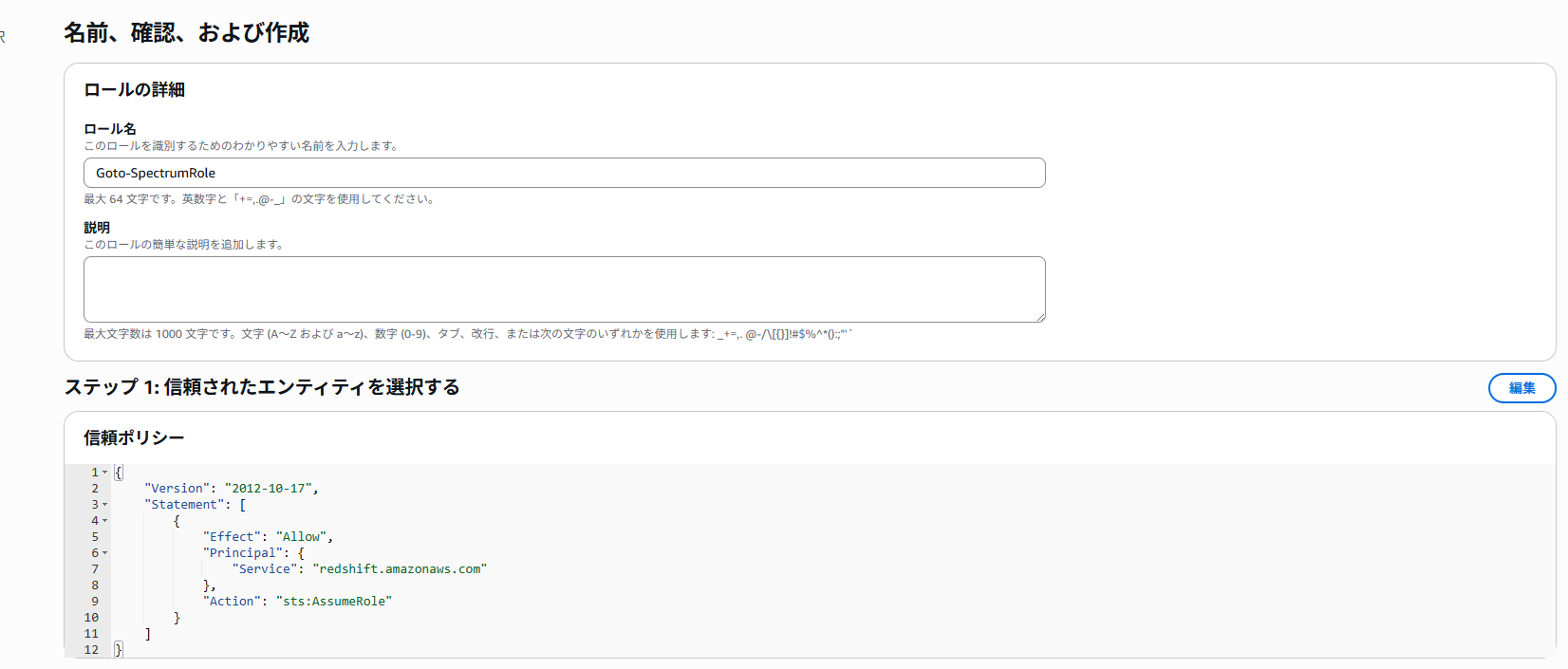
Redshift Serverlessの作成
それではRedshift Serverlessを作成していきましょう。
Redshift Serverlessの構築については以下ブログで詳しく解説してあるのでこちらを参考に作成してみてください。
今回は詳しい設定手順は割愛します。
↓Amazon Redshift Serverlessを構築してみた

<ワークグループの作成には主に以下の設定を行います>
・ワークグループの名前
・Redshift Serverlessを構築するVPC
・Redshift Serverlessに適用するセキュリティグループ
・サブネット
・ベース容量(あとで変更可能)
まずはワークグループを作成します。今回はテスト用なのでベース容量は8で作成しました。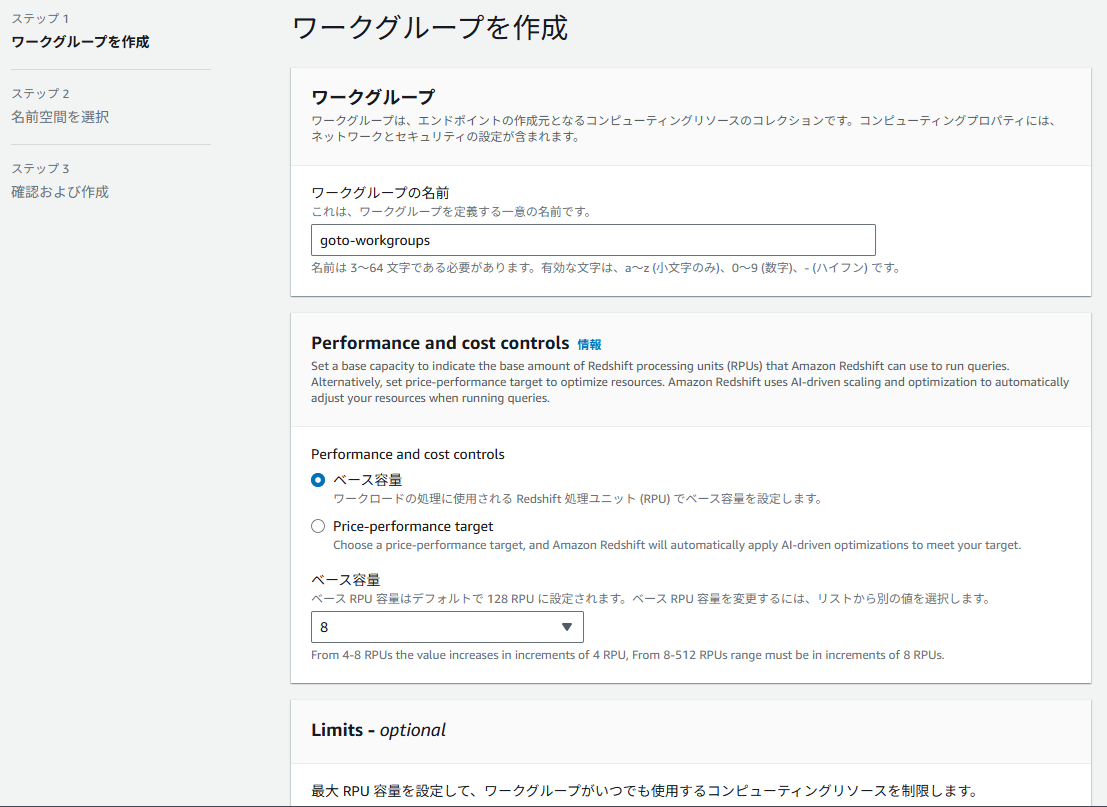
次に名前空間を作成します。
名前を入力し、管理者のパスワードを手動で設定しておきます。このパスワードは後ほど使用するため控えておいてください。
関連付けるIAMロールには先ほど作成したIAMロールを選択します。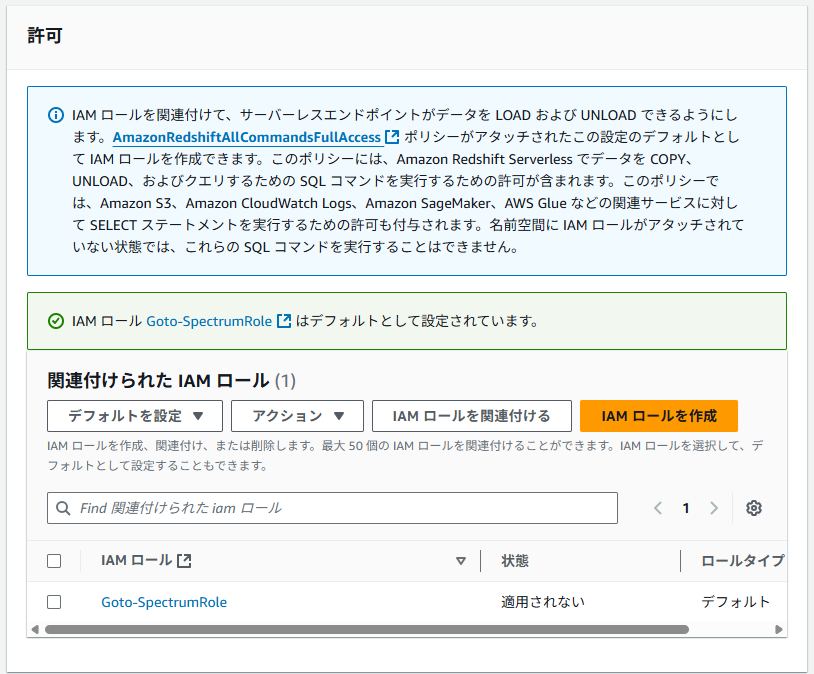
作成が完了したら、Serverlessを選択し画面右上の「クエリエディタv2でクエリ」をクリックしてクエリエディタv2に接続してください。
Spectrum実行
Serverlessに接続できることを確認できたら、Spectrumを実行していきましょう。外部テーブルがあるGlue Data Catalogに接続するためには実行ユーザーにUSAGE権限を付与する必要があります。
まずは、作成したServerlessの右側にある「⋮」をクリックし、「Create connection」をクリックします。
選択画面から「Database user name and password」を選択して下さい。
User nameを「admin」にし、先ほど手動で設定したパスワードを入力してください。右下の「save」をクリックして接続します。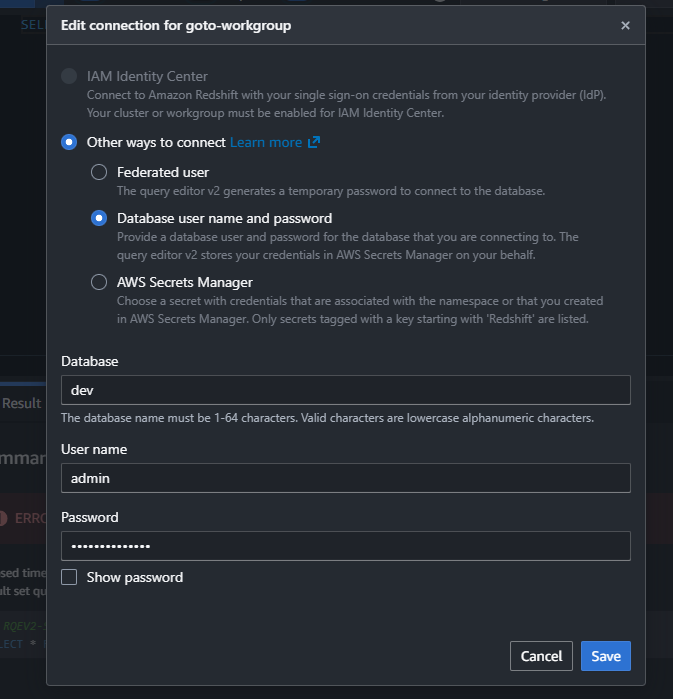
接続が完了したら実行するIAMユーザ-に対してUSAGE権限を付与します。
以下SQL文を参考に付与して下さい。
※実行するIAMユーザーにData Catalogを操作する権限が必要です。権限がなければ今回作成したIAMポリシーを付与して下さい。
GRANT USAGE ON DATABASE awsdatacatalog to "IAM:myIAMUser"
権限付与が完了したら、再度「Edit connection」をクリックし次は「Federated user」にて再接続を行います。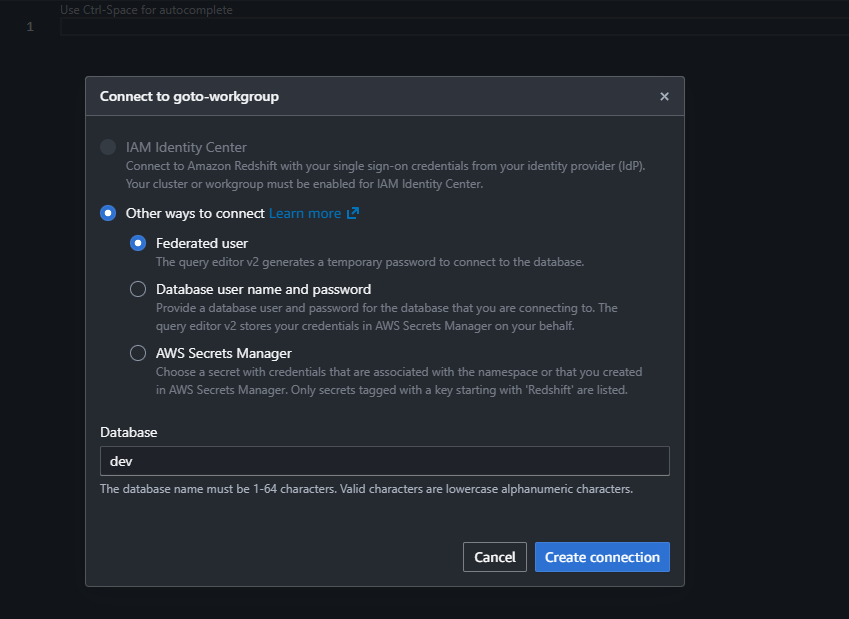
Serverless配下をクリックしていくと、今回Glue Crawlerで作成したテーブルがあることが確認できると思います。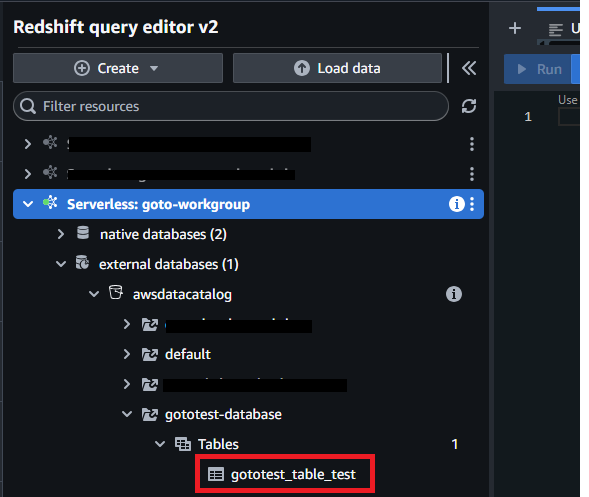
テーブルを右クリックし、「select table」をクリックします。すると以下のようなSQL文が自動で出力されます。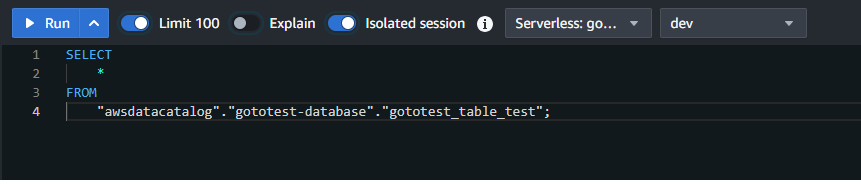
「RUN」を押してクエリを実行します。
外部テーブルからスキーマ情報を取得し、S3にあるデータに対してクエリを実行できることが確認できました!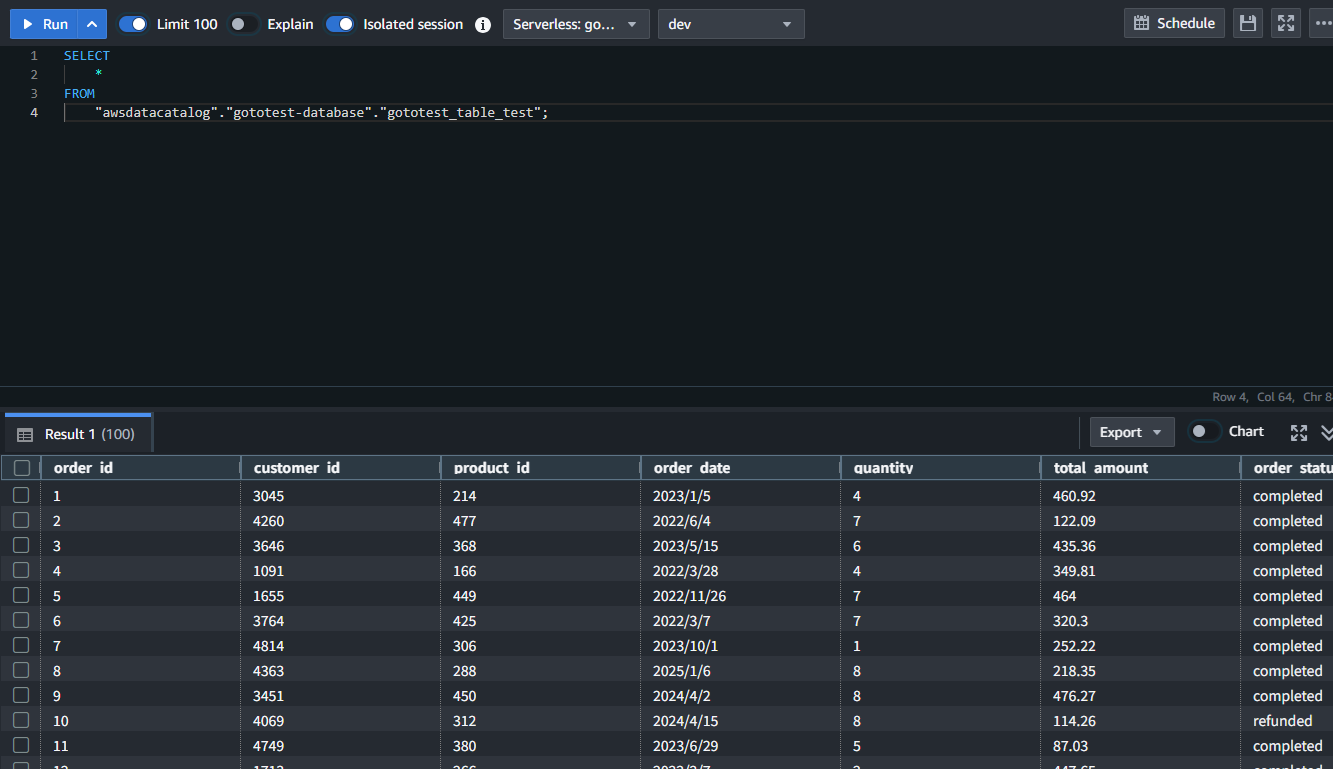
まとめ
いかがだったでしょうか。今回は、RedshiftServerlessによる外部テーブルへのクエリ(Spectrum)を最小権限で実行する方法について紹介しました。
Spectrumを活用することによりRedshiftにデータを保存する必要がなく、代わりにS3をストレージとして利用することができます。
ストレージをS3にするメリットとしてストレージクラスの機能を利用することができます。データのアクセス頻度に応じて適切なクラス設定を行うことでストレージコストを削減することが可能になります。
↓Spectrumによるコスト削減の記事は以下で紹介しているので気になる方はこちらもご覧ください。

もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください。 複雑な内容に関するお問い合わせの場合には直接営業からご連絡を差し上げます。 また、よろしければ以下のリンクもご覧ください!
<QES関連ソリューション/ブログ>
<QESが参画しているAWSのセキュリティ推進コンソーシアムがホワイトペーパーを公開しました>
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。

