記事公開日
【AWS】Glue Crawlerで外部テーブルを作成してみた

はじめに
こんにちは。DXソリューション営業本部の後藤です。
最近Glue Crawlerを触る機会があったのでGlue Crawlerを利用するメリットや作成方法について解説しようと思います。
Glue Crawlerとは
AWS Glue クローラー を使用して、AWS Glue Data Catalog にデータベースとテーブルを入力できます。これは、AWS Glue ユーザーが最もよく使用する基本的な方法です。クローラーは 1 回の実行で複数のデータストアをクロールできます。完了すると、クローラーはデータカタログで 1 つ以上のテーブルを作成または更新します。AWS Glue で定義した抽出、変換、ロード (ETL) ジョブは、これらのデータカタログテーブルをソースおよびターゲットとして使用します。ETL ジョブは、ソースおよびターゲットのデータカタログテーブルで指定されているデータストアに対して読み取りと書き込みを行います。https://docs.aws.amazon.com/ja_jp/glue/latest/dg/crawler-prereqs.html
Glue Crawlerを利用するメリット
手動で外部テーブルを作成する場合、ユーザーがカラム名やデータ型などの定義設定を行う必要があります。
Glue Crawlerを活用することで、その手間を省いて自動でデータをスキャンし、テーブルを作成することが可能になります。
また、一度設定してしまえば指定のCrawlerを実行するだけで更新が可能になります。データの追加などによって発生する面倒な更新作業を自動化することができます。
Glue Crawler作成手順
では実際に作成してみましょう。今回はGUIで設定する方法とCLIで設定する方法の2つについて手順を説明します。
データソースの作成
1.今回、データソースにはS3を使用します。
「バケットを作成」をクリックし任意の名前を入力、その他はデフォルトでS3を作成します。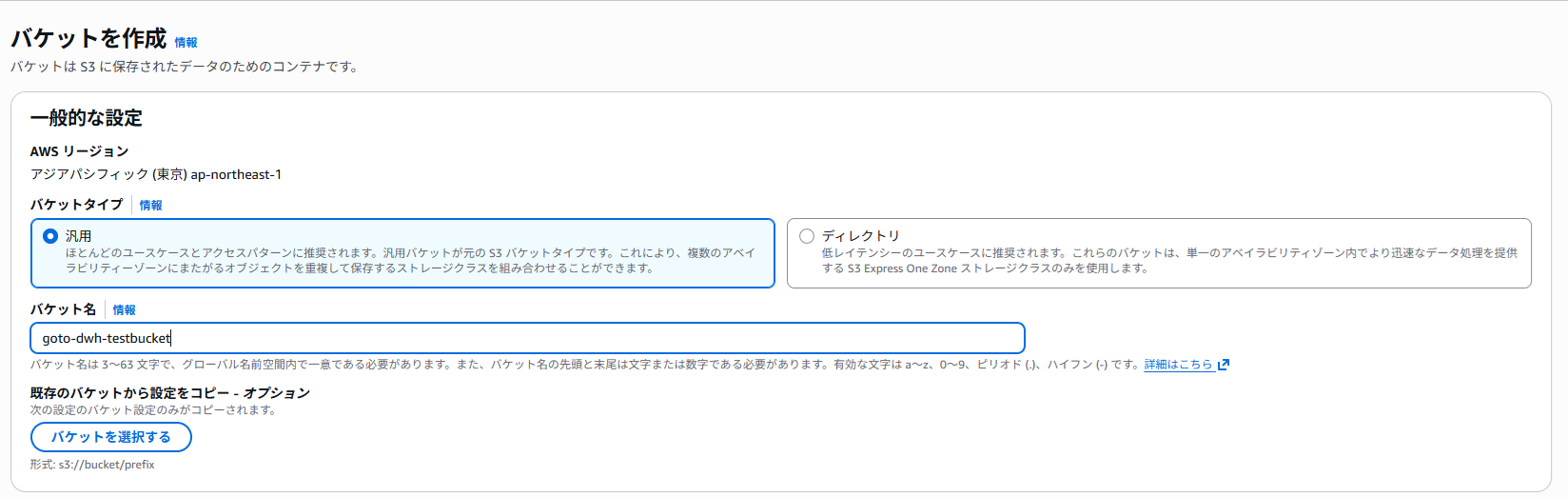
2.「test」フォルダを作成して、その配下に適当なCSVファイルを格納しました。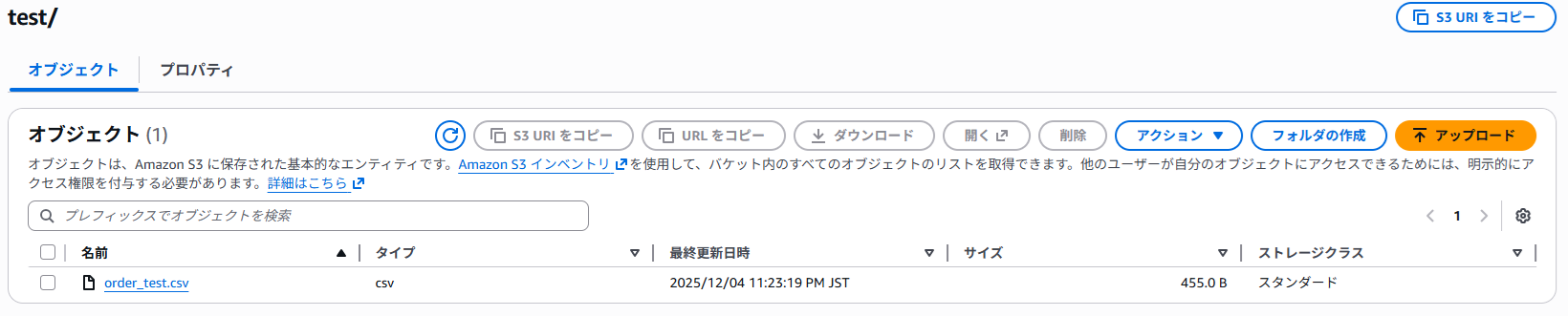
GUIの場合
1.Glue画面の左ペインからGlue Crawlerを選択します。
2.Crawler画面から「Create crawler」を選択します。
3.Crawlerの名前を入力します。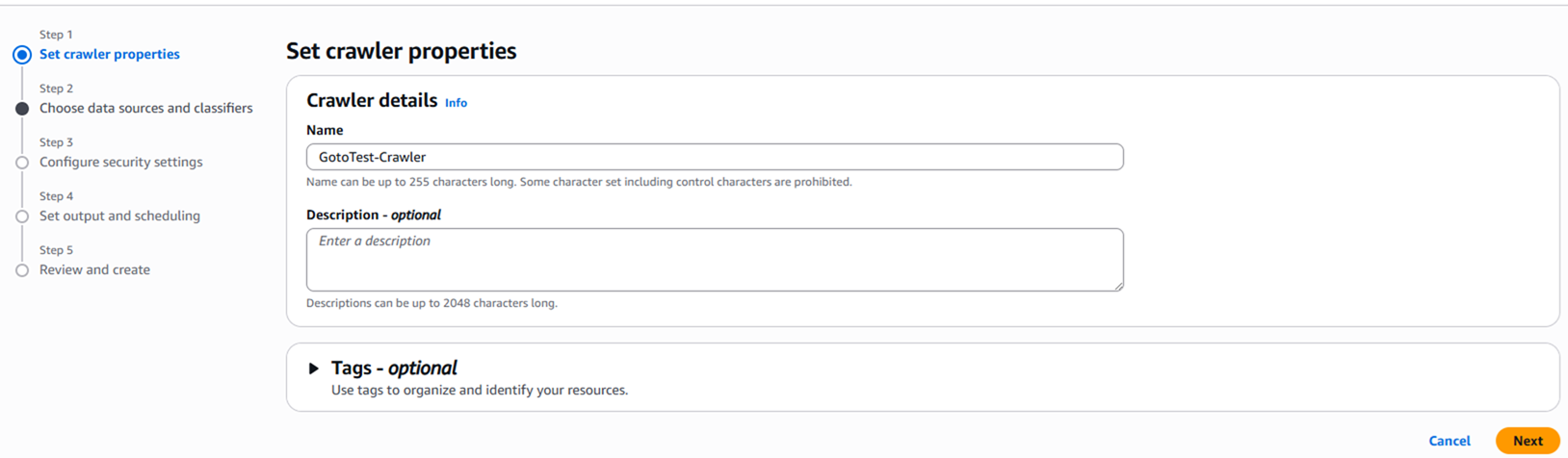
4.データソースの設定を行います。
今回はS3をデータソースにしますので「Not yet」を選択し、「Add a data source」をクリックします。
以下の画面が表示されるので使用するソースデータを選択してください。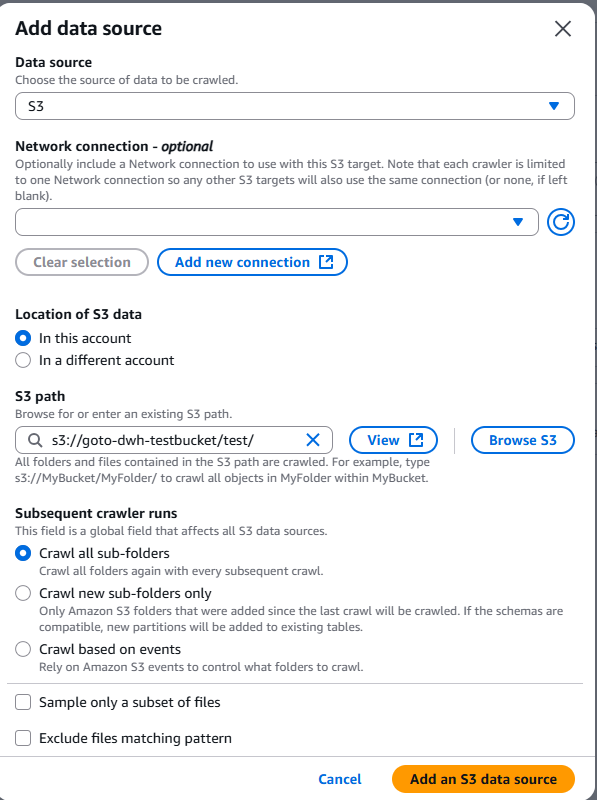
※Glue Crawlerでは2回目以降のクロールの動作方法について選択できます。(Subsequent crawler runs)
・全体クロール(Crawl all sub-folders)
毎実行ごとに対象データをすべて読み込む方法。更新が低頻度の場合は有効。
大容量データでかつ高頻度の場合はコストが大きくなる。
・増分クロール(Crawl new sub-folders only)
追加された新しいパーティションを効率的に検出して、実行する方法。実行時間を短縮でき、コスト削減にもなる。
ただし、既存のパーティションフォルダ内でファイルが変更、追加されても検出されない。
・加速クロール(Crawl based on events)
変更分を検出して実行する方法。S3イベントとSQSを使用する必要がある。S3イベント⇒SQSの連携を設定ののちクローラーを設定する。
2回目以降はSQSへ送ったキューを読み込み変更分だけ更新する。
自分の運用方針によって選択してください。主に更新頻度やデータ容量を考慮して適切に設定してみてください。
今回はテストのため全体クロールを選択しています。
5.Crawler用のIAMロールを設定します。今回は新規で作成します。
セキュリティ要件によりアクセス制御をする場合は事前にIAMロールを作成しておくことをお勧めします。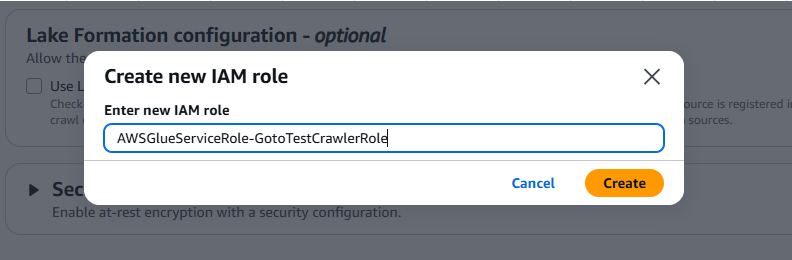
※新規で作成すると以下のポリシーが自動で付与されます。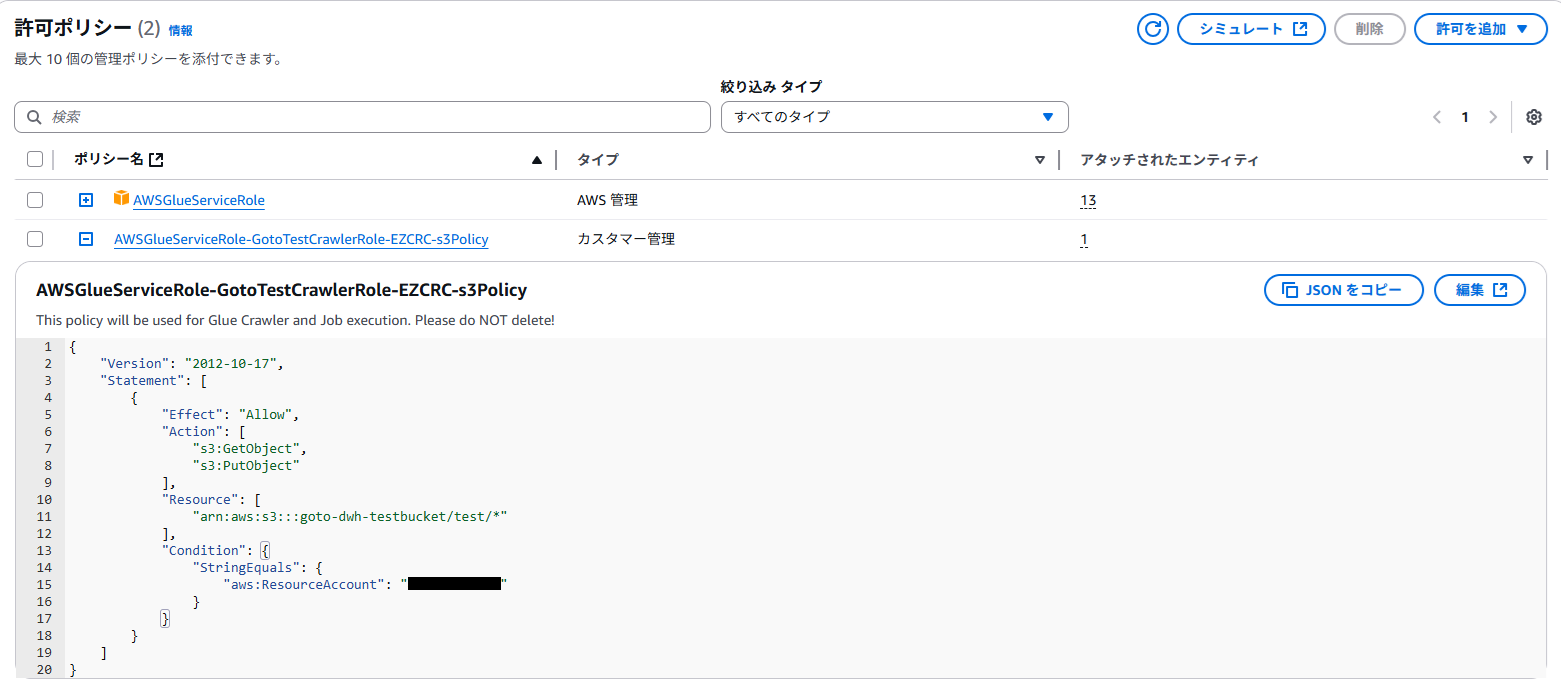
6.次はデータベースを設定します。こちらも新規のデータベースを作成します。
「Add database」をクリックすると新規のデータベースの作成画面へ移行するので入力し作成します。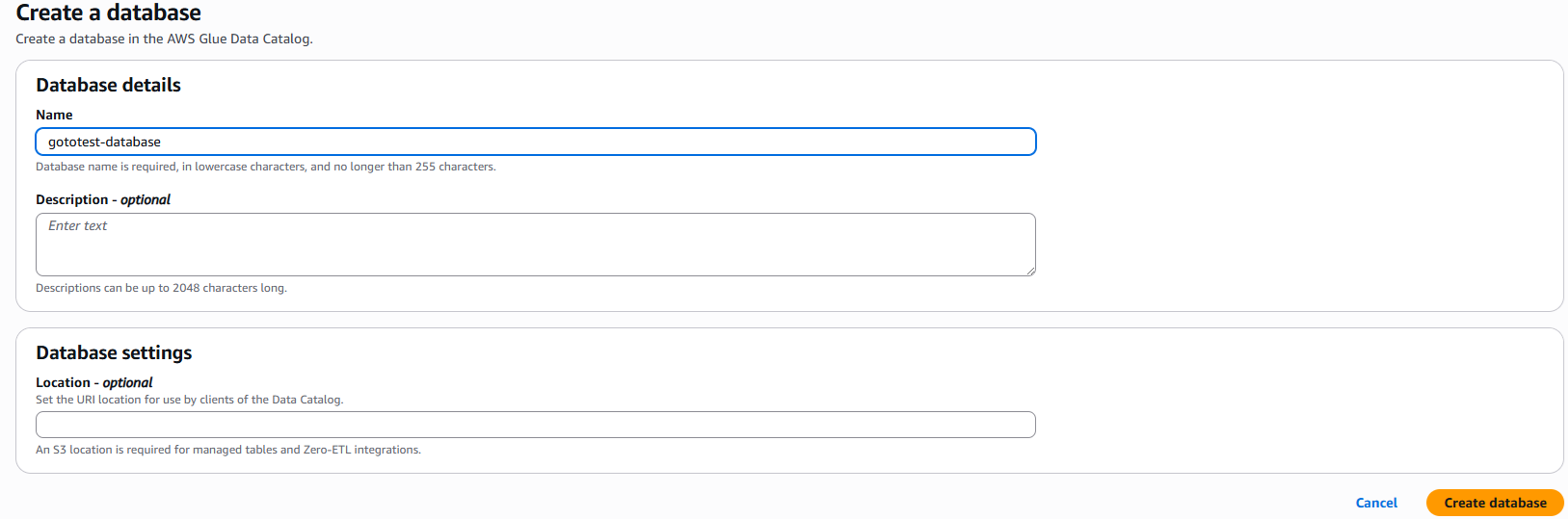
7.作成が完了したら、プルダウンから選択可能になっているので選択します。
Table name prefixに任意の値を入力してください。何も入力しない場合はデータソースのファイル名で自動作成されます。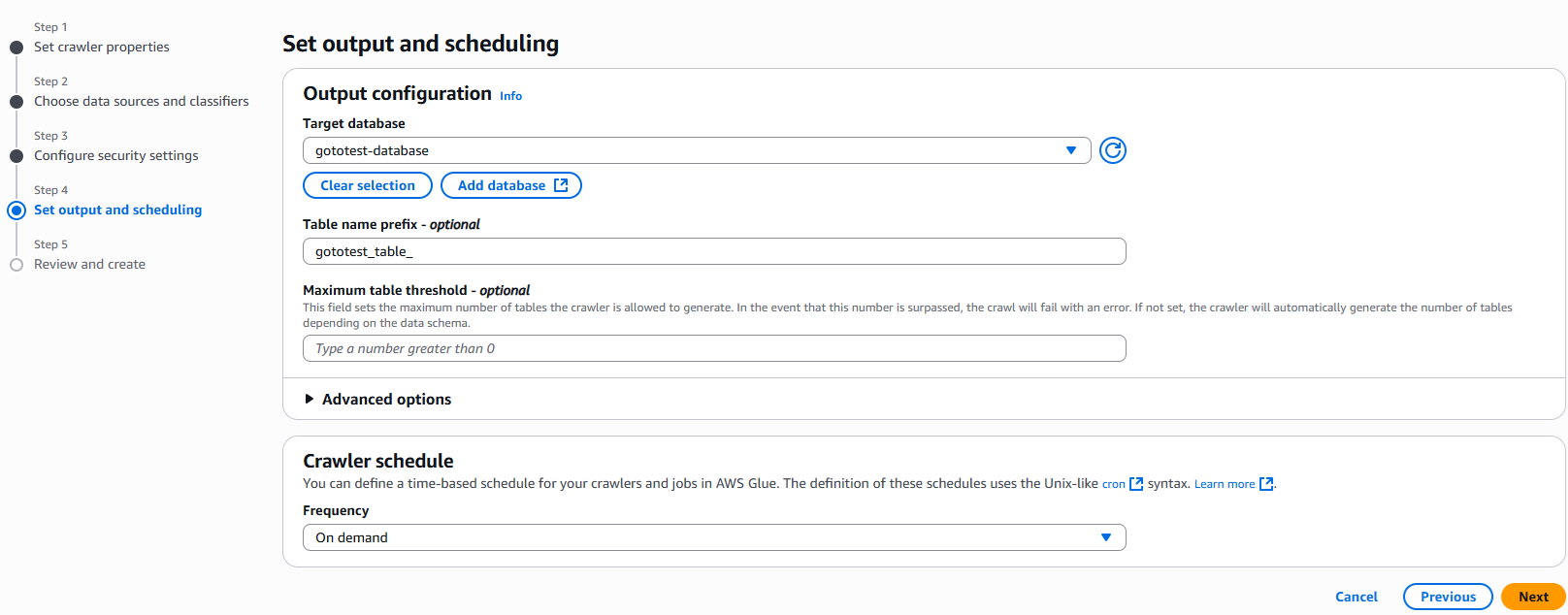
8.「create crawler」をクリック。Glue Crawler画面へ戻ると無事に作成されていることを確認できました。
9.作成したCrawlerを選択し、右上の「Run」で実行してください。問題なく実行が完了すればステータスはcompleteになります。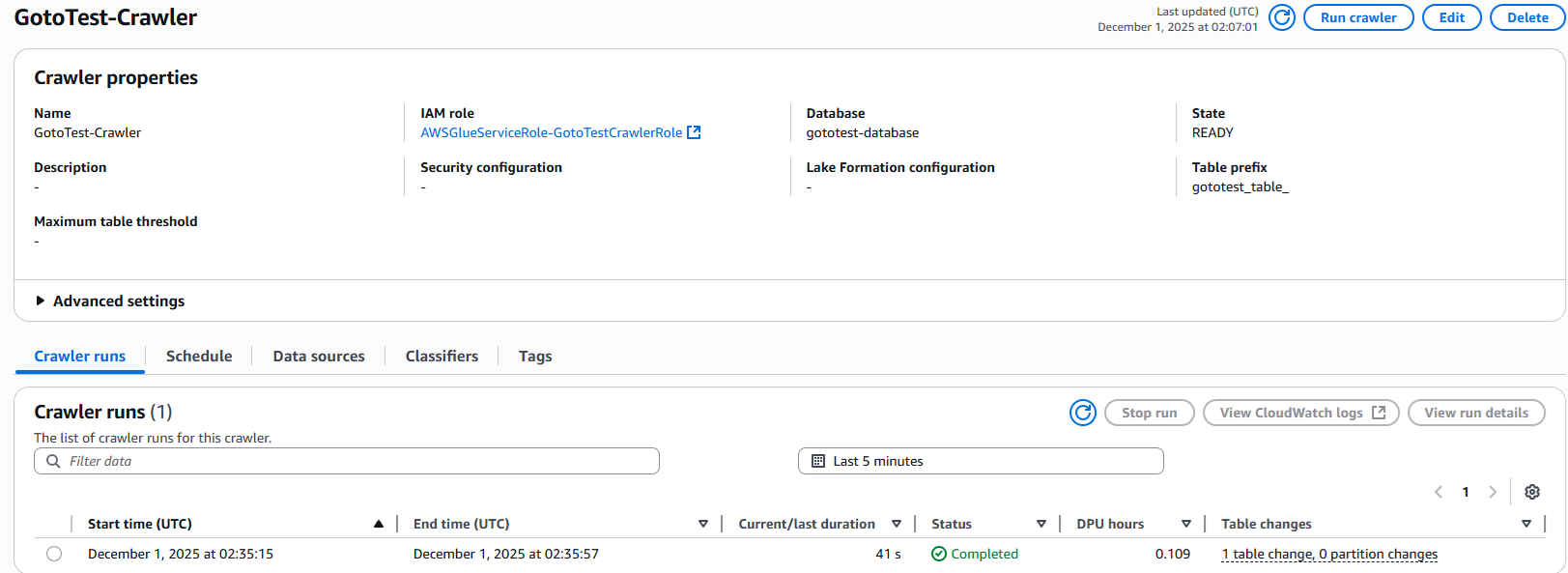
10.Crawlerの実行が完了したら、外部テーブルを確認してみましょう。
左ペインの「Databases」をクリックして作成したデータベースをクリックします。その配下にテーブルが作成されていることが確認できます。
自動でデータソースを読み込み、スキーマを作成してくれていることが確認できました。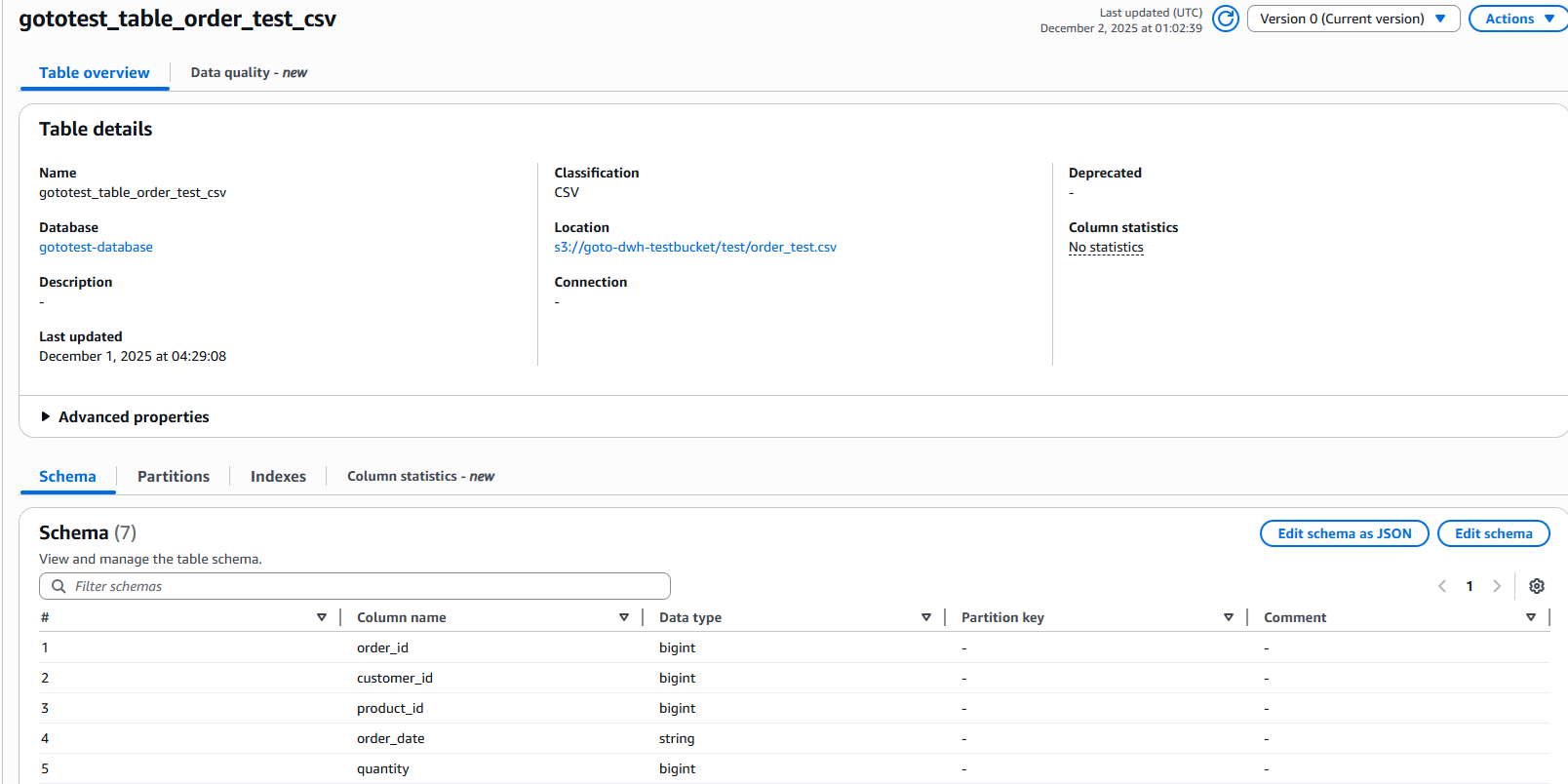
CLIの場合
Glue CrawlerはCLIコマンドでも作成、実行が可能です。CLIでの作成方法について説明します。
1.マネジメントコンソール画面でCloudShellを開きます。
2.公式ドキュメントを参考にコマンドを作成しました。実際に使用する際は以下コマンドを参考に設定値を入力してください。
※IAMロールは事前に作成する必要があります。
aws glue create-crawler \
--name "gototest-s3-data-crawler" \
--role "arn:aws:iam::xxxxxxxx:role/service-role/AWSGlueServiceRole-GotoTestCrawlerRole" \
--database-name "gototest-database" \
--targets '{"S3Targets": [
{
"Path": "s3://goto-dwh-testbucket/test/order_test.csv"
}
]}' \
--recrawl-policy '{"RecrawlBehavior": "CRAWL_EVERYTHING"}'
--name:Crawlerの名前
--role:IAMロールのARN
--database-name:データベースの名前
--targets:データソースのターゲット。
--recrawl-policy:2回目以降のクロール設定。今回は全体クロールを設定。
3.コマンドが無事完了し、Crawlerが作成されていることを確認できました。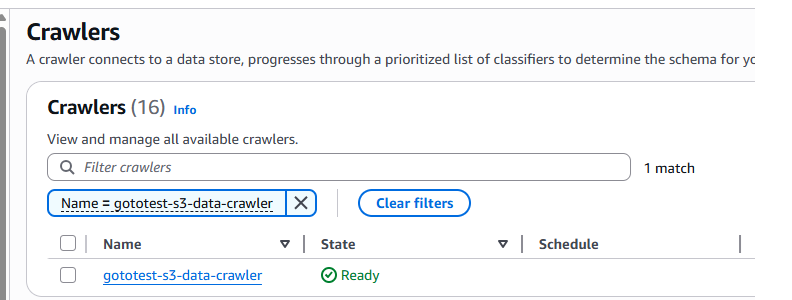
4.Crawlerの作成を確認できたら実行してみましょう。以下コマンドで実行できます。
aws glue start-crawler --name gototest-s3-data-crawler
5.Crawlerの実行が完了したら、作成された外部テーブルを確認してみます。
するとスキーマが自動で作成されていることが確認できました。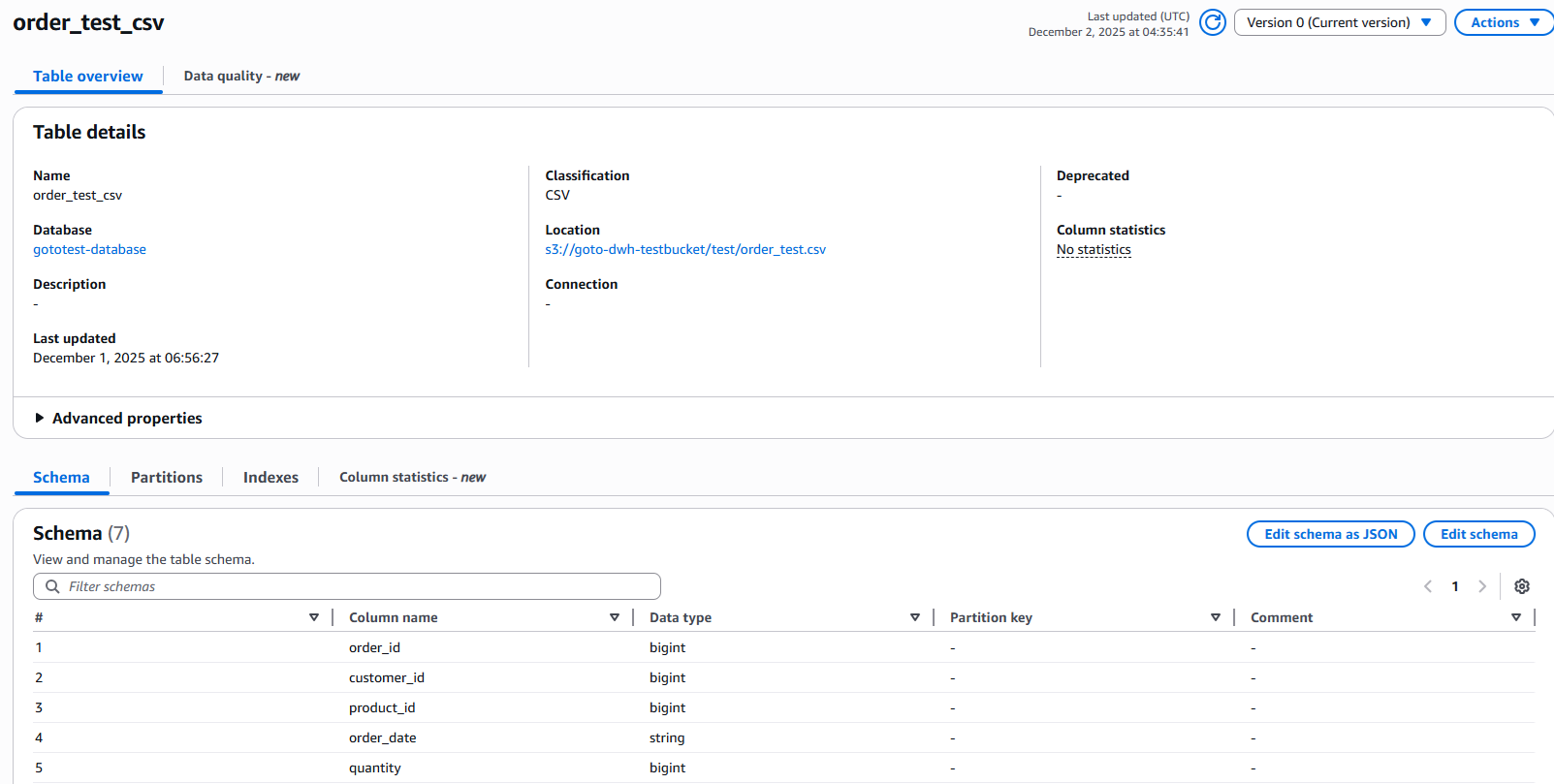
GUIとCLIの使用感
GUIとCLIを使用してみてそれぞれ以下のようなメリット・デメリットがあると感じました。
GUI
メリット:直観的な操作が可能。主に初めて作成する場合やCrawlerを理解するのに最適。
デメリット:再現性が低い。例えば同じようなルールでCrawlerを複数作成したい場合などにその都度手動で作成する必要があり手間がかかる。実行に関しても同じく時間がかかる。
CLI
メリット:再現性が高い。同じようなルールでCrawlerを作成したい場合などに最適。作成時間の短縮になり、同時にヒューマンエラーも減らせる。
デメリット:視覚的な情報がないためある程度Crawlerへの知識がある前提となる。
私見としては、PoC環境などでテスト実行やCrawlerの使用感を確認したい場合にはGUI。複数のCrawlerを使用するような大規模な環境ではスクリプトによる一貫性のあるCLIがおすすめだと思います。
まとめ
いかがだったでしょうか。今回は、データソースのメタデータを読み込み外部テーブルを作成するGlue Crawlerについて紹介しました。
Glue Crawlerを活用することで外部テーブルの定義設定や更新作業にかかる時間を大幅に短縮することができます。
データ分析環境において非常に便利なサービスになっていますので、ぜひ導入を検討してみてください。
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください。 複雑な内容に関するお問い合わせの場合には直接営業からご連絡を差し上げます。 また、よろしければ以下のリンクもご覧ください!
<QES関連ソリューション/ブログ>
<QESが参画しているAWSのセキュリティ推進コンソーシアムがホワイトペーパーを公開しました>
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。

