記事公開日
最終更新日
第8回 オープンデータを利用した予測/分類 (2/3)
2.1. データセットのアップロード
保存したCSVファイルをAzure Machine Learningへアップロードします。
① まず、Azure Machine Learningへサインインし、「Datasets」タブをクリックします。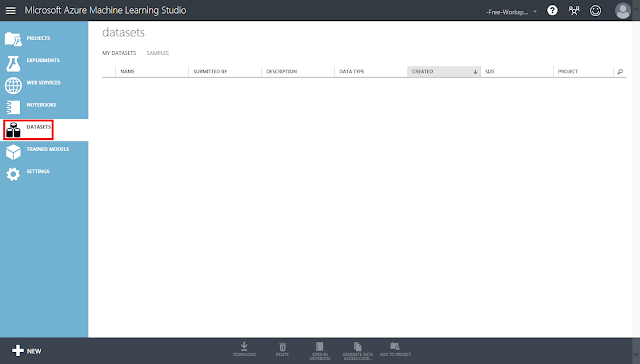
② 左下にある「+NEW」ボタンをクリックし、開いたパネルにある「FROM LOCAL FILE」をクリックします。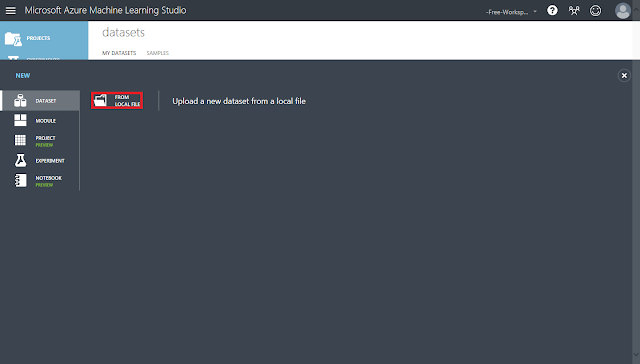
③ ダイアログボックスが表示されたら、「参照」ボタンをクリックして、作成したCSVファイルを選択します。ここでは「rice.csv」とします。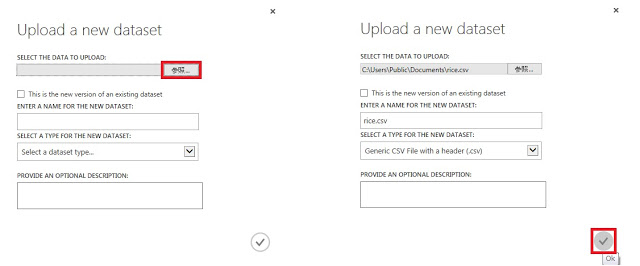
④ 「☑OK」ボタンをクリックし、「Upload of the dataset ‘rice.csv’ has complete.」と表示されるまで待ちます。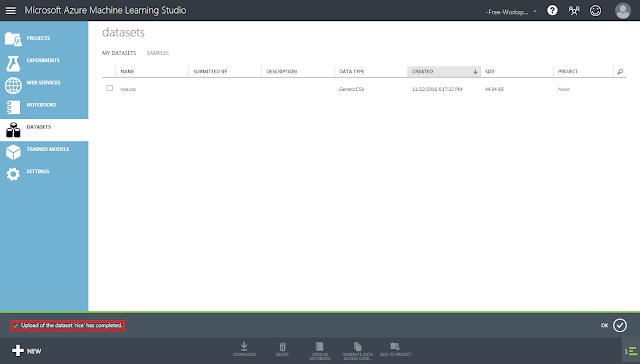
⑤ データセットが正常にアップロードされたか確認するために、中身をJupyter notebookで表示させてみます。Jupyter notebookは、ソースコードの入力と結果の確認をブラウザ上で行うことができるツールです。
アップロードした「rice.csv」を選択し、画面下部にある「OPEN IN NOTEBOOK」をクリックして開いたメニューの「R」をクリックします。
⑥ すると新しいタブにJupyter notebookが表示されます。
データセットを読み込むソースコードと、読み込まれたデータセットに含まれるデータの先頭6件を表示させるためのソースコードが予めテキストボックスに表示されているので、画面上部のツールバーにある「run cell, select below」ボタンを2回クリックします。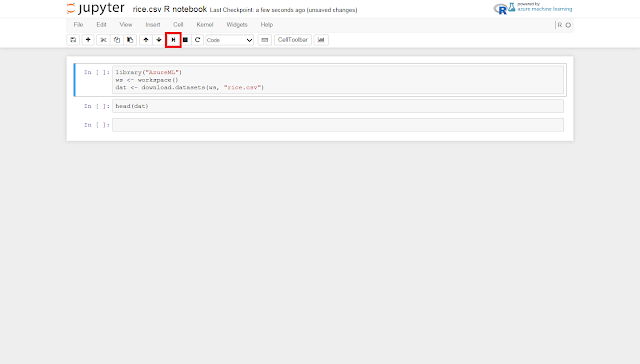
⑦ 表にデータセットの先頭6件のデータが表示されていることを確認します。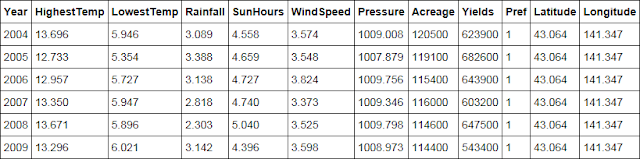
⑧ 続いて、データセットの配置先となる実験を作成します。
左側のパネルにある「Experiments」タブをクリックし、左下にある「+NEW」ボタンをクリックしたあと、「Blank Experiment」をクリックします。
⑨ 実験画面が開きます。以前作成した実験と区別しやすいように実験の名称を変更しておきます。灰色領域の一番上にある文字列をクリックすると編集できます。
⑩ 「Saved Datasets」→「My Datasets」→「rice.csv」を、灰色領域に配置します。
この後の手順では、配置したこのモジュールから線を結んでいき学習を行わせることになります。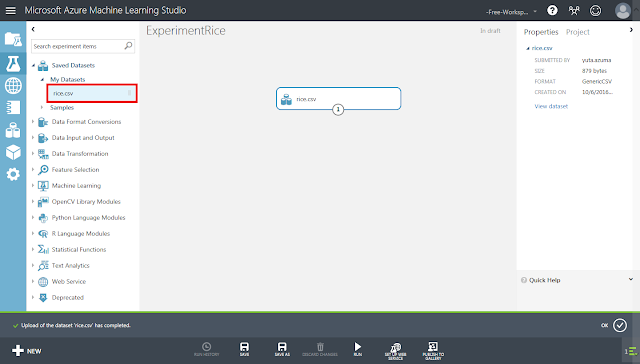
2.2. データの事前準備
2.2.1. 変数選択
前回までの記事で、Azure Machine Learningの「Select Columns in Dataset」モジュールを使用して特定のデータ列(=変数、特徴量)だけ通過させて、新たなデータセット(モデル)を作る場面が何度かありました。このような操作を変数選択と呼びます。変数選択には、以下のような手法があります。
これらのうち、最も計算量が少なくて済むのが変数指定法です。対象となるデータセットに関する予備知識があり、特徴量と予測量の因果関係が明確な場合に使用されます。
データセットに関する知識がない場合、最も精度が高くなり得るのが総当たり法です。しかしながら、特徴量(データ列)の種類が増加するとともに特徴量の組み合わせの種類も増加し、結果として全体の計算量が膨大なものとなるため、実用的ではありません。そこで、総当たり法よりも計算量を削減しながらもある程度の精度を保つために、逐次選択法によって変数選択を行うことが一般的になっています。逐次選択法は、開始したときの状態と繰り返しのときの手順の違いによって以下の4種類に分けられます。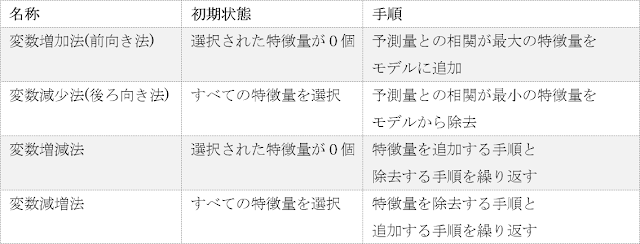
例えば、変数増減法によって変数選択を行う手順は以下の通りです。
変数増加法のような繰り返し特徴量を入れ替えて計算する手法の場合は、分散比(F値)や寄与率( )、赤池の情報量基準(AIC)といった指標によって特徴量の増減前後の性能を比較することで終了するタイミングを求めます。これらの指標値の算出方法についてはここでは割愛しますが、F値は、大きければ大きいほど変数同士の相関が高いことを、寄与率は、1に近ければ近いほど精度がよい学習モデルであることを、AICは、小さければ小さいほど精度がよい学習モデルであることを示すということだけ覚えておいていただければと思います。
これらの手法のうちAzure Machine Learningそのものには、変数指定法以外の手法を明示的に行うためのモジュールは用意されていません。そのため、Azure Machine Learningの実験の中で使用するためには独自のソースコードを実行する必要があります。今回は「Execute R」モジュールを使用してR言語のstep関数を実行してみます。Step関数はRの標準ライブラリに含まれているため、追加のzipファイルをアップロードすることなく、ソースコードを書くだけで呼び出すことができます。以下に、Azure Machine Learning上でstep関数による変数選択を行うための操作手順を示します。
まず、実験の完成イメージを示します。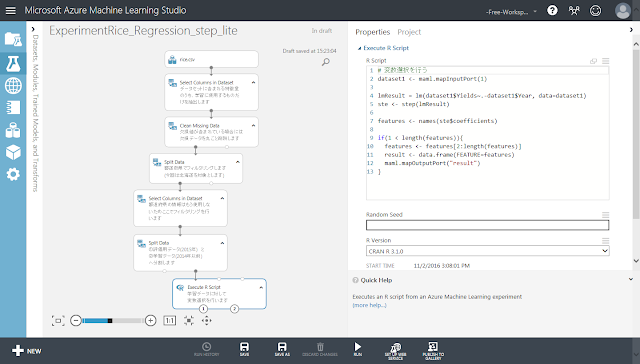
続いて以下に、操作手順を示します。途中までは、学習ロジックを作成する手順とほぼ同じ流れとなります。
最初に、学習対象のデータセットをアップロードします。データセットタブを開き、左下のNewボタンをクリックします。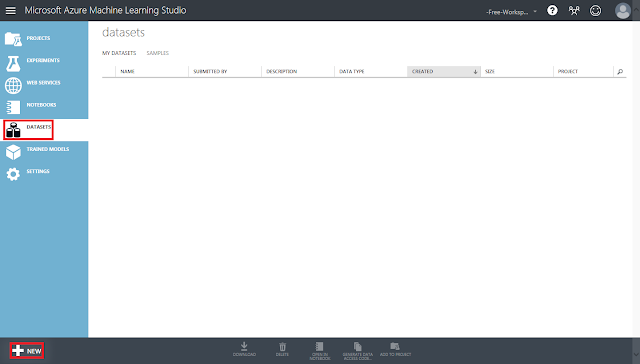
「From Local File」をクリックします。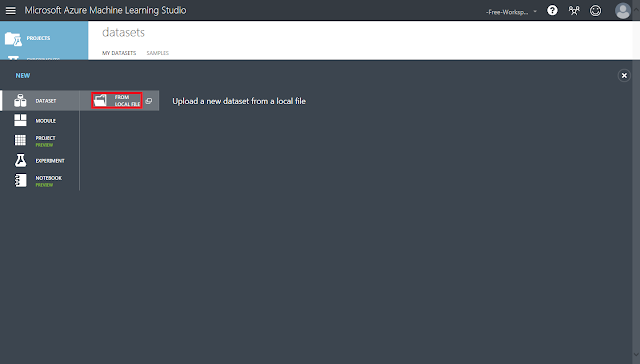
参照ボタンをクリックし、ローカルにあるCSVファイルを指定します。ファイルを指定したら「☑OK」ボタンをクリックします。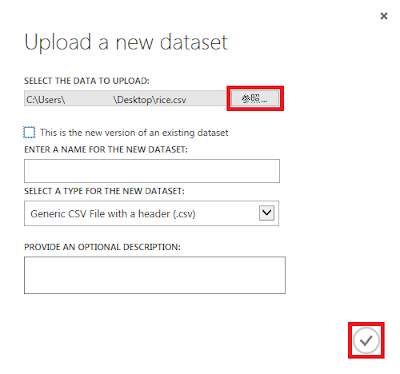
アップロードされたことを確認します。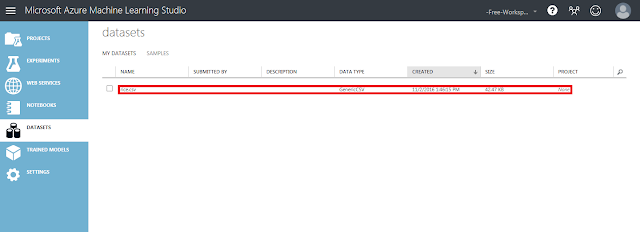
「Experiments」タブを開き、左下の「+New」ボタンをクリックします。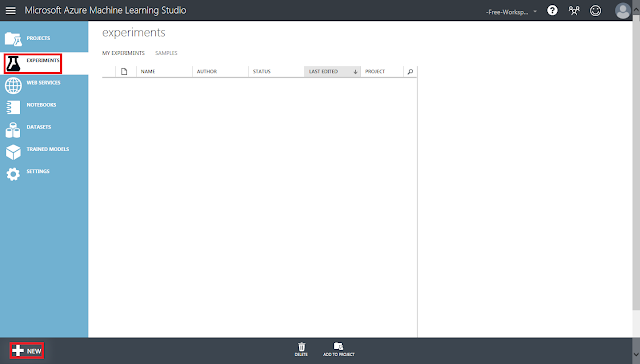
「Blank Experiment」をクリックします。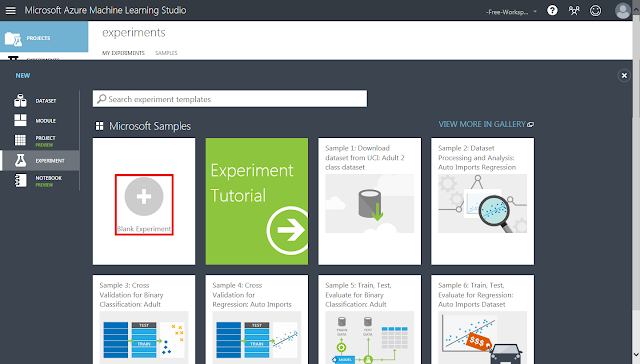
実験の画面が開いたら、モジュールを配置していきます。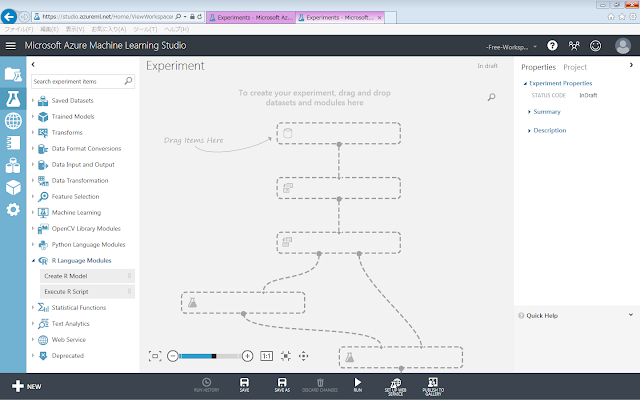
アップロードしたデータセットのモジュールを配置します。左側のパネルにある、「Saved Datasets」→「My Datasets」→「rice.csv」を画面中央の灰色領域にドラッグアンドドロップします。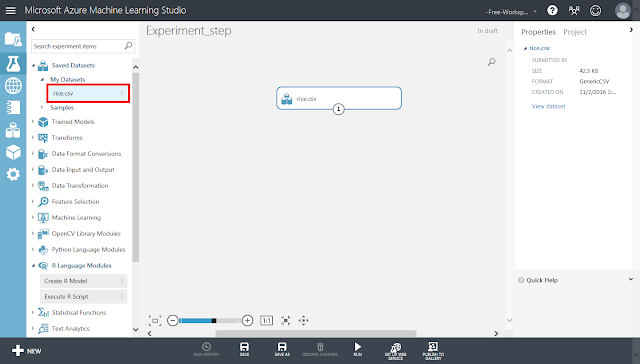
続いて、「Select Columns in Dataset」モジュールを配置します。その後、rice.csvモジュール下部の丸印から「Select Columns in Dataset」モジュールに向かってドラッグアンドドロップし、線で結びます。「Select Columns in Dataset」モジュールの右側に警告アイコンが表示されますが、そのまま「Select Columns in Dataset」モジュールが選択された状態で右側のパネルにある「Launch column selector」ボタンをクリックします。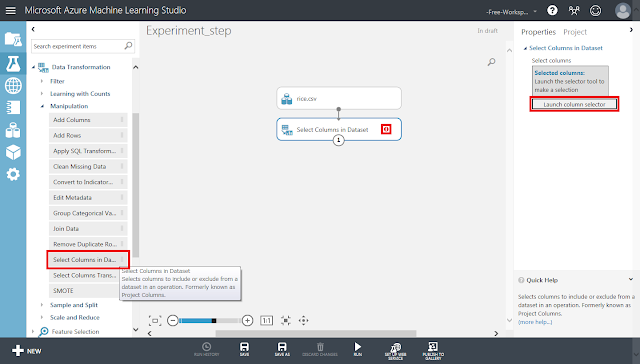
開いた画面で、学習に使用するデータ列と事前処理に使用するデータ列を選択します。ここでは例として、事前処理で「北海道」のデータだけをフィルタリングし、気象条件だけを学習させてみます。
「Year」から「Pref」までのアイテムを選択した後に「>」ボタンをクリックし、「☑OK」ボタンをクリックします。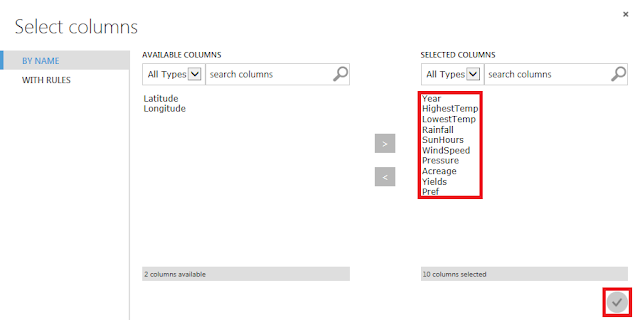
「Data Transformation」→「Manipulation」→「Clean Missing Data」モジュールを配置し、「Select Columns in Dataset」モジュールから線で結びます。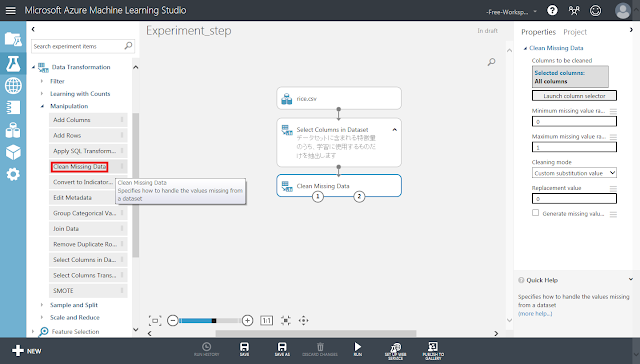
「Clean Missing Data」モジュールが選択された状態で右側のパネルにある「Cleaning mode」リストの値を「Remove entire row」へ変更します。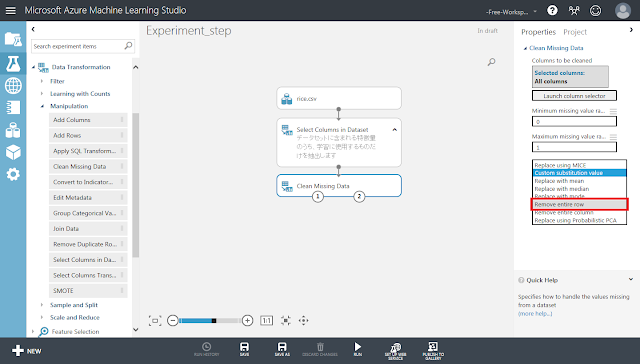
続いて「北海道」のデータだけフィルタリングして抽出します。
「Data Transformation」→「Sample and Split」→「Split Data」モジュールを配置し、「Clean Missing Data」モジュールの左下の丸印から線で結びます。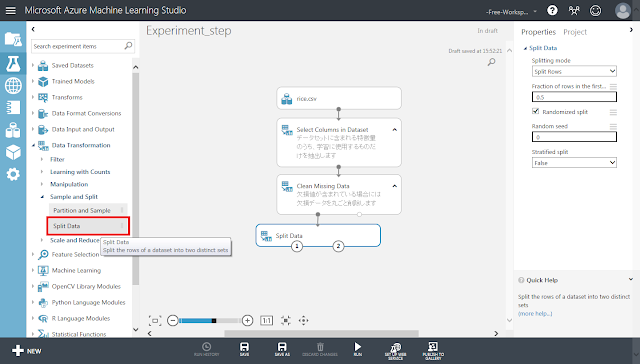
「Split Data」モジュールが選択された状態で右側のパネルにある「Splitting mode」リストの値を「Regular Expression」へ変更します。また、「Regular Expression」テキストボックスに「\”Pref” 1」と入力します。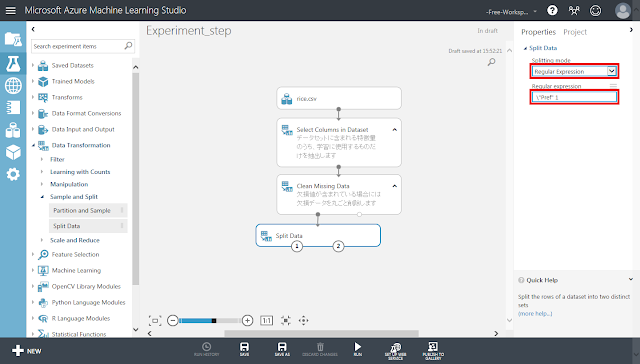
次に、フィルタリングのために残しておいたものの学習には使用しないデータ列である「Pref」列を除去します。
「Select Columns in Dataset」モジュールを配置します。その後、「Split Data」モジュール左下の丸印から「Select Columns in Dataset」モジュールに向かってドラッグアンドドロップし、線で結びます。「Select Columns in Dataset」モジュールの右側に警告アイコンが表示されますが、そのまま「Select Columns in Dataset」モジュールが選択された状態で右側のパネルにある「Launch column selector」ボタンをクリックします。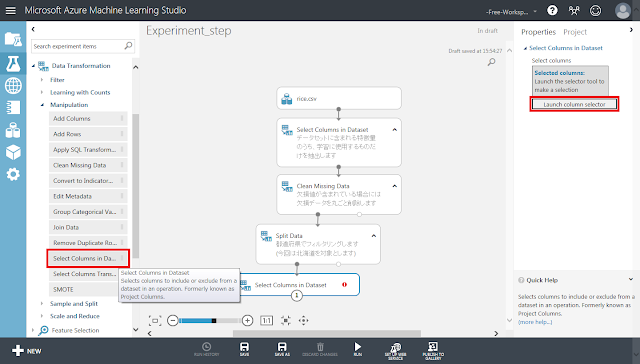
以下のような画面が開きます。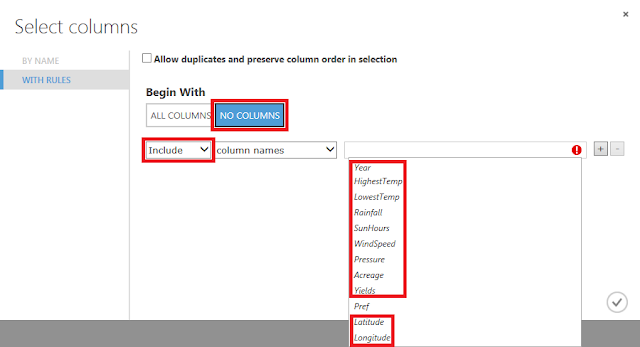
「Begin With」に「NO COLUMNS」が選択されていることを確認し、「column names」に「Pref」列以外のものを指定し、「☑OK」ボタンをクリックします。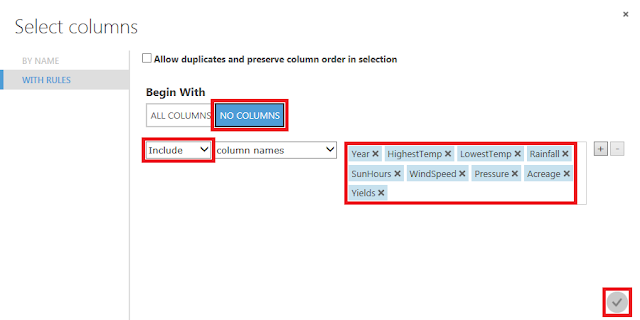
上記の手順を行うと、対象のデータ列が何も登録されていない状態にデータ列を1つずつ追加していく流れになりますが、「Begin With」に「ALL COLUMNS」を指定して「Pref」列だけを除外するという方法もあります。その場合は以下のような表示となります。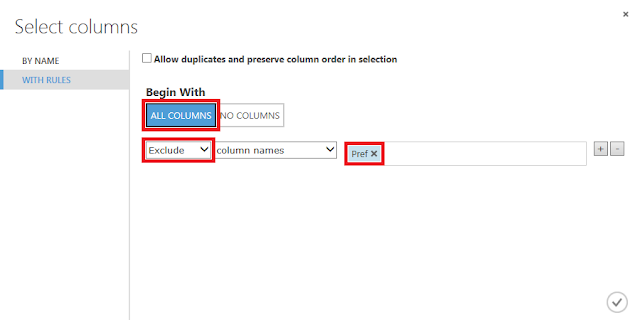
続いて、学習用データと評価用データを分割します。今回は、2014年以前のデータを学習させて、2015年のデータを予測(評価)させるので、「Year」列が2015のデータとそうでないデータとに分割することになります。
「Data Transformation」→「Sample and Split」→「Split Data」モジュールを配置し、「Select Columns in Dataset」モジュールの下部の丸印から線で結びます。
「Split Data」モジュールが選択された状態で右側のパネルにある「Splitting mode」セレクトメニューの値を「Regular Expression」へ変更します。また、「Regular Expression」テキストボックスに「\”Year” ^2015」と入力します。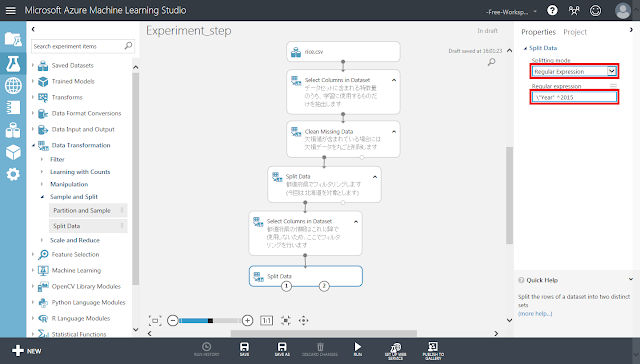
次に、評価用データと学習用データを分割するために残しておいたものの、学習には使用しないデータ列である「Year」列を除去します。
「Select Columns in Dataset」モジュールを配置します。その後、「Split Data」モジュール右下の丸印から「Select Columns in Dataset」モジュールに向かってドラッグアンドドロップし、線で結びます。「Select Columns in Dataset」モジュールの右側に警告アイコンが表示されますが、そのまま「Select Columns in Dataset」モジュールが選択された状態で右側のパネルにある「Launch column selector」ボタンをクリックします。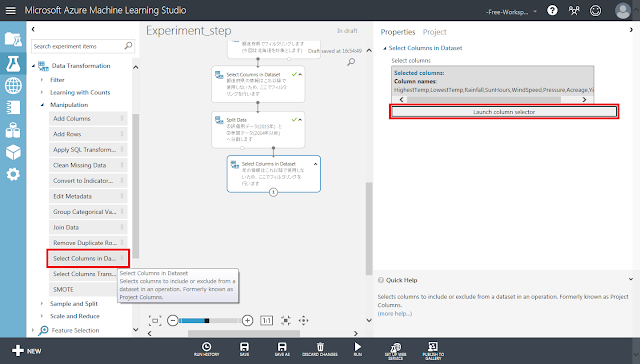
「Begin With」に「NO COLUMNS」が選択されていることを確認し、「column names」に「Year」列以外のものを指定し、「☑OK」ボタンをクリックします。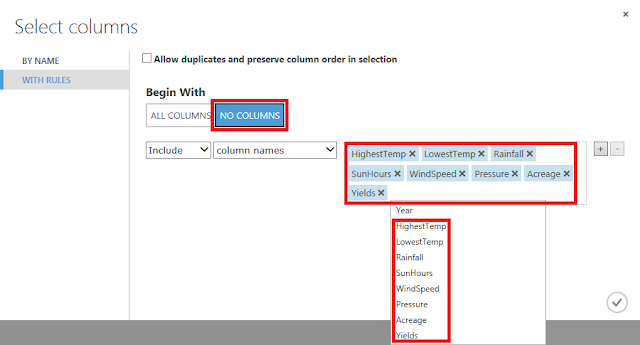
Rのstep関数を用いて変数選択を行うためのモジュールを設定します。
「Execute R Script」モジュールを配置します。その後、「Select Columns in Dataset」モジュール右下の丸印から「Execute R Script」モジュールに向かってドラッグアンドドロップし、線で結びます。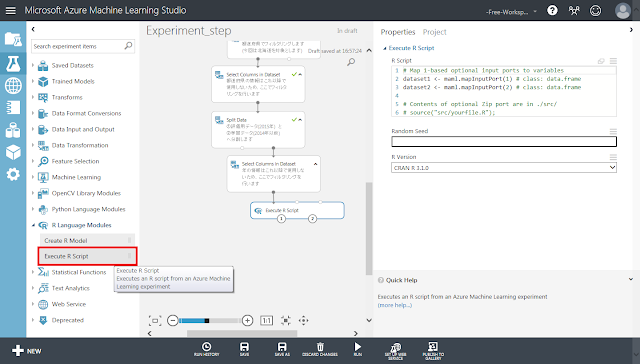
「Execute R Script」モジュールが選択された状態で右側のパネルの「R Script」テキストエリアをクリックすると、以下のようにテキストエリアの領域が広がります。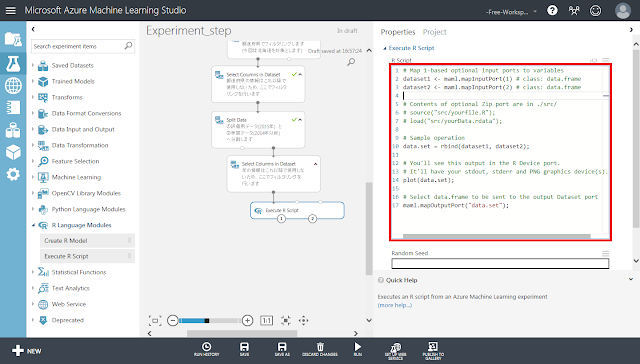
テキストエリアの中に記述されている既存のソースコードを削除した後、以下のソースコードを入力します。
|
# 変数選択を行います
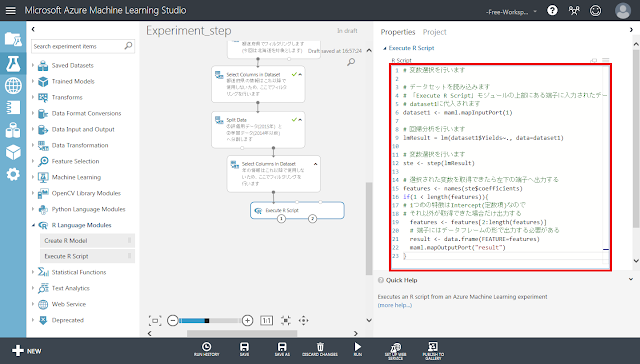
# データセットを読み込みます # 「Execute R Script」モジュールの上部にある端子に入力されたデータが # dataset1に代入されます dataset1 <- maml.mapInputPort(1)
# 回帰分析を行います lmResult = lm(dataset1$Yields~., data=dataset1)
# 変数選択を行います ste <- step(lmResult)
# 選択された変数を取得できたら左下の端子へ出力する features <- names(ste$coefficients) if(1 < length(features)){ # 1つめの特徴はIntercept(定数項)なので # それ以外が取得できた場合だけ出力する features <- features[2:length(features)] # 端子にはデータフレームの形で出力する必要がある result <- data.frame(FEATURE=features) maml.mapOutputPort("result") } |
「Run」メニューをクリックします。
「Execute R Script」モジュールまで黄緑色のチェックマークが表示されるまで待ちます。
「Execute R Script」モジュール左下にある丸印をクリックすると現れるメニューの「Visualize」をクリックして、選択結果を確認します。
入力されたデータセットにある変数のうち、重要なものから順にリスト表示されます。つまり、この結果の上位にある変数だけで学習させることで、学習速度を低下させることなく精度良く結果を求めることができるようになる可能性があります。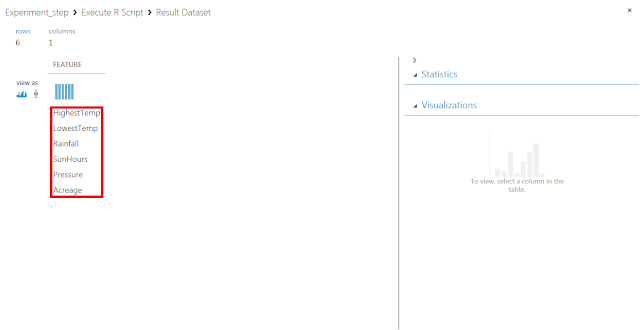
「Visualize」メニューを実行した結果では最終的な計算結果しか確認することができませんが、「Execute R Script」モジュールが選択された状態で、右側パネルにある「View output log」リンクをクリックすると、計算過程で出力されたログを確認することができます。
step関数の処理内容をログで確認してみましょう。「Execute R Script」モジュールで記述したソースコード内のstep関数では、引数に対象モデル以外のパラメーターを指定していないため、変数増減法が選択されます。本項冒頭にある、変数増減法の処理手順の例もご参照ください。
① はじめに「Start: AIC=****.*」という行を検索します。
|
[ModuleOutput] Start: AIC=2935.2 |
② その行のすぐ下に回帰式「dataset1$Yields ~ HighestTemp + LowestTemp + Rainfall + SunHours + WindSpeed + Pressure + Acreage」が表示されています。これは、HiestTempからAcreageまでのすべての列を入力した場合を基準としてAICの値を算出した上で、変数を増減させた式で算出したAICの値と比較することを表しています。
|
[ModuleOutput] dataset1$Yields ~ HighestTemp + LowestTemp + Rainfall + SunHours + WindSpeed + Pressure + Acreage |
③ さらに下に表示されている表を見ると、②で示された基準の回帰式から変数を除去したり(行頭にマイナスがある行)、追加したり(行頭にプラスがある行)して算出したAICの値が表示されています。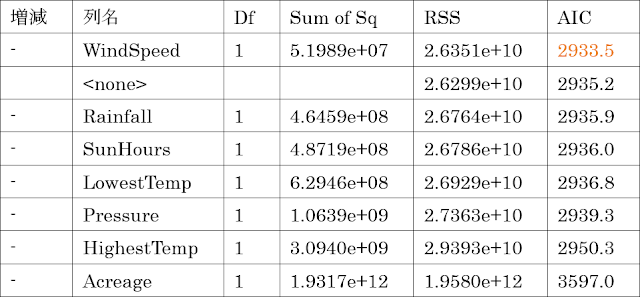
④ ③の表に示されたAICの値のうち、最小のものは「WindSpeed」を除去したものから求めた値(2933.5)なので、次のステップでは、②で示された基準の回帰式から「WindSpeed」を除去したものを新たな基準の式として、そこから変数を増減させてAICの値を比較することになります。そのことを表すのが以下の2行です。
|
Step: AIC=2933.5 |
|
[ModuleOutput] dataset1$Yields ~ HighestTemp + LowestTemp + Rainfall + SunHours + Pressure + Acreage |
|
|
|
(②の式と比較すると「WindSpeed」が除去されている) |
⑤ 2つ目の表を見てみると、変数を増減させたときの7つのAICの値よりも変化させなかったときのAICの値(2933.5)のほうが小さいため、繰り返し手順を終了して、回帰式に存在する変数(=列)を変数選択の結果として出力します。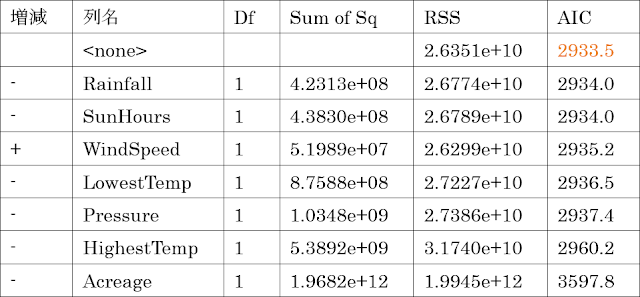
「Execute R Script」モジュールをコピーアンドペーストし、「Select Columns in Dataset」モジュールからすべてのモジュールへ接続した後に、スクリプト中に記述されたstep関数の引数を書き換えることで各手法を同時に比較することもできます。
3手法で結果を比較した表を以下に示します。いずれも大まかな傾向は一致しています。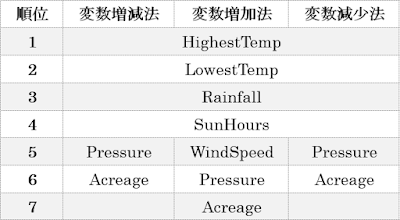
2.2.2. 欠損データの除去
続いて、欠損値を含むデータを除去します。今回も、データセット内に欠損値を含むデータがあったらデータ(行)をまとめて削除する「リストワイズ法」により処理します。まず「Clean Missing Data」モジュールを配置し、「rice.csv」モジュールから接続します。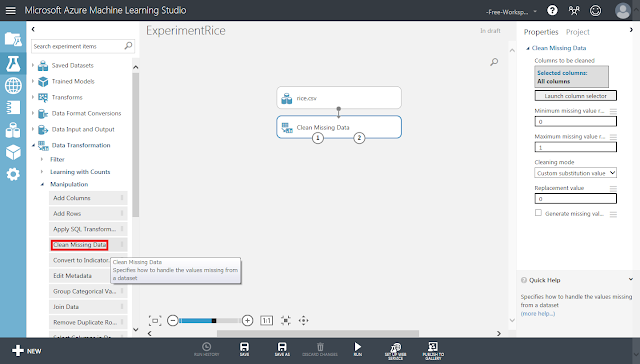
そして「Clean Missing Data」モジュールが選択された状態で、右側にある「Cleaning mode」セレクトメニューの値を「Remove entire row」へ変更します。これが「リストワイズ法」での処理を指定する箇所になります。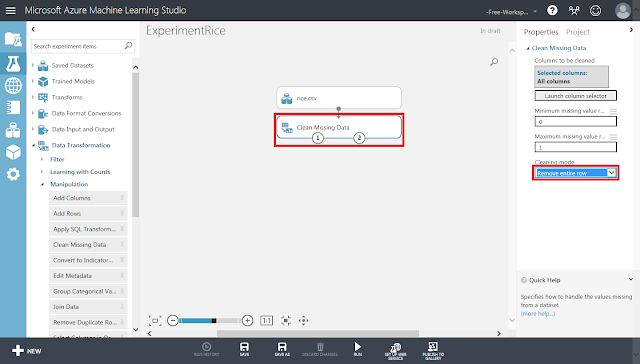
「Cleaning mode」セレクトメニューの値には、「Remove entire row」の他にも以下のような種類があります。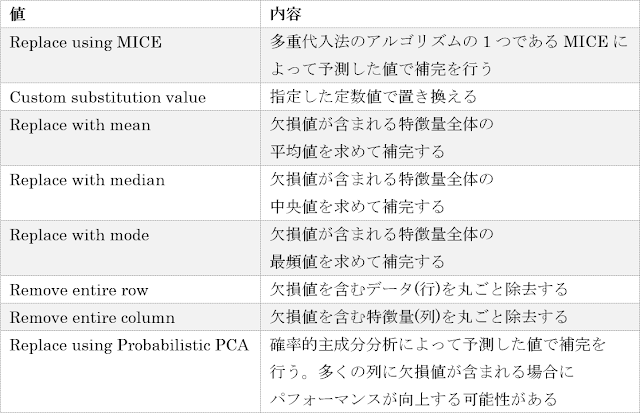
2.2.3. データセットの分割
評価用データと学習用データに分割します。
まず、「Split Data」モジュールを配置します。
「Split Data」モジュールが選択された状態で、右側のパネルにある「Splitting mode」リストの「Regular Expression」を選択した後、「Regular Expression」テキストボックスに「\"Year" ^2015」と入力します。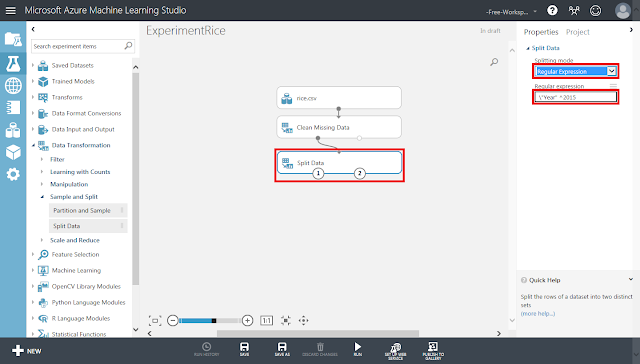
画面下部の「SAVE」ボタンをクリックして、一度保存しておきます。
画面下部にある「Run」ボタンをクリックして、処理を実行します。
実行が終わった後、「Split Data」モジュールの左下の丸印のメニューにある「Visualize」をクリックします。
「Year」列の値が「2015」のデータだけ抽出されていることを確認します。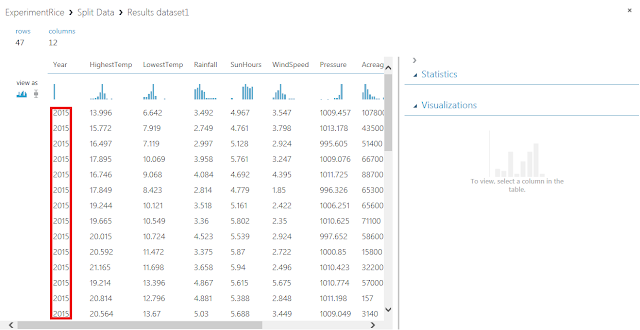
評価用データセットと学習用データセットが①と②のどちらの端子から出力されるかが紛らわしいので、「Split Data」モジュールにコメントとして記入しておきます。「Split Data」モジュール自体の右クリックメニューにある「Edit Comment」メニューをクリックします。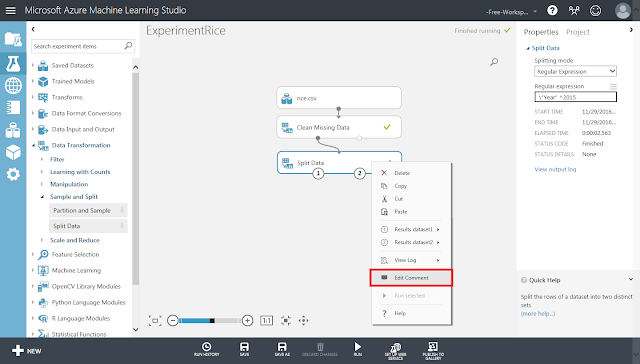
「Split Data」モジュールの下にテキストボックスが表示されるので、コメントを入力します。今回は、「①評価用データと②学習用データへ分割します」と入力しました。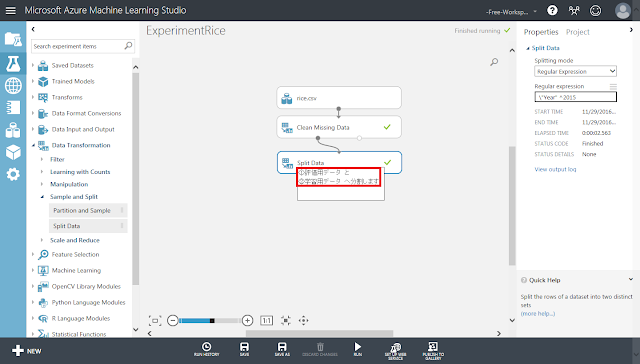
「Split Data」モジュールの内部に、入力したコメントが表示されていることを確認します。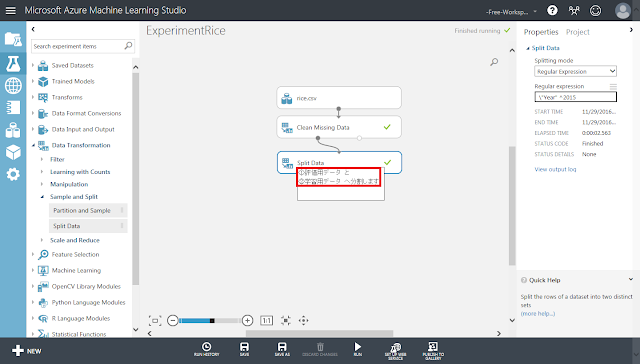
2.3. 学習ロジックの作成と実行
実験の主処理である回帰分析の部分を組み立てていきます。まず、線形回帰のための初期化モジュール「Linear Regression」を配置します。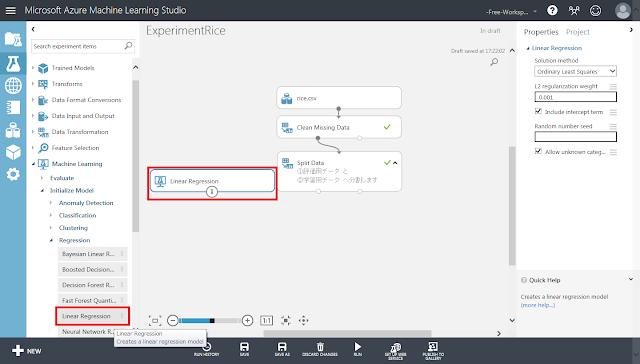
続いて、「Train Model」モジュールを配置した後、「Linear Regression」モジュールから「Train Model」モジュールの左上の丸印へ、「Split Data」モジュール右下の丸印(学習用データ)から「Train Model」の右上の丸印へ、それぞれ接続します。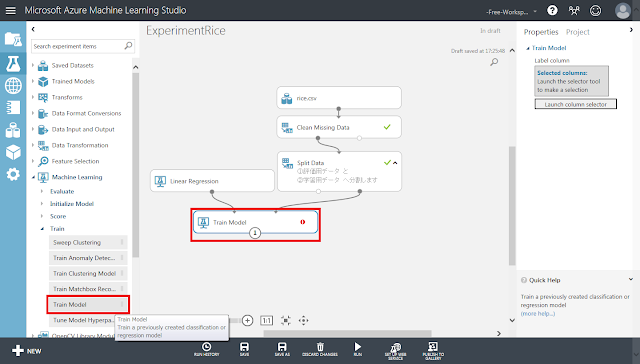
回帰分析によって予測させるデータ列を指定します。
「Train Model」モジュールが選択された状態で右側のパネルにある「Launch column selector」ボタンをクリックします。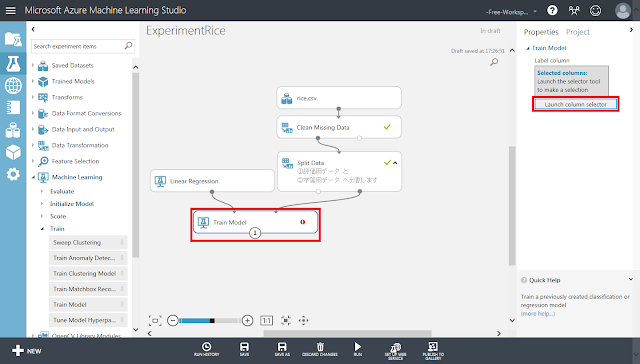
「Yields」(収穫量)列のみを選択して、「☑OK」ボタンをクリックします。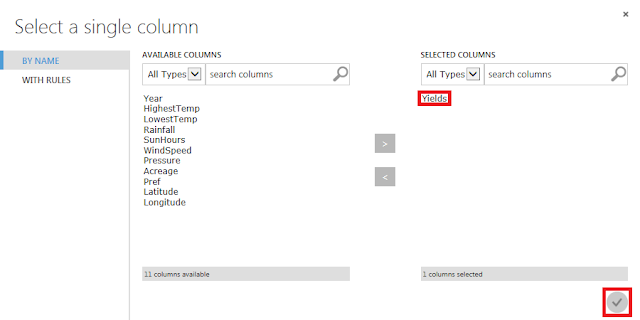
「Train Model」モジュールに表示されていた警告アイコンが消えていることを確認します。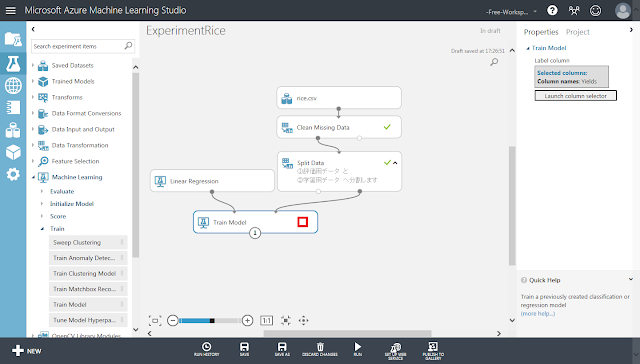
次に、作成した学習モデルによって評価用データセットに対する予測を行うための部分を組み立てていきます。
まず、「Score Model」モジュールを配置した後、「Train Model」モジュールから「Score Model」モジュールの左上の丸印へ、「Split Data」モジュール左下の丸印(評価用データ)から「Score Model」の右上の丸印へ、それぞれ接続します。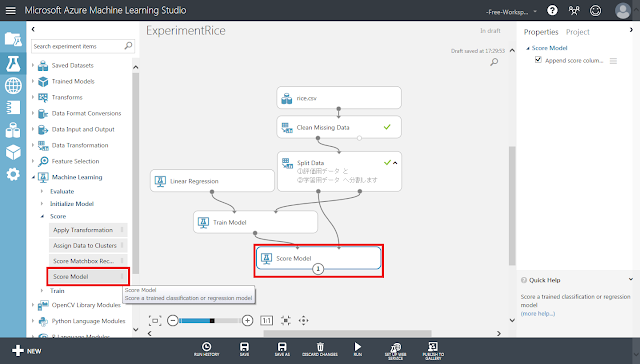
画面下部にある「Run」ボタンをクリックして、一度保存しておきます。
「Run」ボタンをクリックして、処理を実行します。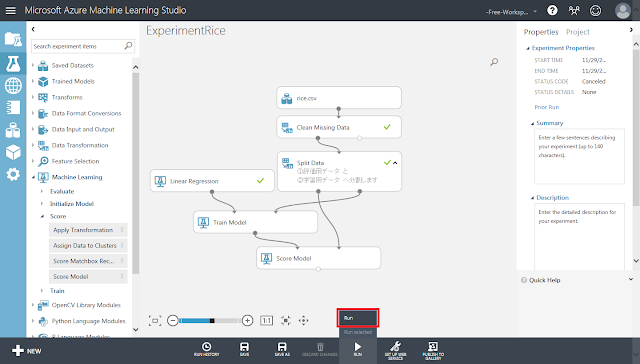
2.4. 結果と評価
2.4.1. 予測結果の確認
回帰分析によって予測された結果を可視化します。
まず、「Score Model」モジュール下部の丸印から「Visualize」メニューを実行します。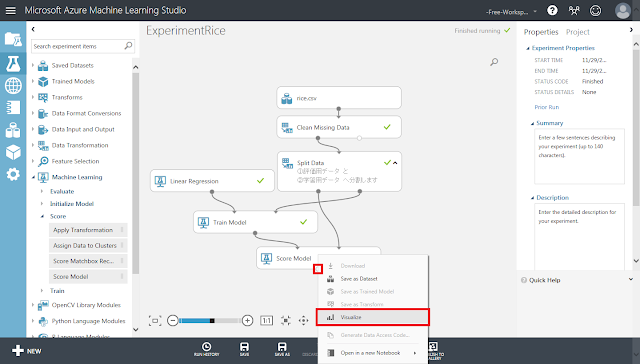
評価用データの特徴量と、予測結果を合わせた表が表示されるので、「Scored Labels」列をクリックして選択します。
「Scored Labels」列を選択すると、右側の領域にヒストグラムが表示されます。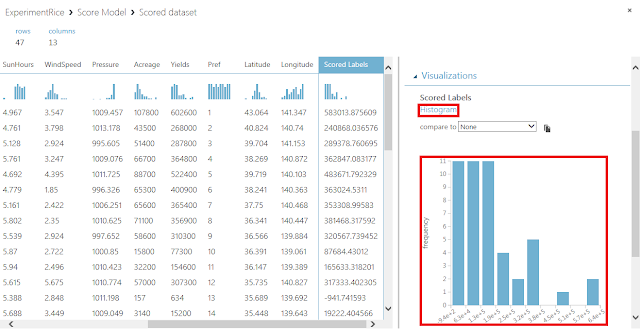
ヒストグラムの上にある「Compare to」リストで、先ほど「Train Model」モジュールでの予測対象の列として指定した「Yields」列を選択します。すると、x軸に予測結果「Scored Labels」列を、y軸に正答「Yields」列をとった散布図が表示されます。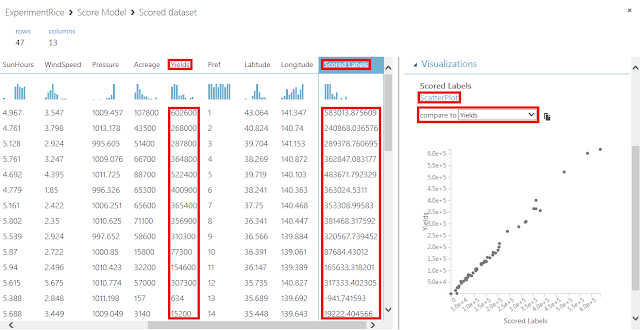
軸の値の範囲が同じであることを確認した上で、予測結果と正答が同じ値となる点を結んだ対角線を引いたときに、対角線に乗るような点が多ければ多いほど高い精度で予測できていることになります。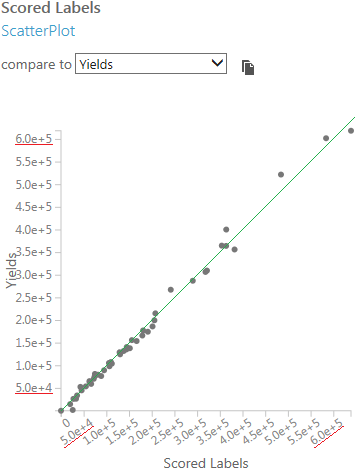
2.4.2. モデルの評価
続いて、指標値を求めることで、学習モデルの予測性能を定量的に判断します。
まず、「Evaluate Model」モジュールを配置し、「Score Model」モジュールから接続します。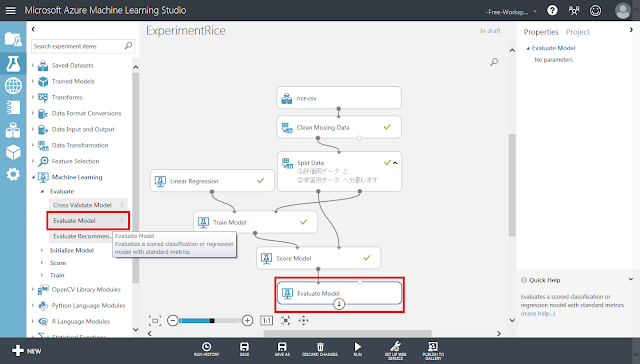
「SAVE」ボタンをクリックして一度保存しておきます。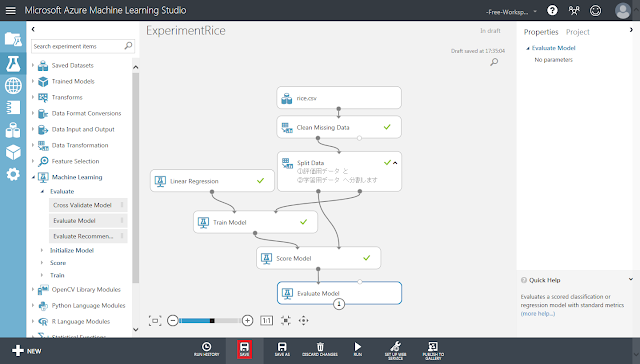
「Run」ボタンをクリックして処理を実行します。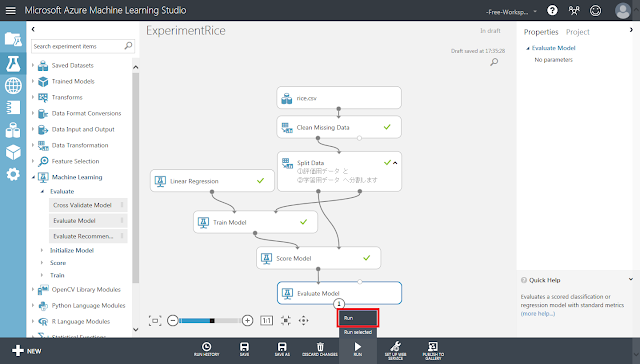
実行が終わった後、「Evaluate Model」モジュール下部の丸印から「Visualize」メニューを実行します。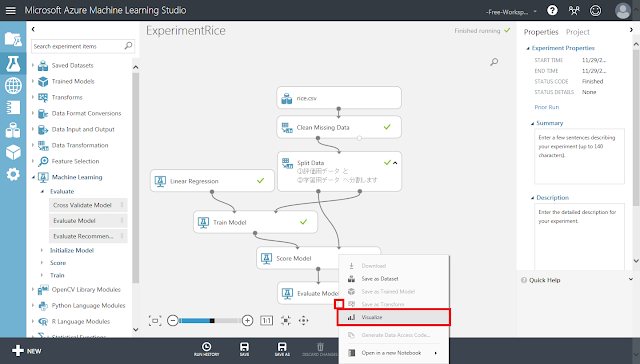
開いたウィンドウに、平均絶対誤差(MAE)や二乗平均平方根誤差(RMSE)といった指標が表示されます。Mean Absolute ErrorからRelative Squared Errorまでは0に近いほど予測精度が高いことを示し、Coefficient of Determination(決定係数)は1に近いほど予測精度が高いことを示します。今回の学習モデルの場合、決定係数が約0.99と、1にかなり近い値になっていることから高い精度で予測を行うことができていると考えられます。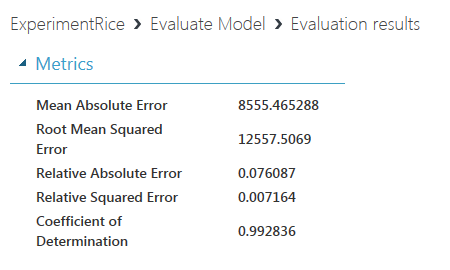
下方向へスクロールすると、誤差のヒストグラムが表示されます。このヒストグラムは、x軸が0の部分が最も高く、x軸正の方向へ進むとともに減少していく場合に精度が高いと判断できます。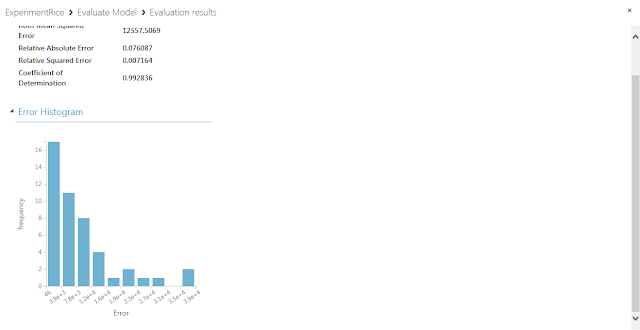
2.4.3. CSV出力の確認
予測結果を画面上に出力するだけでなく、CSVファイルとしてダウンロードするときの手順を紹介します。
まず、「Convert to CSV」モジュールを配置します。配置した後、「Score Model」モジュールから接続します。
「Save」ボタンをクリックして、一度保存しておきます。
「Run」ボタンをクリックして処理を実行します。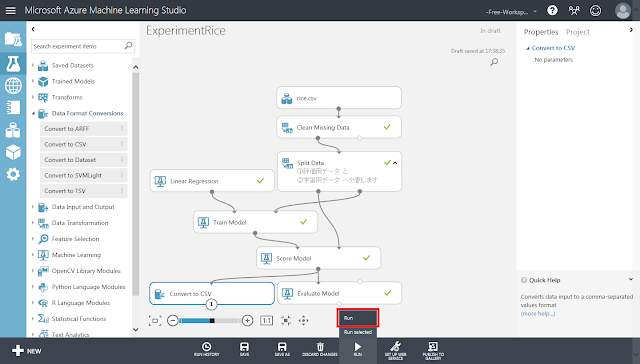
実行が終了したら、「Convert to CSV」モジュール下部の丸印のメニューを開き、「Download」をクリックします。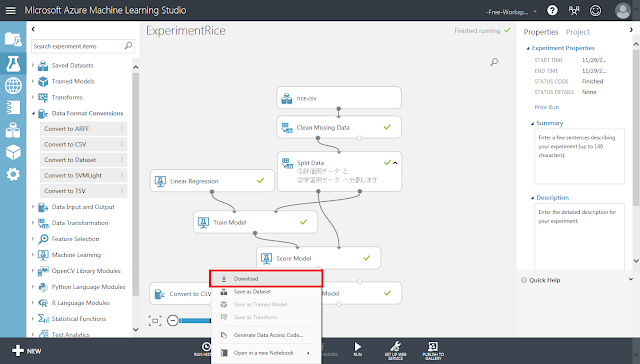
ブラウザのファイルダウンロード通知が表示されるので、「名前をつけて保存」ボタンをクリックします。「保存」ボタンでダウンロードしてしまうと、ファイル名にID状の文字列が追加された状態で保存されてしまうため、「名前をつけて保存」ボタンから任意の分かりやすい名前をつけたうえで保存するほうが良いです。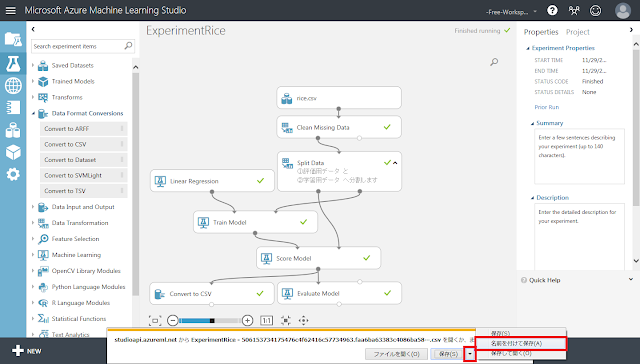
2.5. 特徴量ごとの重要度の確認
続いて、データセットに含まれる各特徴量の「重要度」を求めてみます。重要な特徴量だけを抽出することで、学習モデルの計算量や計算時間を低減したり、過学習を防いだりできる可能性があります。この重要度は、値が大きいほど予測に役立つ特徴量であることを示します。重要度を算出する際に使用する評価指標として、以下のものから選択することができます。選択可能な値が9種類もありますが、対象のモデルがクラス分類か回帰分析かという点さえ間違えなければ問題ありません。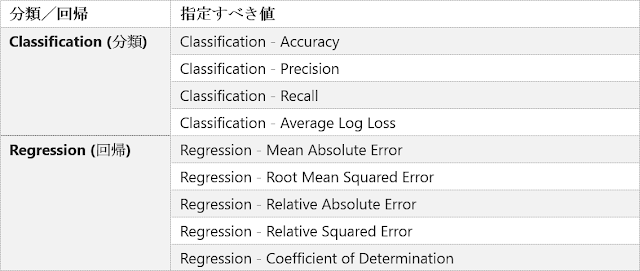
まず、「Train Model」モジュールの後ろに「Permutation Feature Importance」モジュールを配置します。配置したら、「Train Model」モジュールから「Permutation Feature Importance」モジュール左上の丸印へ、「Split Data」モジュール右下の丸印(学習用データ)から「Permutation Feature Importance」モジュール右上の丸印へ、それぞれ接続します。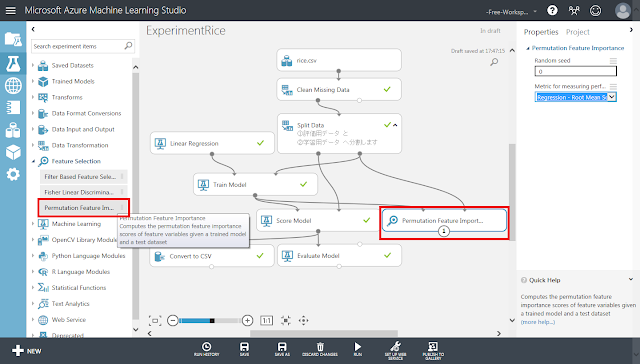
「Permutation Feature Importance」モジュールが選択された状態で、右側のパネルにある「Metric for measuring performance」リストの「Regression – Root Mean Squared Error」を選択します。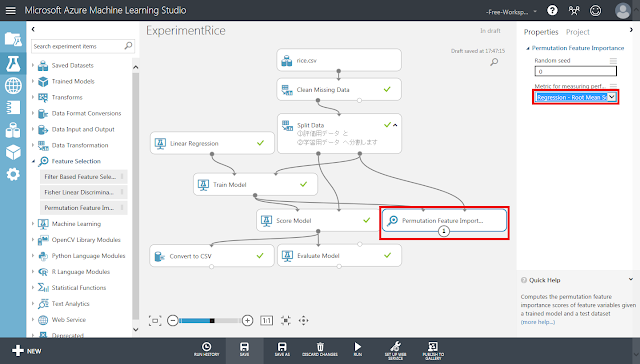
「Run」ボタンをクリックして、処理を実行します。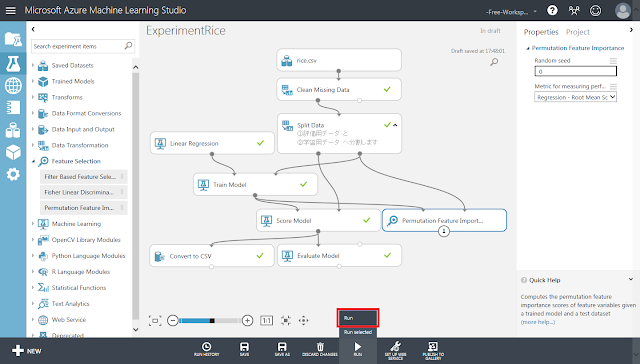
実行が終了した後、「Permutation Feature Importance」モジュール下部の丸印からメニューを開き、「Visualize」をクリックします。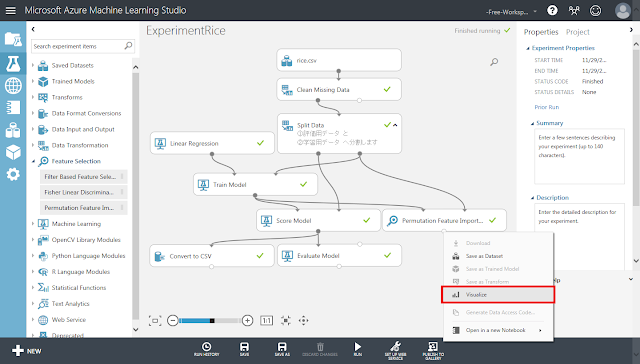
データセット内にある特徴量(Feature)と重要度(Score)が、重要度の高いものからソートされた状態で出力されます。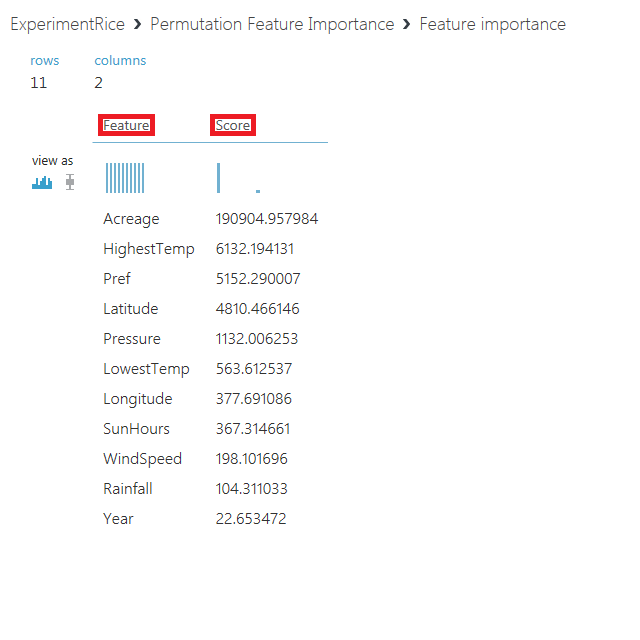
この表をもとに、重要度の高い特徴量のみを使って予測を行う場合は、「rice.csv」モジュールと「Split Data」モジュールの間に「Select Columns in Dataset」モジュールを挟んだ上で、上位の特徴量のみを通す設定とします。
予測結果のデータセットと同様に、重要度の一覧もCSVファイルとしてダウンロードすることができます。
「Permutation Feature Importance」モジュールの直後に「Convert to CSV」モジュールを配置します。「Run」ボタンをクリックして処理を実行した後、「Convert to CSV」モジュール下部の丸印からメニューを開き、「Download」メニューをクリックします。
「名前をつけて保存」ボタンを押して、任意の分かりやすい名前をつけて保存します。
2.6. 予測精度の改善
2.6.1. 他の回帰分析手法への変更
前節では、回帰分析による予測結果の評価を行いました。「Linear Regression」モジュールによる線形回帰でも、ある程度高精度に予測可能なことが確認できました。しかし、より高精度に予測できるアルゴリズムがあればそちらを利用することが望ましいので、ここでは、他の回帰分析用の初期化モジュールに置き換えることによって精度が向上するかを試してみます。
初期化モジュールの個数を2つに増やした場合には、2つの「Score Model」モジュールの実行結果を1つの「Evaluate Model」モジュールに一度に入力することで、結果をまとめて表示させることができます。ただし、回帰予測とクラス分類のように、学習モデルの種類が異なる場合にはエラーとなるので注意が必要です。同じ回帰予測の場合でも、Linear RegressionとFast Forest Quantile Regressionのように、予測結果として出力される列の種類が違う場合にも同様のエラーとなるようです。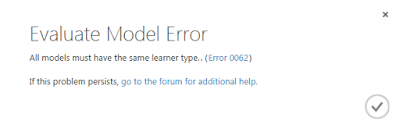
利用可能な回帰予測用の初期化モジュールを全て配置した例と、「Evaluate Model」モジュールに出力される結果を以下に示します。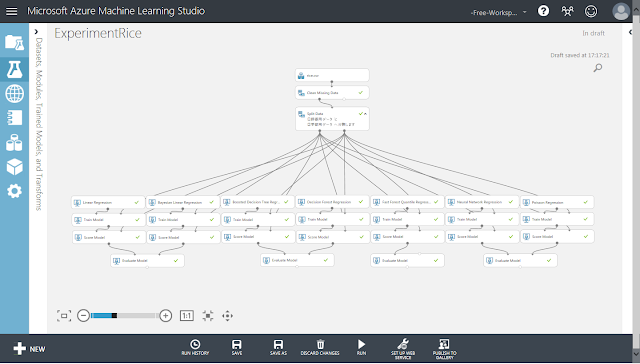
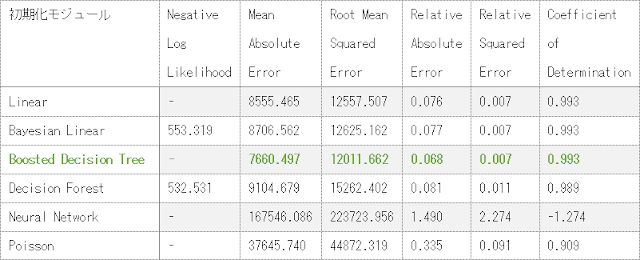
「Fast Forest Quantile」モジュールによる学習モデルの場合にはMean Absolute ErrorやRoot Mean Squared Errorといった指標値が出力されないため、別途指標値を計算する必要があります。求めた指標値を以下の表に示します。
表に示した指標値から、「Boosted Decision Tree」による学習モデルが最も予測性能が高いことがわかります。
2.6.2. パラメーターの調整
さらに、各初期化モジュールに対して、パラメーターの指定方法として、「Single Parameter」ではなく「Parameter Range」を設定することで、以下のような結果になりました。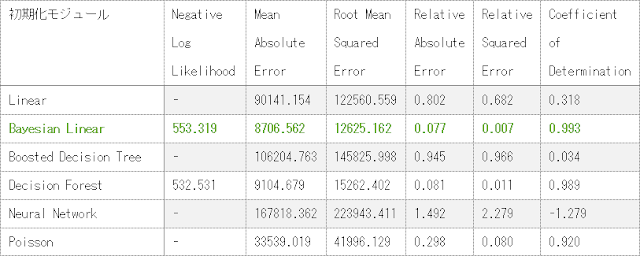

「Fast Forest Quantile」モジュールによる学習モデルに対して、Single Parameterの時と同様に指標値を計算した結果を以下の表に示します。
表に示した指標値から、パラメーターの指定方法として「Parameter Range」を
指定したときの学習モデルの性能は「Boosted Decision Tree」が最も高いことがわかります。
パラメーターの指定方法を変更する前と比較すると、指標値が悪化したものが多いですが、Decision Forestのように結果が変わらなかったものやPoissonのように向上したものもあります。
今後の改善としては、交差検証用の「Cross Validate Model」モジュールを使用したり、データセットに適したパラメーターを探し出すための「Tune Model Hyperparameters」モジュールを使用したりすることで、さらに予測精度を高めることができるかもしれません。ただし、これらの手法を加えることで計算量や計算時間が増加してしまうため、どこかで妥協が必要になります。
オープンデータを使用する場合は特に、データの形式や特徴が千差万別であるために、それぞれのデータを扱う場合に最適なアルゴリズムや最適なパラメーターを探し出すのは困難であると考えられます。Microsoft社によって公開されている機械学習アルゴリズム チート シート(https://docs.microsoft.com/ja-jp/azure/machine-learning/machine-learning-algorithm-cheat-sheet)などを基に、大まかな見当をつけた後、類似した複数のアルゴリズムで学習させ、精度の比較評価を行うことで、使用するデータセットに対して最適なアルゴリズムを決定するという手順が必要です。
ここまで、オープンデータをもとに作成したデータセットを学習させて、精度評価を行う手順についてご紹介しました。次回の記事では、作成したデータセットをAzureのストレージに配置して、ローカルPCを介さずにデータの入出力を行うための手順をご紹介していきたいと考えております。

