記事公開日
LangChainとグラフデータベース連携:AI エージェント簡易実装してみた
こんにちは!DXソリューション営業本部の大和矢です。
最近、AI エージェントとグラフデータベースの連携を検証しています。
昨今注目を集めるAIエージェントとは、自然言語での指示を理解し、外部ツールやデータベースと連携して複雑な処理をこなす画期的な仕組みです。
前回はGitHub Copilot Agent(MCPホスト)とNeo4j AuraDB Freeを使用して検証していましたが、次のステップとしてMCPホスト部分の実装に取り組みます。
今回はその第一歩として、LangChainのzero-shot-react-description を使って構築したシンプルな AI エージェントとグラフデータベース(Neo4j AuraDB Free)の連携検証についてご紹介します。
LangChainには複数のエージェント方式があるので、以下で紹介いたします。
| エージェント方式 | 特徴 |
| zero-shot-react-description | ReAct方式の一種。ツールの説明をもとに、事前の例示なしで柔軟に推論・実行できる。今回使用した方式。 |
| React Docstore | 質問応答に特化したReAct方式で、検索ツールを使ってドキュメントから情報を取得し、正確な回答を生成します。 |
| Self-Ask with Search | 最終的な回答にたどり着くために、質問を小さなサブクエリに分解し、検索ツールを活用して段階的に情報を収集します。 |
| Conversational React Description | 会話履歴を考慮しながらReAct方式で推論・実行を行うため、より自然で継続的な対話が可能です。チャットボットなどに適しています。 |
今回zero-shot-react-description を採用した理由は、グラフデータベースへのアクセスという特定のタスクに対し、事前の詳細なプロンプト設計なしにAIエージェントが適切にツールを利用できるかを確認するために適していると考えたからです。
本ブログではMCPホスト部分の実装には踏み込まず、LangChainエージェント単体での検証を行っています。
前回ブログもぜひご覧ください。

グラフデータベース
今回使用するグラフデータベースは、前回のブログで使用したグラフデータベースを拡張したものです。
Neo4j AuraDB Free上に、以下のように構成しました。
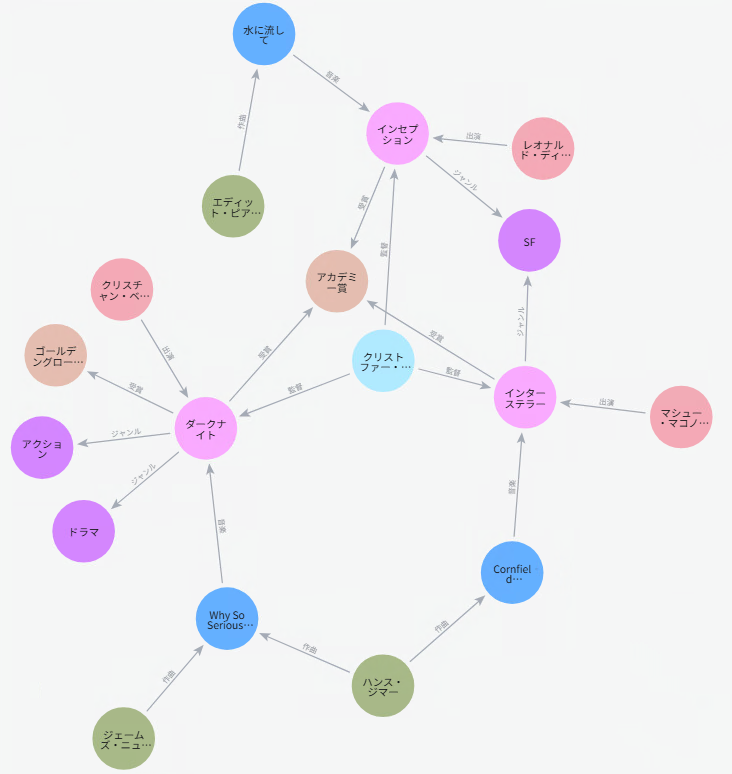 |
こちらのグラフデータベースは、以下のノードで構成されています。
- 映画
- 俳優
- 監督
- 映画ジャンル
- 賞
- 楽曲
- 作曲者
AIエージェント実装
今回の実装は非常にシンプルです。
LangChainとAzure OpenAIを活用し、グラフデータベースに自然言語で質問できるAIエージェントを実装していきます。
ユーザーからの質問(プロンプト)はあらかじめPythonの変数に格納し、その内容に対してエージェントがグラフデータベースへ問い合わせ、回答を返します。
以降で、実際のPythonファイル(agent_builder.py、tools.py)の役割やポイントを紹介します。
agent_builder.py
こちらは、LangChainとAzure OpenAIを使ってエージェントを構築するメインスクリプトです。
from langchain.agents import initialize_agent
from langchain_openai import AzureChatOpenAI
import tools
import os
# Azure OpenAI のLLMを初期化
def get_azure_openai_llm():
endpoint = os.getenv("AZURE_OPENAI_ENDPOINT")
api_key = os.getenv("AZURE_OPENAI_API_KEY")
deployment = os.getenv("AZURE_OPENAI_DEPLOYMENT")
api_version = os.getenv("AZURE_OPENAI_API_VERSION")
return AzureChatOpenAI(
azure_endpoint=endpoint,
api_key=api_key,
deployment_name=deployment,
api_version=api_version,
model=deployment,
temperature=0
)
# エージェント初期化
llm = get_azure_openai_llm()
agent = initialize_agent(tools.TOOLS, llm, agent="zero-shot-react-description", verbose=True)
def ask_agent(question: str):
"""ユーザーの質問に対し、エージェントが試行錯誤して回答を返す"""
return agent.run(question)
# テスト用
if __name__ == "__main__":
q = "エディット・ピアフとレオナルド・ディカプリオの関係を教えて。"
print(ask_agent(q))
initialize_agent(tools, llm, agent, verbose)
LangChainのエージェントを初期化する関数です。
主な引数は以下の通りです:
- tools:エージェントが利用できるツールのリスト(ここではtools.pyで定義)
- llm:大規模言語モデル(ここではAzureChatOpenAIインスタンス)
- agent:エージェントの種類(ここではzero-shot-react-description)
- verbose:詳細なログ出力を有効にするかどうか(ここではTrue)
ask_agent(question: str)
ユーザーからの質問(文字列)を受け取り、エージェントに渡して回答を得る関数です。
tools.py
こちらは、LangChainエージェントが利用する「ツール」を定義しています。
from langchain.tools.base import BaseTool
from neo4j import GraphDatabase
import config
class CypherQueryTool(BaseTool):
name: str = "Cypher Query Tool"
description: str = "自然言語の質問をCypherクエリに変換し、Neo4jで実行して結果を返す。"
def _run(self, input: str):
# inputをCypherクエリとして扱う
try:
driver = GraphDatabase.driver(
config.NEO4J_URI,
auth=(config.NEO4J_USERNAME, config.NEO4J_PASSWORD)
)
with driver.session(database=config.NEO4J_DATABASE) as session:
result = session.run(input)
records = [r.data() for r in result]
driver.close()
return records
except Exception as e:
return f"エラー: {e}"
class GraphSchemaTool(BaseTool):
name: str = "Graph Schema Tool"
description: str = "Neo4jグラフDBのノード・リレーション・属性のスキーマ情報を取得する。"
def _run(self, input: str = ""):
try:
driver = GraphDatabase.driver(
config.NEO4J_URI,
auth=(config.NEO4J_USERNAME, config.NEO4J_PASSWORD)
)
with driver.session(database=config.NEO4J_DATABASE) as session:
# 簡易的なスキーマ取得例
node_labels = session.run("CALL db.labels()")
rel_types = session.run("CALL db.relationshipTypes()")
labels = [r["label"] for r in node_labels]
rels = [r["relationshipType"] for r in rel_types]
driver.close()
return {"labels": labels, "relationships": rels}
except Exception as e:
return f"エラー: {e}"
# LangChainエージェントで使うツールリスト
TOOLS = [
CypherQueryTool(),
GraphSchemaTool(),
]
CypherQueryTool(BaseTool)
CypherクエリをNeo4jに投げて結果を返すツールです。
- nameやdescriptionでツールの説明を設定
- _run(input: str)で実際のクエリ実行ロジックを記述(inputはCypherクエリ文字列)
GraphSchemaTool(BaseTool)
グラフDBのノードやリレーションのスキーマ情報を取得するツールです。
- _run(input: str = "")でスキーマ取得処理を実装(inputは不要なので空文字列)
TOOLS
上記ツールをリスト化し、エージェントに渡せるようにしています。
動作確認
このスクリプトでは、プロンプトを変数qにセットし、ask_agent(q)を呼び出すことで、AIエージェントがグラフデータベースに問い合わせて回答を返してくれます。
今回、プロンプトには「エディット・ピアフとレオナルド・ディカプリオの関係を教えて。」とセットしています。
それでは、実装した「agent_builder.py」を実行してみましょう。
python agent_builder.py
実行してみると、以下のような動作ログが表示されます。
「エディット・ピアフとレオナルド・ディカプリオ」―― 一見すると接点のない二人ですが、AIエージェントがグラフデータベース(DB)を使って、その間に隠された関係性を見つけ出しました。
エージェントの推論プロセスは、"Entering new AgentExecutor chain..." から始まり、ReAct方式に基づき「Thought(思考)」と「Action(ツール実行)」を繰り返します。
この反復的なアプローチにより、エージェントは問題を分解し、必要な情報を取得しながら解決策を導き出します。
特に、Actionの実行中にエラーが発生した場合でも、エージェントは再度「Thought」を行い、状況に応じて最適な「Action」を再試行するリカバリー能力を備えています。
最終的に "Finished chain." と表示され、一連の思考とアクションを経て導き出された結果がユーザーへの返答として出力されます。
この仕組みにより、AIエージェントは複雑な質問にも自律的に試行錯誤しながら最適な答えを導き出します。
エージェントの動作の解説
Thought 1:まずはデータベースの構造把握から
エージェントは、いきなり関係性を探すのではなく、まずグラフDBにどんな情報(ノードの種類や関係性)が入っているかを確認します。
これにより、どのようなデータを使って探索できるか把握しようとしています。
Action: Graph Schema Toolでスキーマ情報を取得し、Node_Actor(俳優)、Node_Movie(映画)、Edge_Act(出演)、「作曲」といった関係性が存在することを確認しました。
Thought 2:最初のクエリは自然言語で失敗!
次に、エージェントは「エディット・ピアフとレオナルド・ディカプリオの間のリレーションを知りたい」と直接指示を出します。
しかし、ここでエラーが発生。これは、グラフDBのクエリツールがCypherという専用の言語を必要とするため、自然言語では理解できなかったからです。
エージェントはこのエラーからすぐに学び、次の一手でクエリ言語を修正しようとします。
Thought 3:Cypherで再挑戦、しかし構文エラーに直面
エラーを受けて、エージェントはCypher構文で直接的・間接的な関係を調べるクエリを作成します。
直接的な関係と、間に別のノードを挟む間接的な関係(最大3ホップ先)をUNIONで結合しようと試みました。
しかし、ここで「UNIONで返すカラム名が一致していない」という構文エラーが発生。
エージェントは再びこのエラーを認識し、クエリの改善が必要だと判断します。
Thought 4:最終アプローチ!「最短パス」で関係性を特定!
カラム名のエラーから学び、エージェントはアプローチを変更。
「shortestPath((a)-[*..4]-(b))」というクエリを使って、エディット・ピアフとレオナルド・ディカプリオの間の最短経路を最大4ホップ先まで探すことにしました。
この手法は、複雑なつながりの中から最もシンプルな関係性を見つけるのに非常に有効です。
そして、この最終クエリが見事に成功!
[{'p': [{'name': 'エディット・ピアフ', 'id': 1}, '作曲', {'id': 1, 'title': '水に流して'}, '音楽', {'id': 1, 'title': 'インセプション', 'releaseYear': 2010}, '出演', {'name': 'レオナルド・ディカプリオ', 'id': 1}]}]
結論
エディット・ピアフとレオナルド・ディカプリオの関係を教えて。
「映画の出演俳優」と「映画で流れる楽曲の制作者」という、一見すると離れたノードの関係性を質問したところ、以下の回答が返ってきました。
エディット・ピアフとレオナルド・ディカプリオは、映画『インセプション』を通じて関係があります。エディット・ピアフの楽曲「水に流して(Non, je ne regrette rien)」が『インセプション』で使用されており、レオナルド・ディカプリオはその映画に出演しています。
このように、エージェントは複雑な推論プロセスを経て、見事に正しい回答を導き出すことに成功しました。
しかしながら、筆者の検証では、このスクリプトの実行が常に成功するわけではなく、体感として成功率は約20%程度でした。
そのため、より高精度な回答を目指し、プロンプトの質向上やエージェントの継続的な調整を進めてまいります。
まとめ
今回は、LangChain を使ったAI エージェントとグラフデータベースの基本的な連携検証についてご紹介しました。
シンプルな実装ながら「つながる」こと、そしてエージェントが「動作する」ことを確認できたのは大きな収穫でした。
MCPやグラフデータベースの検証は引き続き進めていきますので、今後も検証ブログをお届けできるかもしれません。
どうぞご期待ください。
QUICK E-Solutionsでは、「AIチャットボット構築サービス」をはじめとして、各AIサービスを利用したシステム導入のお手伝いをしております。
それ以外でも QESでは様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
※このブログで参照されている会社名、製品名は各社の登録商標または商標です。

