記事公開日
Azure AI Search のスコアについて考えてみる ~テキスト検索編~

今回は、Azure AI Searchが出すスコアにフォーカスを当て、実際にどのようなスコアが出ているのか、どのようなチューニングができるのかについて、記載します。
フルテキスト検索とは
テキスト検索編ということなので、フルテキスト検索(全文検索)について見ていきます。フルテキスト検索とは、文書全体をキーワードや用語等で検索する仕組みです。➡ Azure AI Searchでのフルテキスト検索
公式ページによると、Azure AI Search の フルテキスト検索は、以下のステップで処理されていることが記載されています。
| ステップ | 内容 |
|---|---|
| クエリ解析 | 検索語からサブクエリに分解する。 サブクエリとは、単語検索、フレーズ検索、プレフィックス検索がある。 |
| 字句解析 | 単語検索とフレーズ検索が、アナライザーによって加工される。 |
| 文書検索 | インデックスの文書の中から、一致する語句を含む文書を検索する。 |
| スコア付け | スコア付の核となるのは、TF/IDF。出現頻度の低い語句と高い語句を含んだ検索の場合、出現頻度の低い語句を含んだ結果に高いランクを与える。 |
アナライザーの違いのよる検索への影響
アナライザーとは、「インデックス作成」と「クエリ実行中に文字列を処理」するコンポーネントで、テキスト系のフィールドに設定します。
検索文を自由入力とし、入力された文章をそのまま検索に使用する場合、その文章がそのまま使用されるわけではなく、字句解析でトークンに分割されて使用されます。このトークン分割は、アナライザーによって処理されます。アナライザーの種類によって、トークン分割が変わりますので、結果的に検索結果に影響が出てきます。
日本語文書の検索で、最初にできる調整はアナライザーの選択です。
自身でインデックスを作成した場合は、最初からそのフィールドに適したアナライザーを設定しているかと思います。Azure AI Searchのウィザードで作成した場合は、デフォルトのアナライザー(標準-Lucene)が設定されています。そのまま利用しても、それっぽく検索できますので気づかずにそのまま使用しているケースもあるかもしれません。
日本語テキストを含むフィールドには、日本語系アナライザーを設定した方が良いと考えられます。
日本語に対応したアナライザーは、「日本語-Lucene(ja.lucene)」と「日本語-Microsoft(ja.microsoft)」があります。
Microsoftアナライザーは、Office や Bing で使用される Microsoft独自の自然言語処理技術によって提供される言語アナライザーであり、レンマ化、言語複混合化、エンティティの認識 (URL、メール、日付、数字)などの高度な機能が組み込まれているとのことです。細かいことは良く分かりませんが、とりあえず試してみます。
アナライザーのトークン分割については、Analyze API(➡仕様)で確認することができます。
早速、Analyze APIを使用して、アナライザーでどのようにトークン分割されるか見ていきます。
※ トークン分割の話は、過去の記事でも少し触れています。(➡「Azure AI Search の統合ベクトル化を試してみた」)
以下の文章が検索文として入力された場合の動きを確認してみます。
彼女の優れているところは?
| アナライザー | トークン分割結果 |
|---|---|
| 標準-Lucene (standard.lucene) |
彼、女、の、優、れ、て、い、る、と、こ、ろ、は |
| 日本語-Lucene (ja.lucene) |
彼女、優れる |
| 日本語-Microsoft (ja.microsoft) |
彼女、優れ、て、いる、ところ |
検索用インデックスの準備
アナライザーによって、トークン分割が異なることが分かりました。実際に検索してみると、どのような差が出てくるのかを見ていきます。検索用として、以下の文章(50個)を用意してインデックスに取り込んでいます。
| ・明日の天気は晴れるでしょう。 ・明日は晴天が予想されます。 ・このレストランの料理はとても美味しいです。 ・こちらのお店の食事は、大変風味豊かですね。 ・会議の開始時間は午前10時です。 ・ミーティングは10時にスタートします。 ・新しいプロジェクトがまもなく始動します。 ・近日中に新規案件が立ち上がる予定です。 ・彼の提案は非常に興味深いものでした。 ・彼のアイデアには大変惹かれるものがありました。 ・システムのアップデートが必要です。 ・そのシステムは更新しなければなりません。 ・電車の遅延により到着が遅れます。 ・列車が遅れているため、着くのが少し後になります。 ・この本は多くの読者に感動を与えました。 ・この書籍は多くの人々の心を打ちました。 ・至急、資料をご確認ください。 ・速やかに書類に目を通していただけますか。 ・彼女は優れたコミュニケーション能力を持っています。 ・彼女は人との意思疎通が非常に上手です。 ・来週、新しいソフトウェアがリリースされます。 ・新しいアプリが来週公開される見込みです。 ・この製品の品質は保証されています。 ・この商品のクオリティについては請け合います。 ・昨夜、珍しい夢を見ました。 ・昨晩は不思議な夢を体験しました。 |
・イベントへの参加申し込みは本日までです。 ・行事の登録締め切りは今日です。 ・彼は正直で信頼できる人物です。 ・彼は嘘をつかない、頼りになる人柄です。 ・この問題の解決策を見つけ出す必要があります。 ・この課題に対する答えを導き出さねばなりません。 ・旅行の準備はもう済みましたか。 ・旅支度はもう完了しましたでしょうか。 ・彼の功績は称賛に値します。 ・彼が成し遂げたことは褒められるべきです。 ・景気が少しずつ回復している兆しが見られます。 ・経済状況が徐々に上向いている気配があります。 ・その映画の結末は衝撃的でした。 ・あのフィルムのラストシーンには驚かされました。 ・子供たちは公園で元気に遊んでいます。 ・子どもたちが広場で活発に動き回っています。 ・詳細については、添付ファイルをご覧ください。 ・詳しくは、お送りしたデータをご参照ください。 ・チームの協力なしには成功できませんでした。 ・部門の連携がなければ、この達成は不可能だったでしょう。 ・健康のため、毎日運動を心がけています。 ・健やかな体を維持するため、日々のエクササイズを意識しています。 ・今年の夏は特に暑い日が続いています。 ・例年に比べて、今夏は猛暑が連続しています。 |
各アナライザーの動作を確認するため、以下のようなインデックス構成としました。
それぞれのアナライザー用フィールドを設けて、同じ文章を格納しています。
検索結果を確認
「彼女の優れているところは?」を使用して、各フィールドを検索してみます。認識したトークンを識別できるようにハイライトも出力します。{
"count": true,
"search": "彼女の優れているところは?",
"searchFields": "text_st_lucene",
"select": "text_st_lucene",
"highlight": "text_st_lucene"
}
① 標準 - Lucene
なんと、全件(50件)ヒットしてしまいました。トークンが1文字ずつに分割されてしまったため、いずれかの文字を含むものが候補として抽出されたのでしょう。| 順位 | 文章 | スコア |
|---|---|---|
| 1 | 彼女は優れたコミュニケーション能力を持っています。 | 7.754426 |
| 2 | この製品の品質は保証されています。 | 6.3134427 |
| 3 | このレストランの料理はとても美味しいです。 | 6.12836 |
| 4 | 彼が成し遂げたことは褒められるべきです。 | 5.123605 |
| 5 | 彼女は人との意思疎通が非常に上手です。 | 4.946603 |
| (中略) | ||
| 49 | チームの協力なしには成功できませんでした。 | 0.27158472 |
| 50 | 新しいプロジェクトがまもなく始動します。 | 0.18232156 |
上位2件がどのように判定されたか見ていきます。太字部分が、ヒットしたトークンとなります(ハイライト出力でマークされた部分)。
「彼女は優れたコミュニケーション能力を持っています。」➡「彼女」、「優れ」とそれっぽく判定できてそうですが、「彼」「女」「優」「れ」は、それぞれ別のワードとしてハイライトされています。このため、「彼女」というまとまりでは判断されていません。そのため、4位の文章は、「彼」部分もハイライトされました。
「この製品の品質は保証されています。 」
② 日本語 - Lucene
トークン分割が少ないため、2件しかヒットしませんでした。| 順位 | 文章 | スコア |
|---|---|---|
| 1 | 彼女は優れたコミュニケーション能力を持っています。 | 3.0726147 |
| 2 | 彼女は人との意思疎通が非常に上手です。 | 1.3184062 |
「彼女は優れたコミュニケーション能力を持っています。」➡ こちらはトークン分割で主要ワード以外は抽出されていないため、結果はシンプルです。「彼女」という文字が含まれている文章は、2つしか用意しませんので、納得のいく結果となりました。
「彼女は人との意思疎通が非常に上手です。」
③ 日本語 - Microsoft
こちらは、14件ヒットしました。| 順位 | 文章 | スコア |
|---|---|---|
| 1 | 彼女は優れたコミュニケーション能力を持っています。 | 4.0586543 |
| 2 | 景気が少しずつ回復している兆しが見られます。 | 2.221199 |
| 3 | 列車が遅れているため、着くのが少し後になります。 | 1.934549 |
| 4 | 経済状況が徐々に上向いている気配があります。 | 1.934549 |
| 5 | 彼女は人との意思疎通が非常に上手です。 | 1.6770256 |
| (中略) | ||
| 13 | 速やかに書類に目を通していただけますか。 | 0.26686338 |
| 14 | 今年の夏は特に暑い日が続いています。 | 0.26686338 |
「彼女は優れたコミュニケーション能力を持っています。」➡ 2位となった文書は、「て」「いる」を含んでいるので、トークン分割単語が含まれていることが分かりますが、なぜ上位に来ているのか分かりづらい結果となりました。
「景気が少しずつ回復している兆しが見られます。」
テキスト検索だけで考えると、検索文が「xxxを探して」などの依頼文のような形の場合、「探して」部分も検索ワードの一部として扱われることになるため、雑音となる可能性があることを認識しておく必要があります。
アナライザーの選択だけでも、検索順位に影響が出ることが分かりました。少なくとも標準Luceneでの検索結果は、単語としての検索ができず、内容が全く関係の無いものが過剰にリストアップされる可能性があります。もしウィザードで作成したまま標準-Luceneを使用している場合は、日本語系アナライザーへの変更をおススメします。
日本語-Lucene が良いか、日本語-Microsoft が良いかはケースにより変わってきそうです。どちらが相性が良いかは、検索対象のドキュメントの内容により変わってくると思いますので、試してみると良いかと思います。
※インデックス作成後のアナライザーの変更には、インデックスの再作成が必要です。
テキスト検索におけるスコア
検索結果は、算出されたスコアにより順位付けされます。フルテキスト検索では、BM25関連性スコアリングが使用され、範囲は無制限です。
BM25は IF-IDFタイプであり、出現頻度(TF)と逆文書頻度(IDF)を使用し、関連スコアが計算されます。
詳しくは公式サイトをご参照ください。キーワード検索での関連性 (BM25 スコアリング)
featuresMode パラメーター
フルテキスト検索では、複数フィールドを対象にできます。フィールド毎の関連性スコア情報を参照したい場合は、featuresModeパラメータを有効にすることで確認できます。"featuresMode": "enabled"
{
"@odata.context": "https://****.search.windows.net/indexes('index-test')/$metadata#docs(*)",
"@odata.count": 14,
"value": [
{
"@search.score": 7.131269,
"@search.highlights": {
"text_ja_lucene": [
"<em>彼女</em>は<em>優れ</em>たコミュニケーション能力を持っています。"
],
"text_ja_microsoft": [
"<em>彼女</em>は<em>優れ</em>たコミュニケーション能力を持っ<em>て</em>います。"
]
},
"@search.features": {
"text_ja_lucene": {
"uniqueTokenMatches": 2,
"similarityScore": 3.0726146,
"termFrequency": 2
},
"text_ja_microsoft": {
"uniqueTokenMatches": 3,
"similarityScore": 4.058654,
"termFrequency": 3
}
},
"text_ja_lucene": "彼女は優れたコミュニケーション能力を持っています。"
},
シノニムの設定
フルテキスト検索では、文書中に分割されたトークンが含まれることが重要になってきます。意味合いが同じでも検索文にその単語が含まれない限り、ヒットすることはありません。今回のテストデータで見ていきます。「こども」に関連する文章としては、以下の二つがあります。
子供たちは公園で元気に遊んでいます。これらは、「こども」というワードで検索してもヒットせず、「子供」というワードであれば、一つめの文章だけがヒットする形になります。シノニム設定することで、同じワードであることを認識させることができます。
子どもたちが広場で活発に動き回っています。
シノニムマップの作成
シノニムを設定するには、最初にシノニムマップを作成する必要があります。作成は、シノニムマップの作成(API)を使用します。(※各言語の SDKから呼び出せます)
今回は、[synonymmap-test] という名前のマップに対して、「子供」「子ども」「こども」「小人」「児童」「キッズ」を同義語として定義しています。同義語のルールは改行コード区切りで、複数定義できます。
{
"name": "synonymmap-test",
"format": "solr",
"synonyms": "子供, 子ども, こども, 小人, 児童, キッズ",
"encryptionKey": null
}
シノニムマップの割り当て
シノニムマップを作成するだけでは使用できません。作成したマップを検索するフィールドに割り当てる必要があります。今回は、日本語Lucene列に割り当ててみます。 {
"name": "text_ja_lucene",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": true,
"facetable": false,
"key": false,
"analyzer": "ja.lucene",
"synonymMaps": [
"synonymmap-test"
]
},
検索動作の確認
検索結果を比較してみます。① シノニムマップ割り当て前 /「子供」を検索
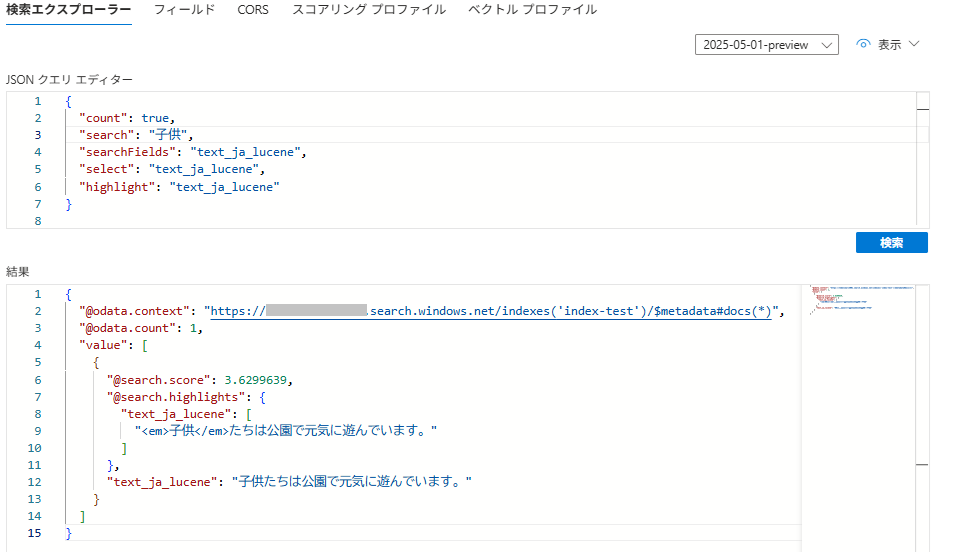
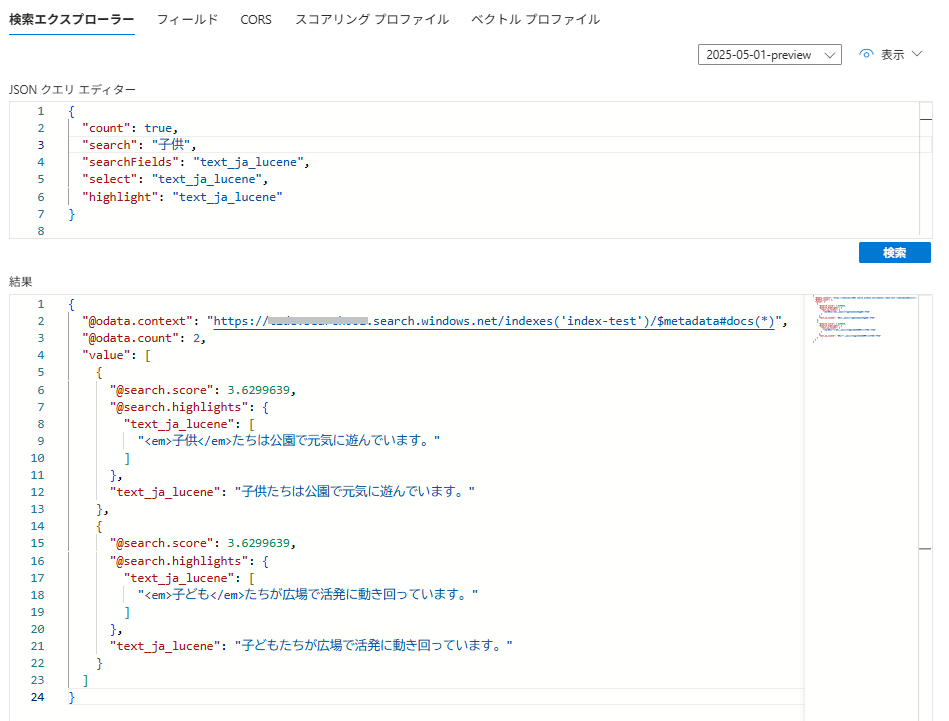
② シノニムマップ割り当て後 / 「子供」を検索
③ シノニムマップ割り当て後 /「こども」を検索
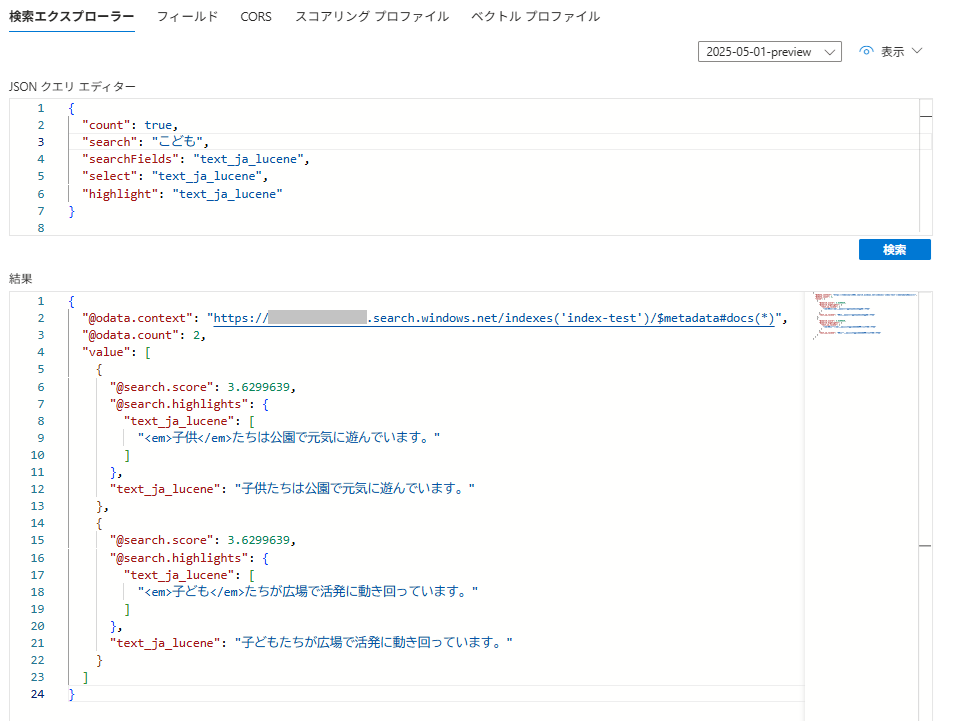
シノニムマップを設定することで、同義語検索できていることが分かります。同等と扱われているため、スコアも同一になっています。
略称だったり、業界特有の言い回しなどを同義語として扱うためにもシノニム設定が有効であると考えられます。
シノニムマップやルールの設定数には上限があります。便利であるもののシノニムですべてをカバーすることはできません。どのような検索ワードが使われるかを解析した上で、運用の中でシノニム設定を調整していくと良いかと思います。
セマンティックランカーを併用する
テキスト検索の結果に、セマンティックランカーを被せることもできます。セマンティックランカー(セマンティックランク付け)とは、テキスト検索やベクトル検索、またはその両方(ハイブリッド)の結果順位を調整する機能です。「Microsoft の言語理解モデルを使用して検索の関連性をある程度高める機能」とのことで、Microsoftの経験によって内容を見て順位を調整してあげるよ、という機能です。単純にキーワード検索だけの順位よりも内容を意識した順位となるはずです。順位を調整する機能であるため、候補にリストアップしてあげないと、順位調整の対象になりません。一次選抜(今回の場合はテキスト検索)の結果が重要となります。
➡ Azure AI Search でのセマンティック ランク付け
日本語Microsoft のアナライザーでの検索に対して、セマンティックランカーを使用した結果は以下の通りです。
| 順位 | 元順位 | 文章 | リランカースコア |
|---|---|---|---|
| 1→ | 1 | 彼女は優れたコミュニケーション能力を持っています。 | 2.055208683013916 |
| 2↑ | 5 | 彼女は人との意思疎通が非常に上手です。 | 1.7561252117156982 |
| 3↑ | 9 | 健やかな体を維持するため、日々のエクササイズを意識しています。 | 1.521466612815857 |
| 4↑ | 8 | 子どもたちが広場で活発に動き回っています。 | 1.4697141647338867 |
| 5↓ | 2 | 景気が少しずつ回復している兆しが見られます。 | 1.325090765953064, |
| (中略) | |||
| 13↓ | 3 | 列車が遅れているため、着くのが少し後になります。 | 0.8011853694915771 |
| 14↓ | 6 | 詳細については、添付ファイルをご覧ください。 | 0.6983892917633057 |
また、リランカースコアはアナライザーの違いのよる元のスコアや順位に関係無く、同じデータであれば一律となるようです。
リランカースコアは、以下のように設定されているため、極端に低いスコアのものは切り捨てるなどの対応が必要でしょう。
| スコア | スコアの意味 |
|---|---|
| 4.0 | ドキュメントは関連性が高く、質問に完全に回答しますが、文節には、質問と関係のない追加のテキストが含まれている可能性があります。 |
| 3.0 | ドキュメントは、関連性はありますが、完全なものにする詳細は含まれていません。 |
| 2.0 | ドキュメントは、ある程度関連性があり、質問に部分的に回答するか、質問の一部の側面にのみ対処します。 |
| 1.0 | ドキュメントは質問に関連しており、質問のほんの一部に回答します。 |
| 0.0 | ドキュメントは関連性がありません。 |
スコアの調整
内部のスコア算出アルゴリズムを変更することはできませんが、スコアの重み付けを変更する機能があります。スコアリングプロファイルの設定
インデックスにスコアリングプロファイルを設定しておき、検索時に使用するか選択できます。(1) ウェイトの設定
フィールド毎の重みを変更します。ファイル検索用途であれば、ファイル名と本文があった場合に、ファイル名に特定のキーワードがあった場合にスコアを上げたい場合などに使用できます。(2) 関数の設定
用意されている関数は、以下の 4種類あり、インデックスに設定できる型のフィールドを持つ場合に設定できます。| 関数 | 設定できる型 | 内容 |
|---|---|---|
| Distance | Edm.GeographyPoint | 地理的位置によりブーストします。 例)近いもののスコアを高く |
| Freshness | Edm.DateTimeOffset | 日時データによりブーストします。 例) 新しい日時のスコアを高く |
| Magnitude | Edm.Int Edm.Double |
数値範囲によりブーストします。 例) 10~20の範囲にあるもののスコアを高く |
| タグ | Edm.String Collection(Edm.String) |
設定されているタグによりブーストします。 例) タグに「日本」を含むもののスコアを高く |
用語ブースト
検索時に特定の用語に対してスコアの重みを設定します。検索クエリを加工することで使用できます。 {
"count": true,
"queryType": "full",
"search": "彼女^2の優れているところは?",
"searchFields": "text_ja_microsoft",
"highlight": "text_ja_microsoft",
"select": "text_ja_microsoft",
"featuresMode": "enabled"
}
用語ブーストは、Full Luceneクエリ構文の中で設定できます。上記例では、[彼女]に対して重みを高くしています。[^2]の部分が該当し、数字部分がブースト係数となります。
日本語Microsoftアナライザー列の検索に対して試したところ、「彼女」を含む文章のスコアが調整され以下のようになりました。それ以外のスコアに変動はありません。
| 順位 | 文章 | スコア |
|---|---|---|
| 1 | 彼女は優れたコミュニケーション能力を持っています。 |
5.6861253
|
| 2 | 彼女は人との意思疎通が非常に上手です。 |
3.354051
|
| 3 | 景気が少しずつ回復している兆しが見られます。 | 2.221199 |
| 4 | 列車が遅れているため、着くのが少し後になります。 | 1.934549 |
| 5 | 経済状況が徐々に上向いている気配があります。 | 1.934549 |
| (中略) | ||
| 13 | 速やかに書類に目を通していただけますか。 | 0.26686338 |
| 14 | 今年の夏は特に暑い日が続いています。 | 0.26686338 |
おわりに
今回は、Azure AI Search のテキスト検索のランク付けの動きを見てみました。フルテキスト検索だけでも奥が深いです。もし、ハイブリッド&セマンティックランカーを使用しても精度が出ない場合などがあれば、テキスト検索の構成を見直してみることも必要かもしれません。QUICK E-Solutions では、Azure AI Searchを含む各 Azure AIサービスを利用したシステム導入のお手伝いをしております。それ以外でも様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
※このブログで参照されている、Microsoft、Azure AI Search、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
※その他の会社名、製品名は各社の登録商標または商標です。

