記事公開日
最終更新日
第6回 他の手法による学習
前の章では、前回学習させたクラス分類の結果を評価し終えました。今回は、クラス分類以外の手法で学習させた時に、その評価を行う手順を紹介します。
3.他の手法による学習
機械学習には、クラス分類以外にも、回帰分析、クラスタリング、アノマリ検知といった予測・分類手法があります。これらを利用した場合の手順について、説明します。
3.1.回帰分析
回帰分析を行う手順について説明します。
今回も、Azure ML上に予め用意されている、アヤメの統計データを用います。
この統計データに含まれている特徴のうち、アヤメの大きい花びらの長さを、品種およびその他の部分のサイズをもとに予測させる学習モデルを作ります。
3.1.1.学習ロジックの作成
以下のようにモジュールを配置します。
まず、初期化モジュールを回帰分析のものに変更します。今回は、回帰分析の最も基本的なアルゴリズムである線形回帰を使用するため、Machine Learning→Initialize Model→Regression→Linear Regressionを、画面中央の灰色の領域に配置します。
次に、学習モデルおよび計算モジュールは、クラス分類と同様にそれぞれTrain Model、Score Modelを使用します。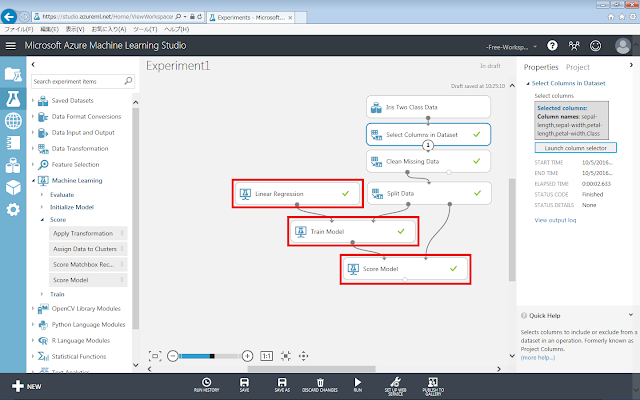
次に、学習に使用する特徴を指定します。
「Select Columns in Dataset」モジュールが選択された状態で、右側にあるLaunch column selectorをクリックします。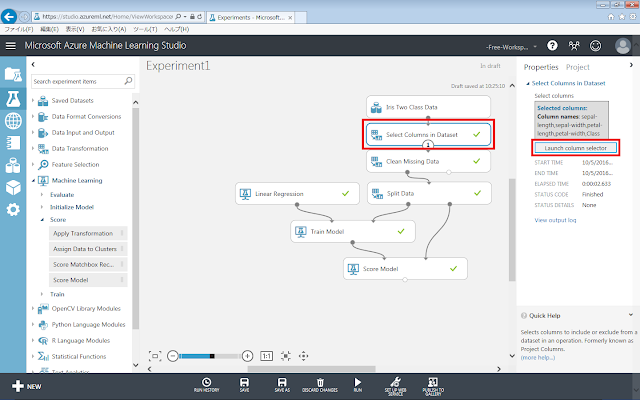
すべての列を選択するように設定して、「☑OK」ボタンをクリックします。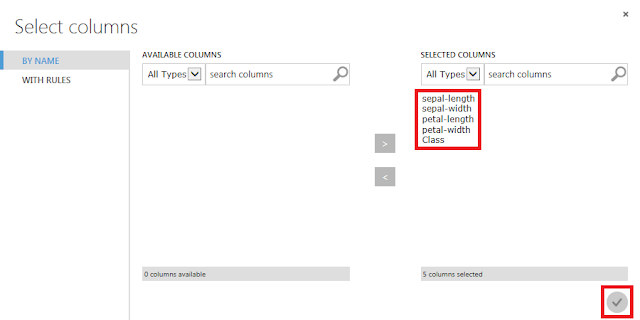
続いて、予測させる特徴を指定します。
Train Modelが選択された状態で、右側にあるLaunch column selectorをクリックします。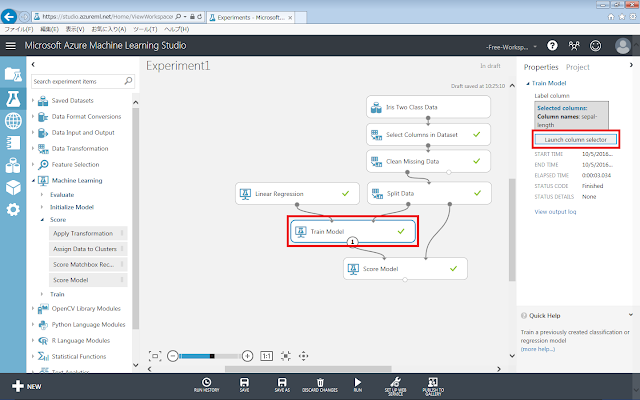
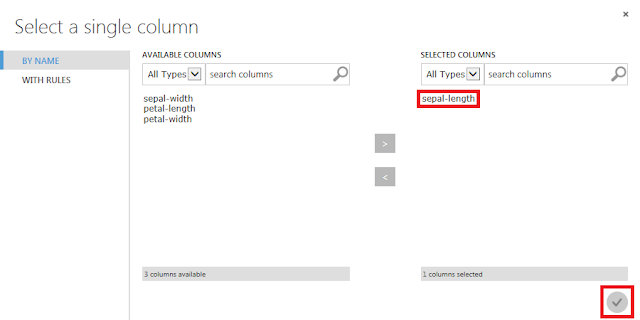
「sepal-length」列を選択して、「☑OK」ボタンをクリックします。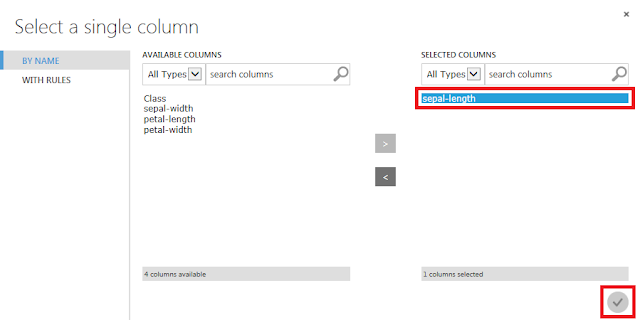
3.1.2.回帰分析の実行
「Run」メニューをクリックして、「Iris Two Class Data」データセット以外の各モジュールに緑色のチェックマークが表示されていることを確認します。
Score Modelの下部の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックして、分類結果を確認します。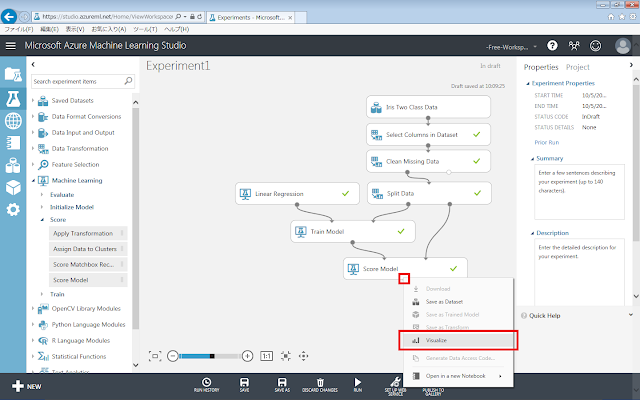
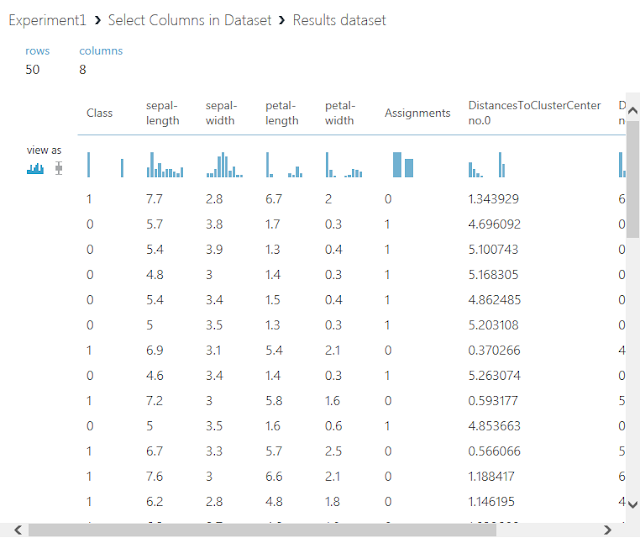
データセットに含まれるデータが表形式で表示されます。
右側のcompare toで、データセットに本来含まれている正答の列名を選択すると、予測結果と正答を比較したグラフを表示させることができます。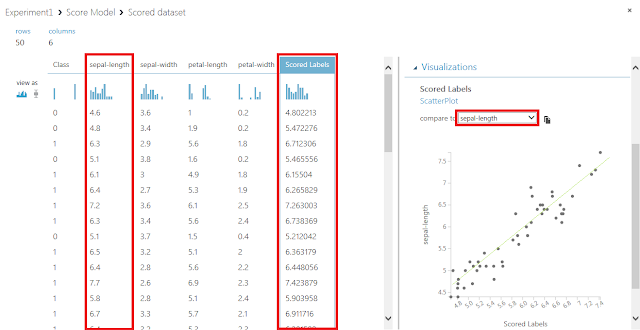
このグラフは、横軸に予測値を、縦軸に正答値をとって点が打たれているため、左下から右上に向けて線を引き、この線に近いところに点が集まるほど精度が高い予測を行うことができていることになります。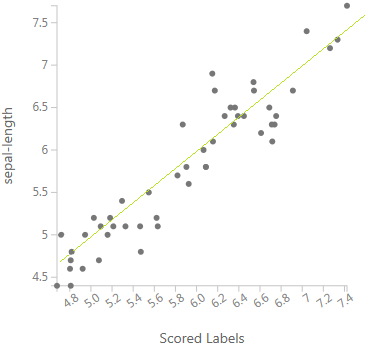
3.1.3.予測結果の評価方法
回帰分析において学習モデルの性能評価に用いられる指標としては、以下のものがあります。
F 値
…回帰式に使用した説明変数のいずれかが従属変数に影響を与えているか、すべてが従属変数に影響を与えないかを調べるために使用します。性能を評価するというよりも、そもそも使用している学習モデルとデータセットの選び方に問題はないかを評価するための指標だと言えます。F値による判定はあくまでも最低限の基準であり説明変数のうち1つでも従属変数に影響を与えていれば高い値になってしまうので、後述する他の指標による確認を行う必要があります。
決定係数R²
…回帰モデル全体がデータセットとどれくらい適合しているか(回帰の当てはまり具合)を調べるために使用します。実際には、説明変数の数が増えたときの影響を補正する「自由度修正済決定係数」という指標がよく使用されます。自由度修正済決定係数は通常の決定係数とは異なり、マイナスの値をとることがあります。決定係数、自由度修正済決定係数とも一般に、絶対値が0.5を超えれば当てはまりの良い回帰モデルが構築されていると判断し、絶対値が0.8以上になると非常に当てはまりの良い回帰モデルだと言われます。
t 値
…回帰式で使用されている説明変数(データ列)のそれぞれが予測結果に与える影響の強さを示す指標で、絶対値が大きいほど影響が強いことを示します。一般に2を超えれば適切なモデルが構築されていると判断します。
p 値
…回帰式で使用されている説明変数(データ列)のそれぞれが従属変数に影響を与えていない確率を調べるために使用します。説明変数が従属変数に影響を与えているほうが良いモデルなので、p値は0に近いほうが望ましいといえます。
例として、アヤメのデータセットに対して回帰分析を行い、各評価指標を求めたものを以下の表に示します。性能が良い回帰の例には、①花びらの幅「Petal.Width」と花びらの長さ「Petal.Length」の関係を表す回帰式を、性能が悪い回帰の例には、②乱数「Random」と花びらの長さ「Petal.Length」の関係を表す回帰式を挙げます。乱数を使用している都合上、例②の詳細な数値は実行するたびに変化するので、表中のものと完全に一致することはありません。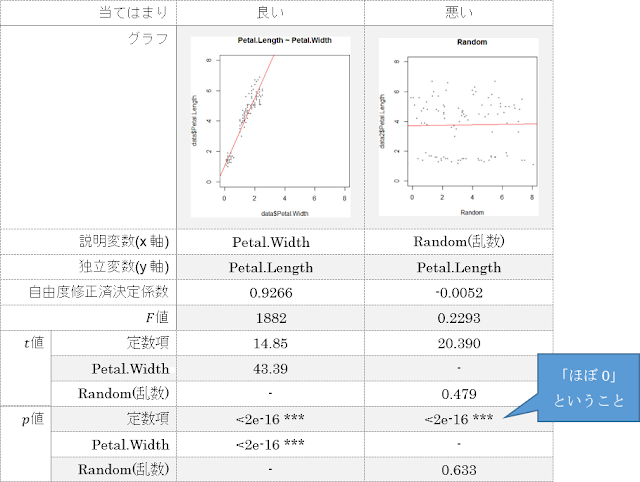
いずれの指標に関しても、例②よりも例①のほうがはるかに精度良く当てはまっていることを示しています。例えば、わかりやすい指標として自由度修正済決定係数を見てみると、例①では1に近い値なので学習モデル全体としてデータへの当てはまりが良いことがわかります。一方例②では、0に近い値なので、あてずっぽうで独立変数の値を決めているのと同じくらい当てはまりが悪いことがわかります。
また、学習モデル全体ではなくそれぞれの説明変数ごとに評価するわかりやすい指標としてp値を見てみると、例①では定数項、説明変数「Petal.Width」ともに0に近い値になっていて、独立変数へ与える影響がどちらも強いといえます。一方例②では、定数項のp値は0に近い値になっているものの、説明変数「Random」の 値は と1に近づいています。つまり、例②のp値の比較から、定数項が独立変数へ与える影響が強すぎて、乱数が独立変数へ与える影響はかなり弱いといえます。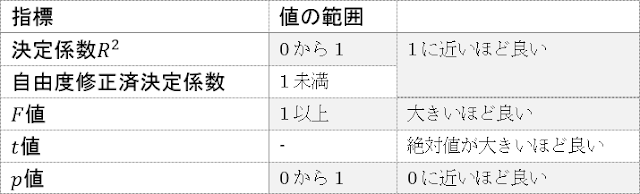
ちなみに、表中の「<2e - 16 」は、「2×10のマイナス16乗 よりも小さい」ため計算結果がほぼ「0」に近い値であることを示します。これはコンピュータが計算する過程で、計算対象の数を「浮動小数点数」という形式で扱うために、このような表記となっています。
3.2. クラスタリング
クラスタリングを行う手順について説明します。
今回も、Azure ML上に予め用意されている、アヤメの統計データを用います。この統計データに含まれている特徴のうち、品種名を除いたアヤメの花びらの長さと幅から、類似するグループ(=品種)ごとに分割させる学習モデルを作ることになります。
3.2.1.学習ロジックの作成
まず、初期化モジュール、学習モデル、計算モジュールをクラスタリングのものに変更します。クラスタリングでは、この3種類のモジュールとして、K-Means Clustering、Train Clustering Model、Assign Data to Clustersの組み合わせのみ利用することができます。また、結果をクラス分類と同様の表形式で確認するために、「Select Columns in Dataset」モジュールも追加します。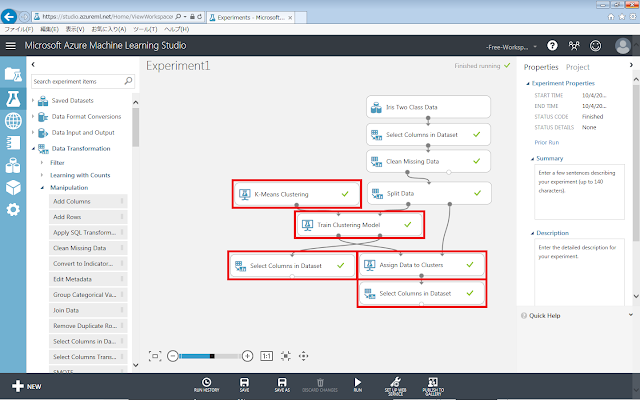
すべての「Select Columns in Dataset」モジュールで、すべての列を選択するように設定します。
3.2.2.クラスタリングの実行
学習データに対するクラスタリング結果を確認します。
学習モデル(Train Clustering Model)の左下の丸印には学習済みモデルが、右下の丸印には学習結果のデータセットが出力されます。
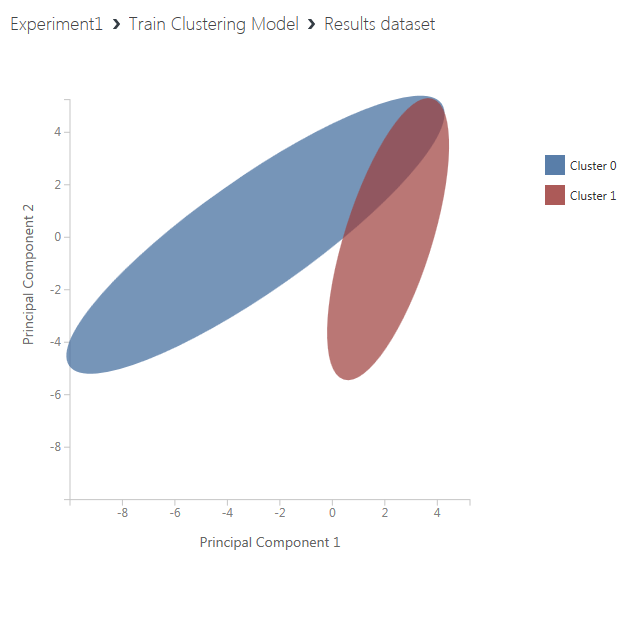
まず、学習モデル(Train Clustering Model)の右下の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックして、クラスタリング結果の図を確認します。
次に、同じデータセットを表形式で確認する場合は、学習結果のデータセットの出力に接続されている「Select Columns in Dataset」モジュールの丸印をクリックすると現れるメニューのうち、「Visualize」をクリックします。
続いて、評価データに対しタリングを行った結果を確認します。
計算モジュール(Assign Data to Clusters)の下部の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックして、クラスタリング結果の図を確認します。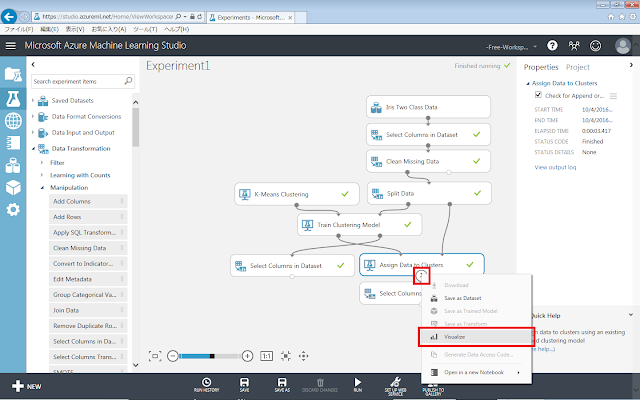
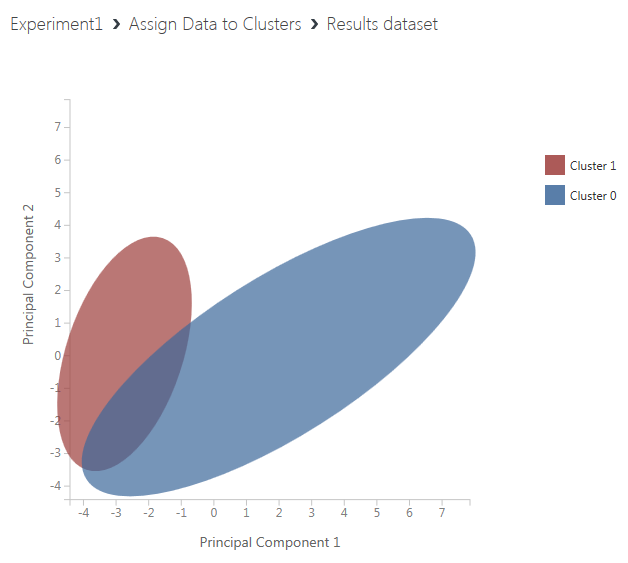
そして、同じデータセットを表形式で確認する場合は、Assign Data to Clustersに接続されている「Select Columns in Dataset」モジュールの丸印をクリックすると現れるメニューのうち、「Visualize」をクリックします。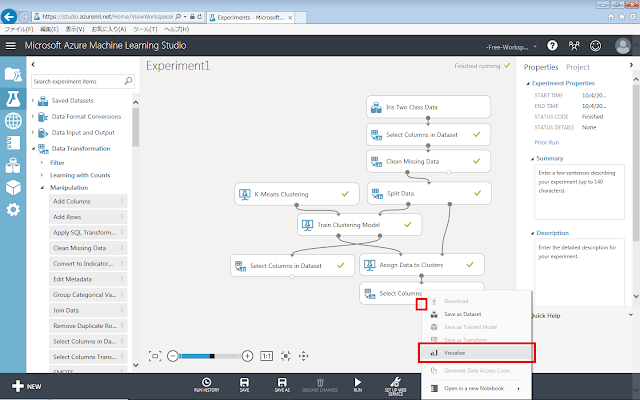
3.2.3. 分割結果の評価方法
クラスタリングの場合には、正答データ(教師データ)が存在しないため、正答データとの比較によって評価ができません。そのため、入力されたデータセットと分割結果に矛盾が起こっていないか、類似したデータが別のクラスタに分割されていないかといった事項だけを検証することになります。
しかし、予めラベル付けされたデータをホールドアウト法とともにクラスタリングした場合や、クラスタリングと並行してクラス分類を行った場合などで正答データも手に入れることができる場合には、以下のような評価指標も利用することができます。
l エントロピー
各クラスタに含まれる(正答)クラスの種類の多さを示す指標で、値が小さいほど良好に分割されていることを示す。
l 純度
各クラスタに含まれるクラスのうち最多のものが占める割合の平均を示す指標で、値が大きいほど良好に分割されていることを示す。
例として、アヤメのデータセットにおいてK平均法によってクラスタリングを行ったときの散布図とエントロピー、純度を表の(ii)に示します。同様に、クラスタのラベルを乱数によって設定することで全くクラスタリングできていない状況を再現した結果を(i)に、正答を評価することで完全にクラスタリングを行うことができている状況を再現した結果を(iii)に示します。
本来は3つ以上のクラスタが存在する場合であってもエントロピーや純度を計算することは可能ですが、話を簡単にするために今回は以下の表のように品種をまとめて2つの種類とします。もともとアヤメのデータセットに含まれる3品種のうち、versicolorとvirginicaはsetosaと比較すると類似しているという特徴があるため、このようなまとめかたをとりました。
分割結果、エントロピー、純度を以下に示します。散布図の色分けだけでは判断しづらいクラスタリングの評価も、エントロピーや純度という数値の形で表すことによって結果の良し悪しの判断や他の結果との比較が容易に行えることがわかります。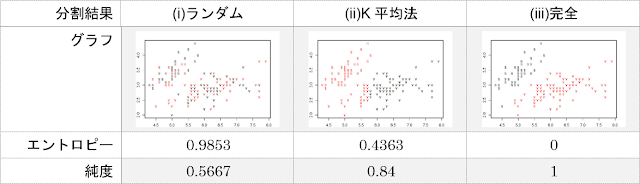

今回のクラスタリング(教師なし学習)では、ラベル(正答)付けされていないデータを学習させ、評価のときにはじめてラベル付けされたデータを使いましたが、評価だけでなく、学習にもラベル付けされているデータを入力する手法があり、半教師あり学習と呼ばれます。
一般に、ラベル付けされていないデータは大量に取得することが容易であるので、学習用データのすべてに対してラベル付けを行わずに済むと、学習させるデータ量を増やしたいときや、ラベル付けをするためのデータ分析に専門知識が必要なときでも、コストを抑えることができるという特長があります。
3.3.アノマリ検知
アノマリ検知を行う手順について説明します。ここまでに取り上げた各学習手法とは扱うデータや予測させたい情報の特徴が異なることから、本節では、Azure ML上に予め用意されている、クレジットカード申請の統計データを用いて学習手法を紹介します。この統計データに含まれている20種類の特徴量から、異常値を検出させる学習モデルを作ることになります。
3.3.1.学習ロジックの作成
まず、データを配置します。
Saved Datasets→Samples→German Credit Card UCI datasetを、画面中央の灰色の領域に配置します。
次に、データの事前加工を行うためのモジュールを配置していきます。
データの加工内容は、以下の通りです。
① もとのデータの最終列の列名を「Label」へ変更
② もとのデータ全体を学習データと評価データへ分割
③ 学習データの一部を、パラメーター調整用の検証データとして抽出
④ 学習データのうち、正常データであることを示す値が最終列に格納されているデータのみを通過
⑤ 検証データを含む学習データのうち、正常データであることを示す値が最終列に格納されているデータのみを通過
続いて、アノマリ検知のためのモジュールを配置していきます。
初期化モジュールPCA-Based Anomaly Detectionを、画面中央の灰色の領域に配置します。さらに、学習パラメーターを調整するためのモジュールTune Model Hyperparametersを、画面中央の灰色の領域に配置します。
そして、訓練モジュールTrain Anomaly Detection Modelを配置します。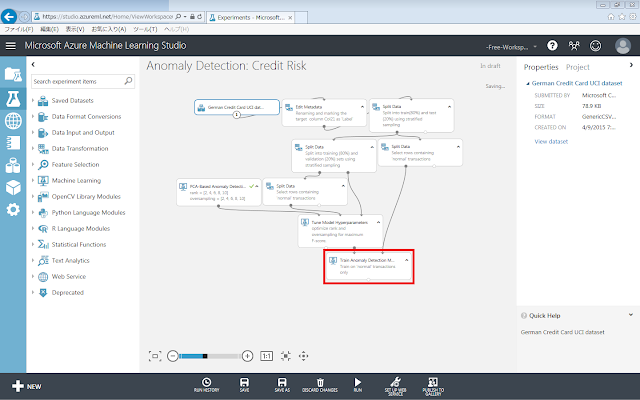
Score Modelモジュールを、画面中央の灰色の領域に配置します。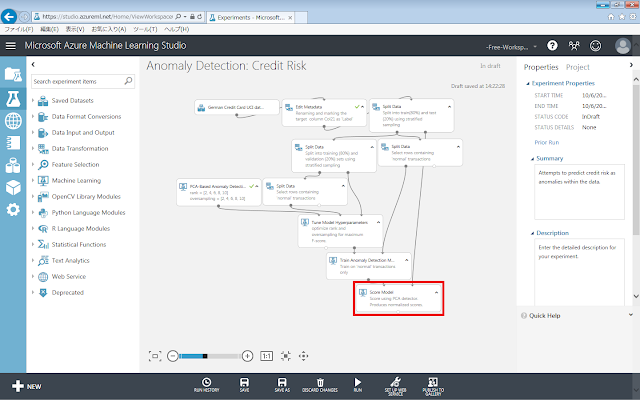
次に、検知性能を示すグラフを表示させるためのモジュール「Evaluate Model」モジュールを、画面中央の灰色の領域に配置します。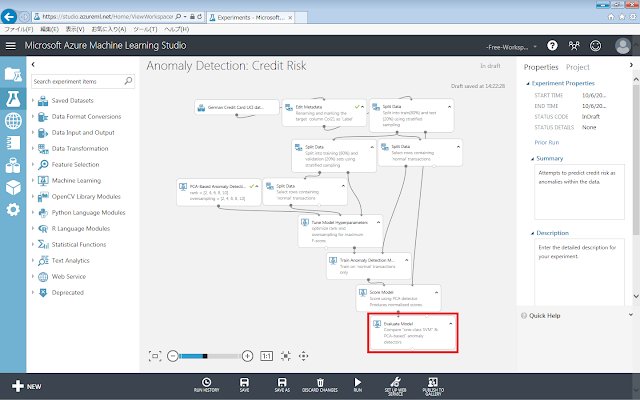
配置したモジュールのプロパティを設定していきます。
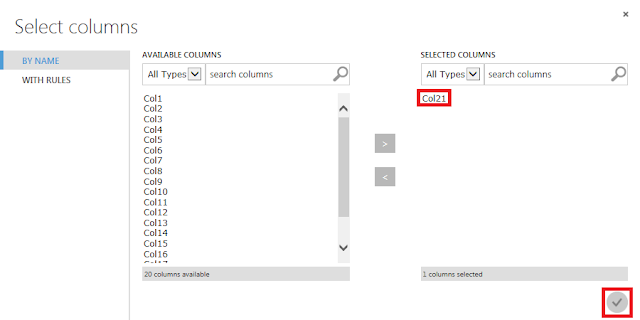
もとのデータの最終列の列名を「Label」へ変更するための設定を行います。「Edit Metadata」モジュールが選択された状態で、右側にある「New column names」テキストボックスに「Label」と入力後、「Launch column selector」ボタンをクリックし、表示された画面で「Col21」列を選択します。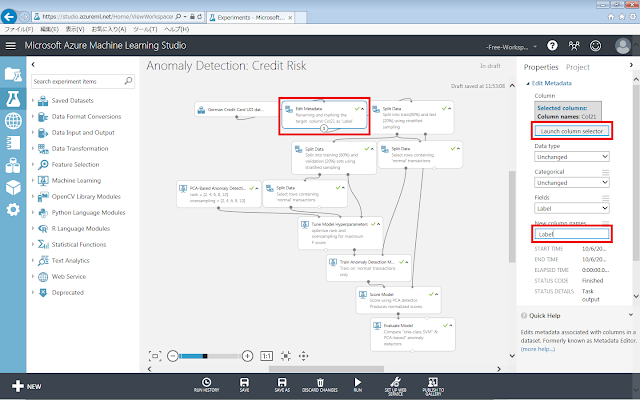
もとのデータ全体を、80%の学習データと20%の評価データへ分割するための設定を行います。「Edit Metadata」モジュール直後の「Split Data」モジュールが選択された状態で、下図の通りプロパティを設定します。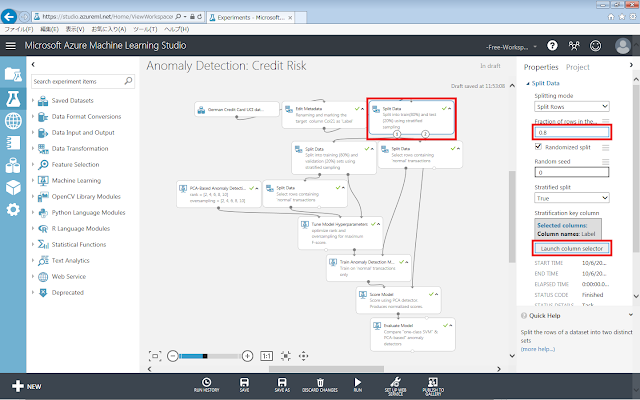
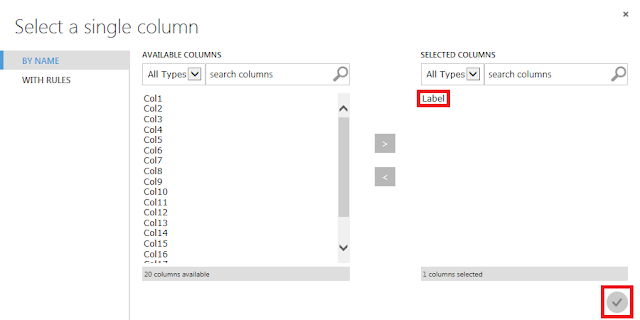
学習データの20%を、パラメーター調整用の検証データとして抽出するための設定を行います。2つ目の「Split Data」モジュールが選択された状態で、下図の通りプロパティを設定します。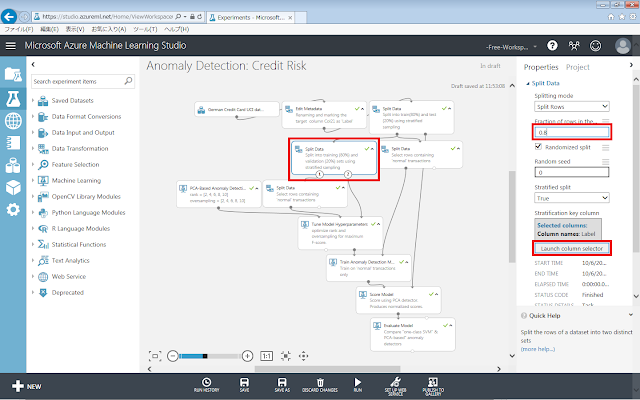
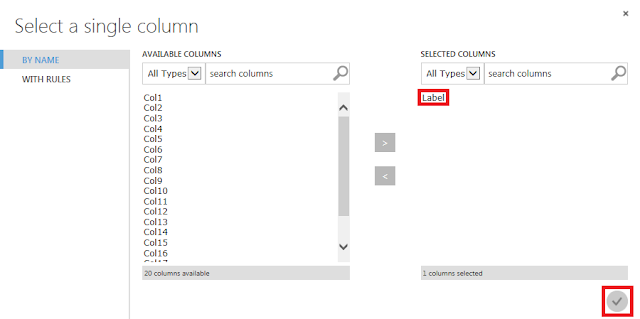
正常データのみを通過させるための設定を行います。残り2つの「Split Data」モジュールそれぞれに対して、下図の通りプロパティを設定します。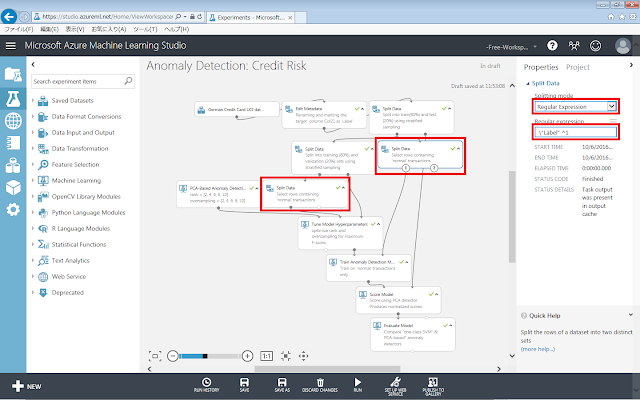
初期化モジュールのプロパティを、下図の通りすべて変更します。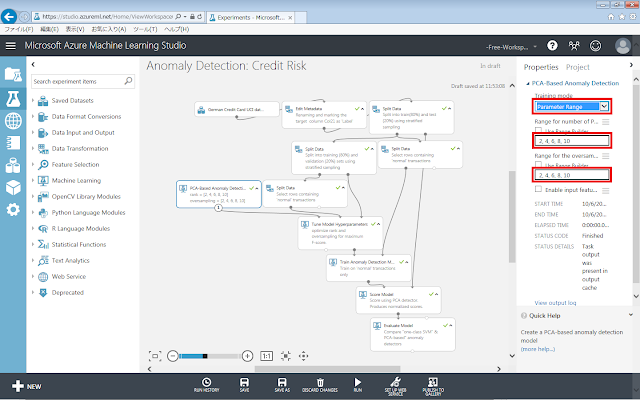
Tune Model Hyperparametersモジュールのプロパティを、下図の通り変更します。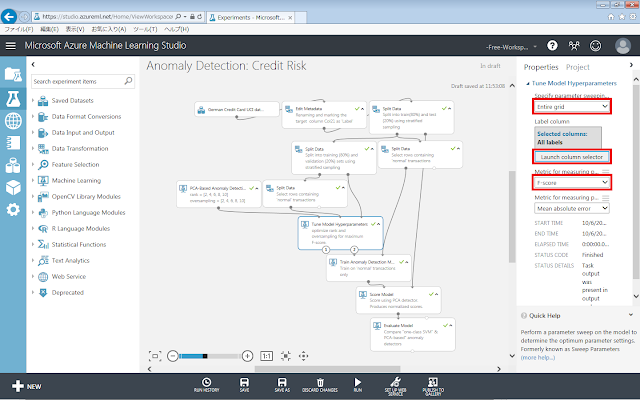
3.3.2.アノマリ検知の実行
作成した学習モデルを使用して評価データに対するアノマリ検知の結果を確認します。
「Run」メニューをクリックします。
「Evaluate Model」モジュールの下部の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックして、結果を示すグラフを確認します。
表示されるグラフはROC曲線と呼ばれる図で、検知性能が優れているほど曲線がより左上隅に近づくという特徴があります。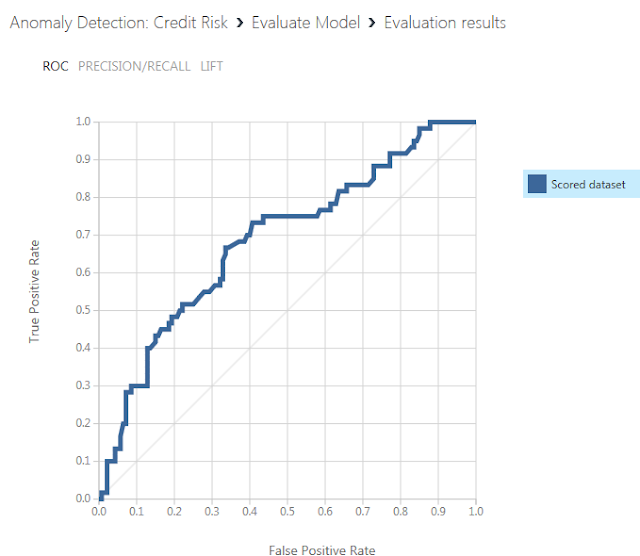
3.3.3.検知結果の評価方法
アノマリ検知の結果を評価するためには、クラス分類やクラスタリングの精度評価と同様に、データへのラベル付けが必要になります。ラベル付けを行った後は、クラス分類と同様の指標を用いて定量的に評価することができます。しかし、単にラベルづけを行っただけでクラス分類と同様の評価方法を行ってしまうと、分類精度の値が見かけ上非常に悪くなると考えられます。
アノマリ検知で使用するデータセットには、中に含まれるデータのうち、「通常データ」と比べて「異常データ」がはるかに少ないという特徴があります。このようなデータセットのことは「不均衡データ」と呼ばれ、クラス分類の学習モデルにそのまま投入しても、分類精度が大きく低下してしまいます。これを避けるためには、学習モデルのパラメーターを調整して「異常データ」の影響力を強めるか、「オーバーサンプリング」、「アンダーサンプリング」と呼ばれる手法によって「異常データ」のデータ数を見かけ上増やしてから評価する必要があります。
Azure Machine Learningには、オーバーサンプリングするためのモジュールとして、「Data Transformation」→「Manipulation」→「SMOTE(Synthetic Minority Oversampling Technique)」モジュールが用意されています。SMOTEを使うことで、もとのデータセットに含まれている少数のデータをそのままコピーするだけでなく、近傍データの特徴と組み合わせて新しいデータを作り出すことができます。
まず、SMOTEモジュールを灰色領域に配置します。次にデータセットからSMOTEモジュールまでを線で結びます。SMOTEモジュールが選択された状態で、右側のパネルにある「SMOTE percentage」テキストボックスの数値を「100」よりも大きい値に変更します。
Azure Machine LearningのSMOTEモジュールには、現状ではアンダーサンプリングの機能は実装されていないため、アンダーサンプリングを行ったり、オーバーサンプリングとアンダーサンプリングを同時に行ったりしたい場合には「Execute R」モジュールを使って自分で実装する必要があります。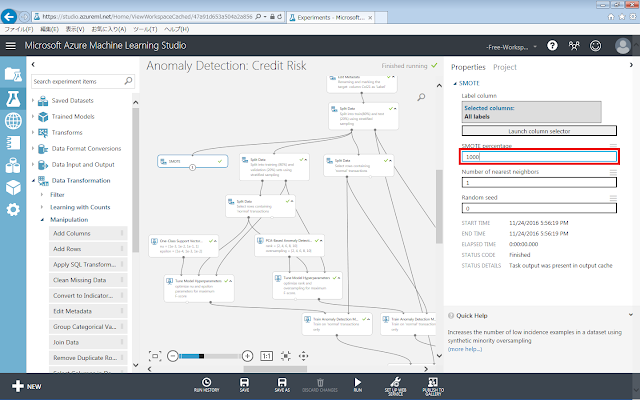
ここまでにいくつかの実験を作成し、評価を行いました。指標を用いて具体的な数値の形で評価したことで、分類・予測精度に課題があると感じた方もいらっしゃるのではないかと思います。今回は、予測精度を向上させるための手法や手順を紹介し、改善前の予測精度と比較していきます。
4.予測精度向上のために
4.1.初期化モジュールの調節による予測精度改善
本節では、2章で作成したLinear Regressionモジュールによる回帰モデルをベースに、初期化モジュールのパラメーターを調節したり、Linear Regressionのモジュールの代わりに、同じ回帰分類手法に属する他の初期化モジュールを用いて学習モデルを作成したりすることで精度の改善を図ります。
まず、初期化モジュールのパラメーターを調節することで精度向上を図るための操作手順を紹介します。はじめに比較対象となる、前回の記事で 作成した学習モデルを以下に示します。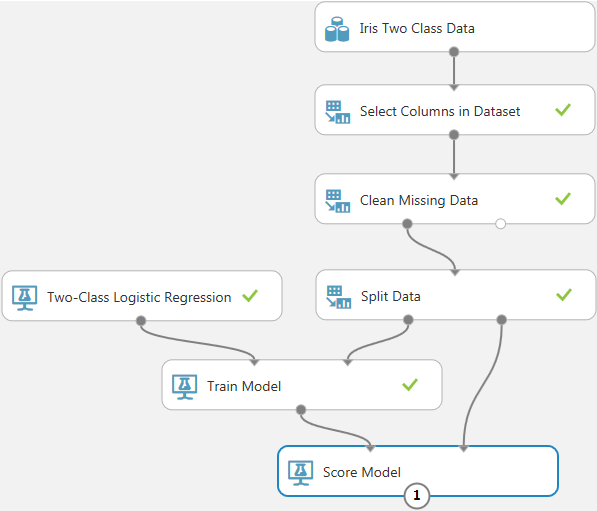
この学習モデルへ入力するデータ列としてSepal-Widthのみを使用した分類の結果を眺めてみると、すべての分類結果に同じ「0」が出力されています。つまりまったく学習されていません。本来はこのようなデータ列を学習に使用することはありませんが、ここではパラメーターを調整して学習させる例として、敢えて使用してみます。
調整手順の例として、学習パラメーターの指定を単独の値から範囲指定へと変更する場合は、「Two-Class Logistic Regression」モジュールが選択された状態で右側のパネルにある「Create trainer mode」リストボックスの値を「Single Parameter」から「Parameter Range」へ変更します。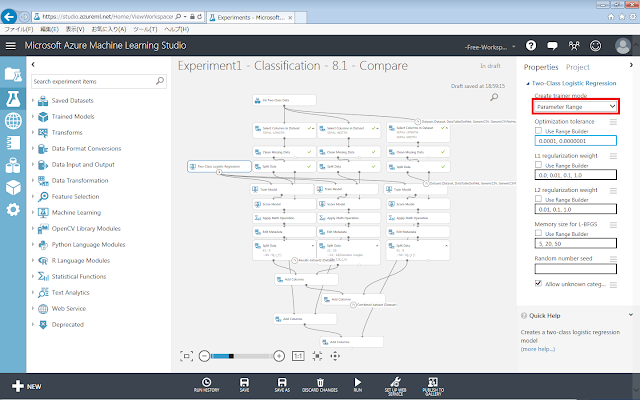
Sepal-Widthの場合は、初期化モジュールを「Two-Class Logistic Regression」から「Two-Class Decision Jungle」へ変更したところ、正答率は64%となりました。また、初期化モジュールに「Two-Class Logistic Regression」を使用したままパラメーターを範囲指定へと変更したところ、正答率が76%へ向上しました。
続いて、初期化モジュールを他の学習手法のものと交換することで精度向上を図るための操作手順を紹介します。
はじめに比較対象となる、2章で作成した学習モデルを以下に示します。この学習モデルの、Linear Regression、Train Model、Score Model、Evaluate Modelモジュールの部分と並列に、他の初期化モデルによる学習ロジックを追加していきます。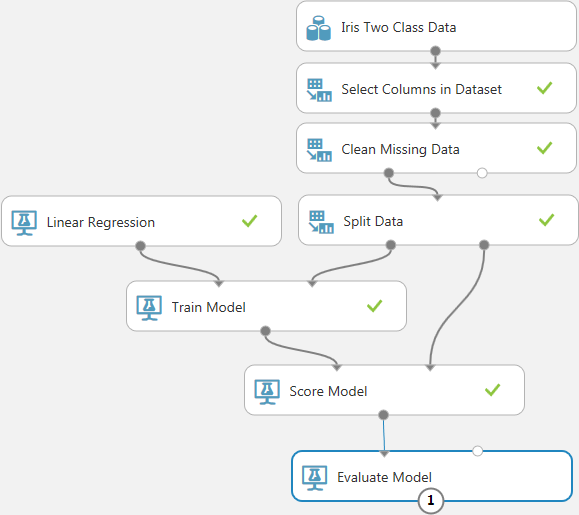
ここで、Azure Machine Learningの左側のパネルにある、回帰分類(Regression)カテゴリの学習アルゴリズム(初期化モジュール)を見てみます。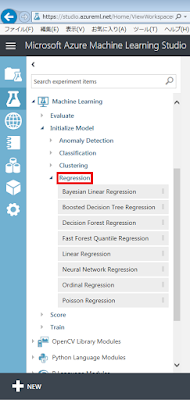
各アルゴリズムを比較した表を以下に示します。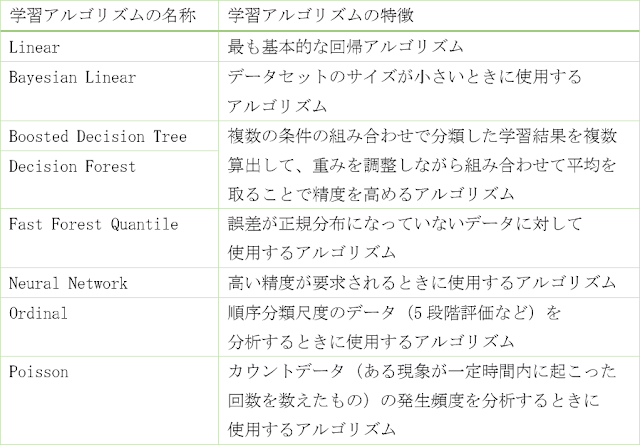
今回はこれらのうち、Bayesian Linear Regression、Boosted Decision Tree Regressionによる学習ロジックを追加してみます。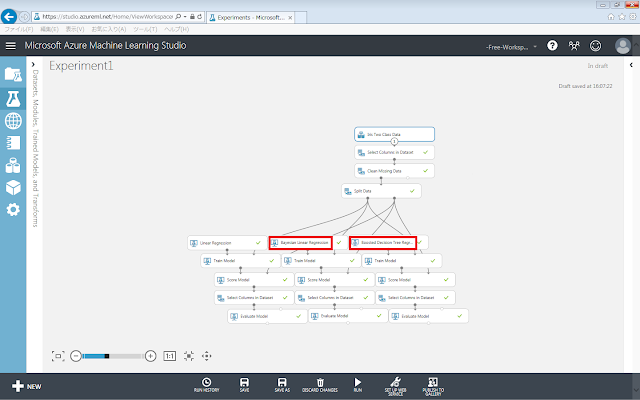
続いて、Neural Network Regressionによる学習ロジックを追加した上で、それぞれの学習ロジックに、パラメーターを自動調整するための「Tune Model Hyperparameters」モジュールを追加し、レイアウトを整えた例を以下に示します。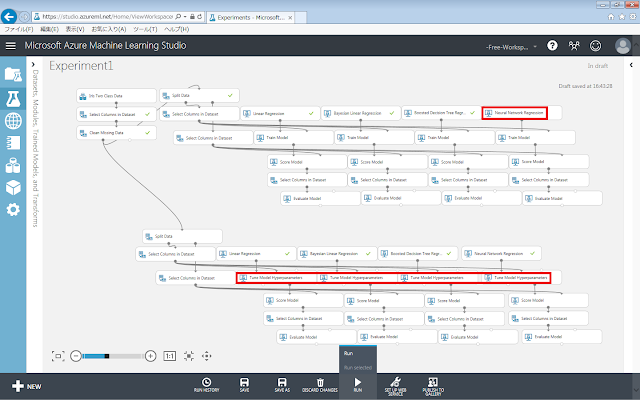
既に実験の中にTrain Modelモジュールが存在している場合は、Train Modelモジュールを除去した上で、同じ位置にTune Model Hyperparametersモジュールを追加します。追加した「Tune Model Hyperparameters」モジュールのプロパティを設定します。
まず、「Specify parameter sweeping mode」で、「Entire grid」を選択します。次に、「Launch column selector」ボタンをクリックし、開いた画面でsepal-lengthを選択して、「☑OK」ボタンをクリックします。これを、すべての「Tune Model Hyperparameters」モジュールに対して行います。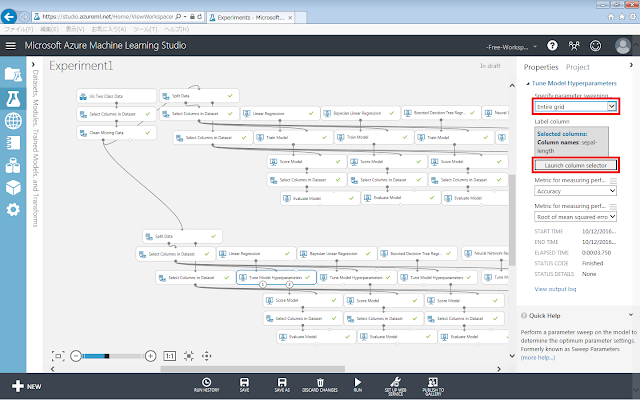
これらの学習モデルで得られた予測結果と、もともとデータセットに含まれている正答との比較を行います。実験の各分岐先の末尾に存在する「Evaluate Model」モジュールの下部の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックします。
Bayesian Linear Regressionによる予測のみ評価項目が若干異なりますが、すべての「Evaluate Model」モジュールで共通して出力される項目をまとめると、以下の表のようになります。表示される評価項目のうち、決定係数(Coefficient of Determination)のみは、値が大きいほど予測能力が高いことを表しています。他の評価項目(Error)は、値が小さいほど予測能力が高いことを表しています。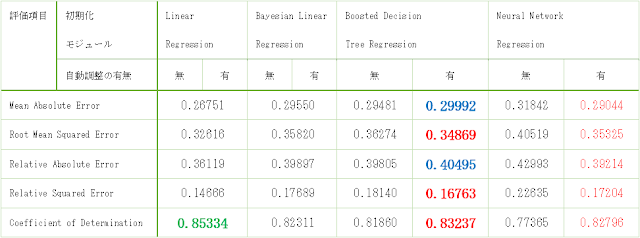
まず、決定係数(Coefficient of Determination)を確認してみます。すべての学習ロジックについて決定係数を比較すると、Linear Regressionによる予測が最も大きい値であり、よい結果であることがわかります。
次に、「Tune Model Hyperparameters」モジュールによるパラメーターの自動調整の効果を確認してみます。Linear RegressionおよびBayesian Linear Regressionによる学習結果は、パラメーターの自動調整の有無によらずに同じ結果になりました。また、Neural Network Regressionでは調整後の結果の方が良くなっていた一方、Boosted Decision Tree Regressionでは調整後の結果よりも調整前の結果の方が一部の評価項目では良い値が得られました。
このように、学習アルゴリズムやパラメーターは、常に優れた結果を得られるアルゴリズムがあってそれを使用して学習させればよいというものではなく、学習のもととなるデータセットの特徴や、得られる出力結果の特徴、どのように評価するかといった判断材料に応じて、ユーザーが選択する必要があります。
ここまで回帰分析を例に手順を紹介しましたが、クラス分類の場合にも同様にモジュールを入れ替えたり、パラメーターを変更したりすることで精度が向上する可能性があります。クラス分類に使用できる学習アルゴリズムの一覧を以下の表にまとめます。
これらの学習アルゴリズムに対応する初期化モジュールを配置した実験の例を以下に示します。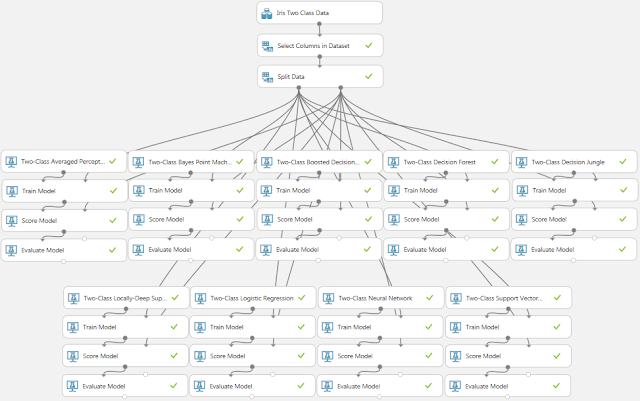
この実験での分類結果を以下の表にまとめます。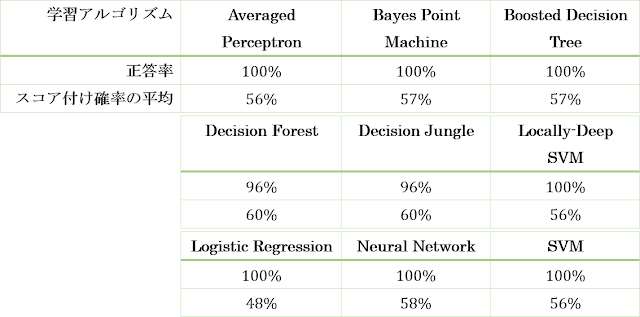
スコア付け確率の平均というのは、「Score Model」モジュールでVisualizeメニューを実行したときに表示される表にある「Scored Probabilities」(スコア付け確率またはクラス帰属確率)の平均値を求めたものです。今回の分類問題は2値分類なので、スコア付け確率がしきい値(例えば0.5)よりも大きいか小さいかによって1と0に分類されます。つまり、あるデータに対して同じ0という分類結果が得られた場合には、使用した学習アルゴリズムごとにスコア付け確率は0.1だったり0.2だったりしますし、1という分類結果が得られた場合には、0.9だったり0.8だったりします。このような学習アルゴリズムごとの分類過程の違いを簡単に確認するために、スコア付け確率の平均値を求めて表に載せてみました。スコア付け確率自体を比較して何らかの評価に使うというわけではありませんが、複数の学習アルゴリズムで同じ正答率を取る場合であってもスコア付け確率にはばらつきが現れることを確認するには十分だと思います。データごとのスコア付け確率をそれぞれ確認したい場合には、「Score Model」モジュールの下部端子でVisualizeメニューを実行します。Scored Probabilities列を選択した状態でScored Labelsと比較した散布図を表示してみると、先ほど説明した内容を視覚的に確認することができます。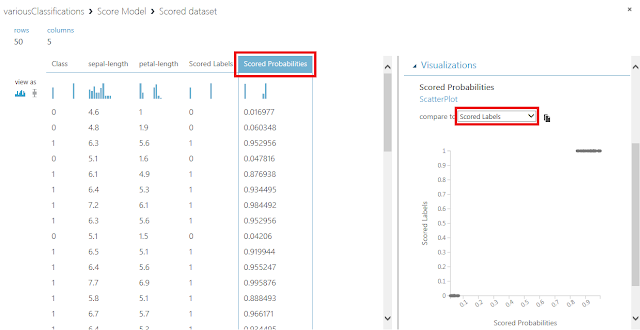
先ほどの説明の中で、しきい値0.5を境に0、1 の分類結果が変化するとしましたが、このしきい値を他の値に変更した上で分類を行うこともできます。しきい値を変化させたときにどのような分類結果が得られるかを確認するためには、「Score Model」モジュールに接続された「Evaluate Model」モジュールの下部端子でVisualizeメニューを実行し、表示された画面にあるスライダーを左右に動かすことで確認することができます。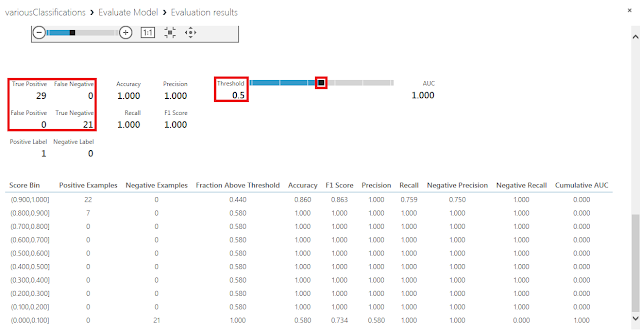
極端な例ですが、しきい値0.05に変更した例を以下に示します。しきい値が0.5の時と比較するとTrue Negativeの件数が減少してFalse Positiveの件数が増加したことがわかります。つまり、スコア付け確率が0.05から0.5の間にある3件のデータが、本来分類されるべき結果は0であるにも関わらず1だと判定されてしまったことがわかります。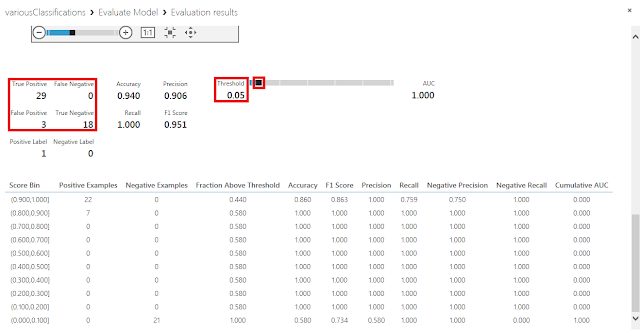
逆に、しきい値を0.95に変更した例を以下に示します。今度はTrue Positiveの件数が減少してFalse Negativeの件数が増加したことがわかります。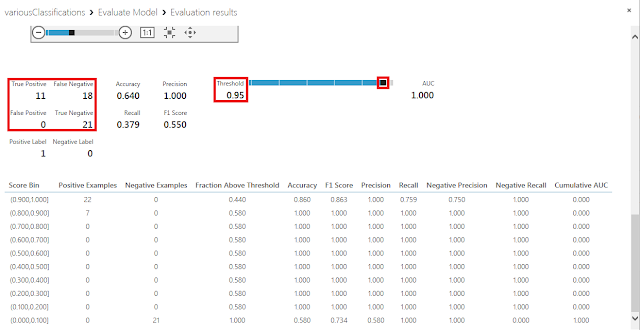
クラスタリングおよびアノマリ検知については選択肢がない(アノマリ検知は2種類のモジュールがありますが、線形モデルと非線形モデルが1つずつしかなく、選択の余地がない)ので、異なる学習アルゴリズムに変更したい場合には、Execute R Scriptモジュールなどを使用して自分で実装する必要があります。
Azure Machine Learning上に用意されているクラスタリング手法は「K-Means Clustering」(K平均法)というアルゴリズムのみですが、他にも以下の表に示すようなクラスタリング手法があります。また、アノマリ検知についても、表に示すようないくつかのアルゴリズムが存在するので、自分で実装することで、手法の比較が可能です。
また、データ同士の「距離(類似度)」の求め方にも以下の表に示すような種類があります。2つのデータが類似しているほど、距離は小さく、類似度(の絶対値)は大きな値をとります。このため、類似度を距離の代わりに使用する場合には、1から類似度を引いたものを距離として扱います。
4.2.時系列データ
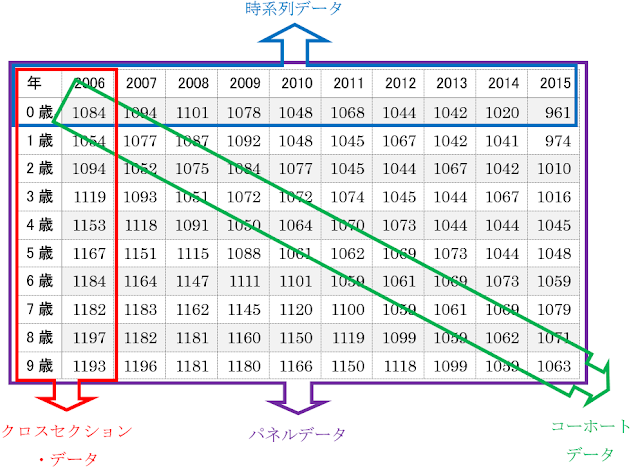
ここまで使用してきたアヤメのデータセットには、時間の概念が含まれていませんでした。そのため、クラス分類や回帰分析によって学習させるときにも時間について意識する必要がありませんでした。しかし、現実のデータを分析する場合、時間的な関係を考慮しないと精度が高まらないことがあります。気象や人口、臨床検査値、株価の統計情報などが当てはまり、このようなある事柄について時間に沿って集められたデータを時系列データと呼びます。時系列データの他にも、データの集計方法の違いから、データセットの種類には以下のようなものがあります。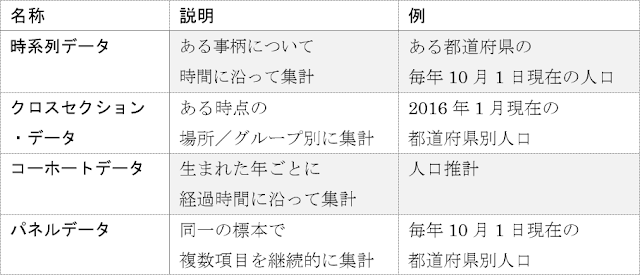
時系列データの値の変動は、「長期変動」、「季節変動」、「不規則変動」によって発生します。特に季節変動は、天気や気温といった気候の周期的な変化や、暦の周期性などの季節要因によって多くのデータセットで発生します。年別のデータであれば、季節変動を気にせずに済みますが、四半期別や月別など、より細かい単位で集計されたデータセットを用いる場合には考慮する必要が出てきます。季節変動の影響を除去する操作を「季節調整」と呼びます。季節調整の手法には以下のようなものがあります。
また、時系列データを使用する上で気をつけなければならない点として、名目値と実質値というものがあります。よく「実質GDP」といった言葉がニュースなどで放送されるので耳にしたことはあるのではないかと思います。名目値というのは額面通りの価値の数量を指し、実質値というのは物価など価値の尺度そのものの変化を考慮して、名目値を修正した数量を指します。
時系列データをAzure Machine Learning上で扱う手順については、後日紹介します。
今回は、予測モデルのそれぞれのモジュールの解説や予測精度の改善策、他の手法で予測させるときの操作手順の紹介をしました。次回以降は、独自処理を行うモジュールを作るための拡張方法や、Azure Machine Learningのサンプルデータではなくオープンデータをもとにした予測方法、作成した予測サービスをインターネットへ公開するための手順を紹介します。こうして公開された予測サービスは、ExcelシートやC#アプリケーションから呼び出して利用することができます。ビジネスで活用するためにはAzure Machine Learning内で完結するのではなく、アプリケーションとの連携が重要になるので、ぜひ習得してください。

