記事公開日
最終更新日
第5回 学習結果の評価
第1回では機械学習の解説と、学習を始める前準備としてプロジェクトまで。
第2回~第4回では実験内容を構築し実際に機械学習を行ってみました。
第5回となる今回は、学習結果の評価を行っていきます。
第1章 学習結果の評価
1. 分類結果の評価方法
学習結果を評価するために使用する評価指標について紹介します。
アヤメのデータセットの「Class(品種)」列のように、分類対象のデータ列の値が「0」または「1」を取るような2値分類を例に挙げます。
まず、予測結果のクラスと正答のクラスの関係は以下の4通りがあります。TPとTNは予測に正解していることを、FPとFNは予測に失敗していることを示します。
続いて、これらを組み合わせて計算する評価指標を表に示します。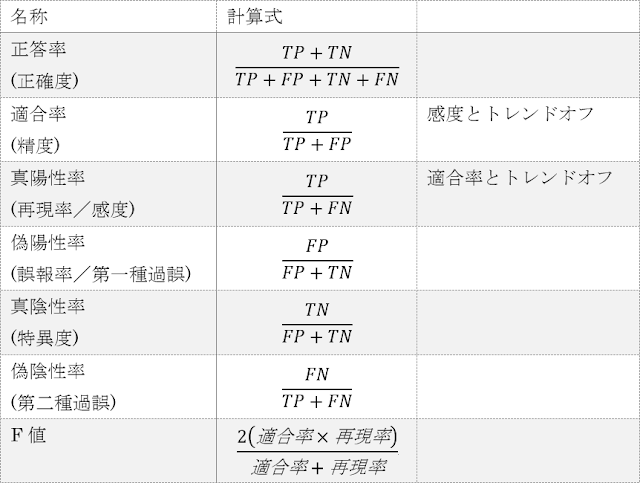
TP,FP,TN,FNの4つの値の組み合わせから求めるために評価指標の種類が多くなっていますが、基本的には正答率を使用します。しかしながら、例えばアンチウイルスソフトの性能評価のように、真の値の正例・負例のどちらかを重要視する場合には、式の中の「P」や「N」の数が偏っているような、正答率以外の指標を用います。
また、縦軸にTPを、横軸にFPを当てはめたグラフであるROC(Receiver Operating Characteristic)曲線や、ROC曲線の下側の面積であるAUC(Area Under the Curve)値も、精度評価によく利用されます。以下の表に、2通りのパラメーターを入力してクラス分類をさせてみたときのROC曲線およびAUC値の例を示します。図の中の斜線をかけた領域の面積がAUC値になります。
ROC曲線では、グラフの線が左上の角に近づくほど分類精度が高いことを示します。つまりROC曲線のグラフの線が左上の角を通るときに最も分類精度が高いといえるので、ROC曲線の下側の面積であるAUC値が1のときに最も分類精度が高いことになります。右の図と比べると左の図では、全体的に左上の角に近づいているため、右のクラス分類よりも左のクラス分類の精度のほうが高いことを示しています。
一方で、右の図ではROC曲線がほぼ対角線に沿っていて、AUC値も0.5に近いことから、まったく分類できておらず、ランダムに振り分けたときと同じ状態だといえます。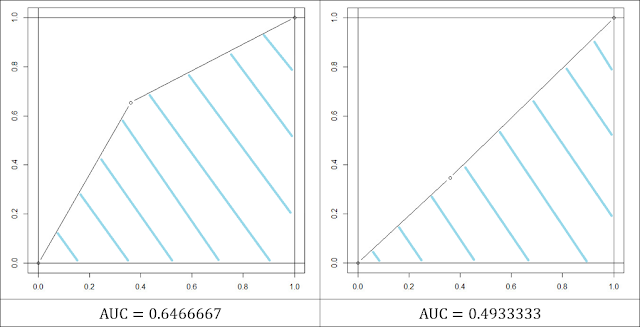
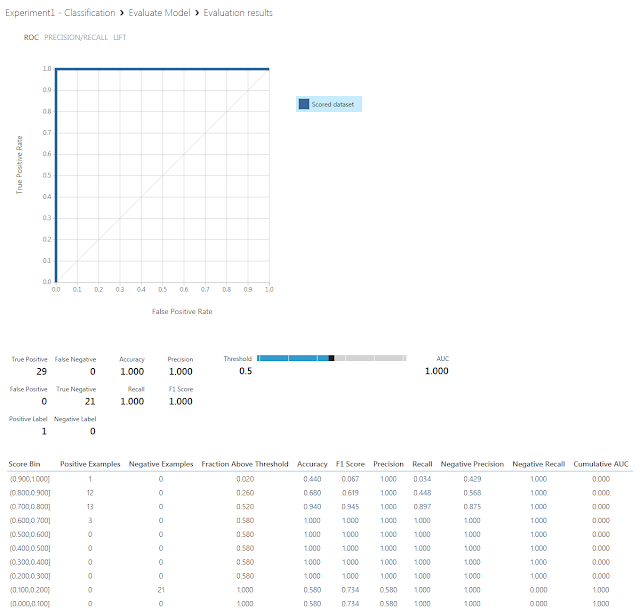
Azure Machine Learningでは、「Score Model」モジュールの後ろに「Evaluate Model」モジュールを接続して「Visualize」メニューをクリックすることでROC曲線を確認することができます。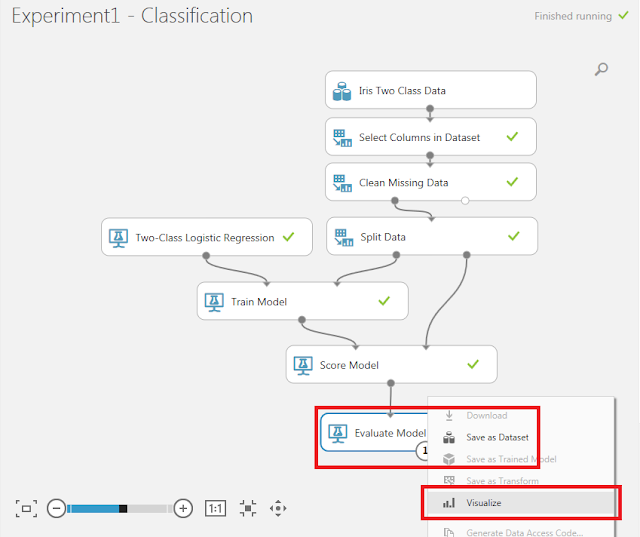
2.ローカル環境での加工・分析
2.1.CSVファイルとしてダウンロード
ここまで紹介した手順では、データの準備から学習、評価までをすべてAzure Machine Learning上で完結させるようになっています。しかし、Azure Machine Learning上に用意されたモジュールや図表では制約が多く、思い通りの加工ができないと感じた方が多いと思います。この章では、Azure Machine Learning上で予測・分類した結果をローカルPCへダウンロードし、皆さんが使い慣れているであろうExcelを使用して加工・集計し、分析を行う手順を紹介します。
Azure Machine LearningからローカルPCへファイルとして保存する際は、ExcelでインポートできるCSVファイルとして保存することにします。TSV(タブ区切り)形式を使用したい場合は、「Convert to CSV」モジュールの代わりに「Convert to TSV」モジュールを利用すると、同様の手順で保存することができます。
前回作成したクラス分類の実験に、「Data Format Conversions」→「Convert to CSV」モジュールを追加し、「Score Model」モジュールから接続します。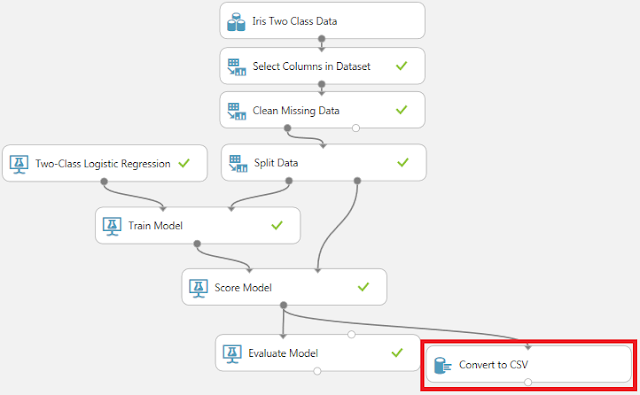
画面下部の「Run」ボタンをクリックした後、「Convert to CSV」モジュールの下部の丸印をクリックして表示されるメニューの「Download」をクリックします。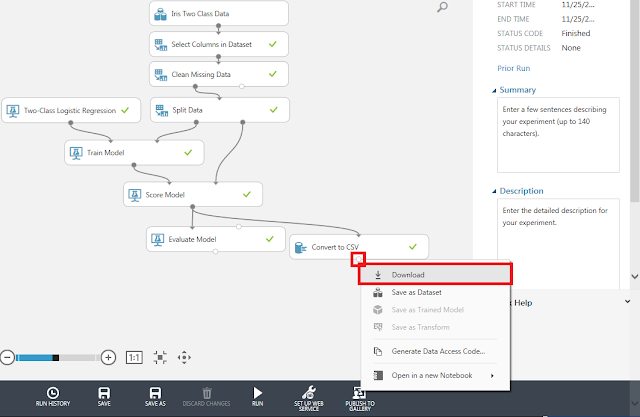
CSVファイルのダウンロードが開始されるので、任意の場所に保存します。
既定値のまま保存すると判別しづらいファイル名で保存されるため、必要に応じてファイル名を変更してください。
ダウンロードしたCSVファイルをExcelで開きます。
Azure Machine Learningの「Score Model」モジュールでVisualizeしたときと同様の表になっていることが分かります。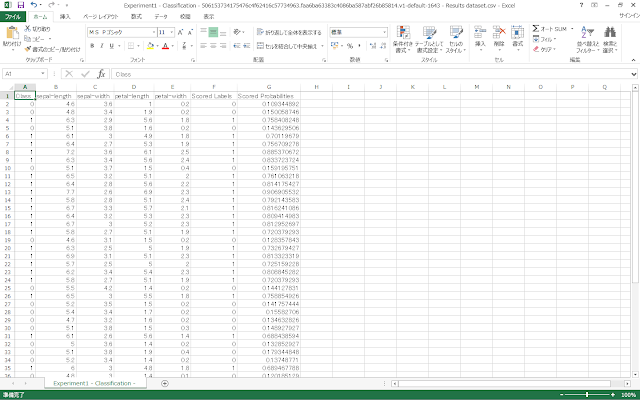
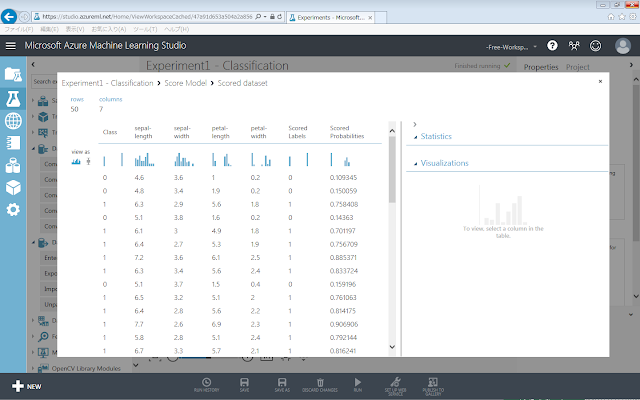
2.2.Excelを用いた集計
7.1項までに、機械学習を行い、CSVファイルとしてダウンロードする手順までを見てきました。この項では、Azure Machine Learningの中で行っていたのと同様にExcelで分類結果を評価するための集計を行う手順を紹介します。
以下の手順ではExcelの関数やグラフを使用するので、Excel ブック形式(拡張子がxlsx)のファイルとして保存しておきます。「Ctrl+S」ショートカットキーを押して、「この形式でブックを保存しますか?」というダイアログボックスが表示されたら「いいえ」ボタンをクリックし、Excel ブック形式で保存します。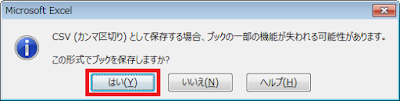
ファイル名の末尾に拡張子「xlsx」があることと、ファイルの種類として「Excelブック (*.xlsx)」が選択されていることを確認し、保存ボタンをクリックします。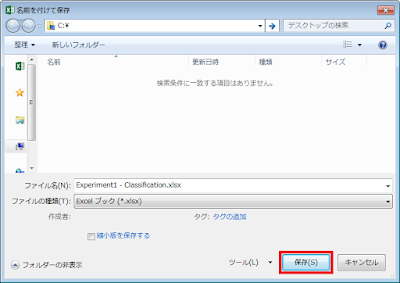
次の項では、データや結果を分かりやすく表現するためにグラフを描いてみます。Excelで作ることができるグラフには様々な種類がありますが、はじめはデータセットの傾向を大まかにつかむためのグラフを、後になるにつれてより絞り込んだテーマのグラフを作っていこうと思います。
2.2.1.散布図の作成
まず、散布図を作ります。
今回のExcelシートには「sepal-length」、「sepal-width」、「petal-length」、「petal-width」の4つの特徴量が含まれていますが、散布図は2次元で基本的には2つの特徴量までしか表現できないため 軸に「sepal-length」を、 軸に「sepal-width」をとることにします。どうしても3つ以上の特徴量を表現したい場合は、マーカーの種類を変えたり、マーカーの色を変えたりといった方法が考えられます。
① まず、データを「Scored Labels」列でソートします。この手順は必ず行わなければいけないというものではありませんが、個別のデータの順番がグラフと無関係であること、系列ごとに範囲選択を行うときの手軽さを考慮して、行うことにしました。
A1セルからG51セルの範囲を選択し、リボンの「ホーム」タブにある「並べ替えとフィルター」→「ユーザー設定の並べ替え」ボタンをクリックします。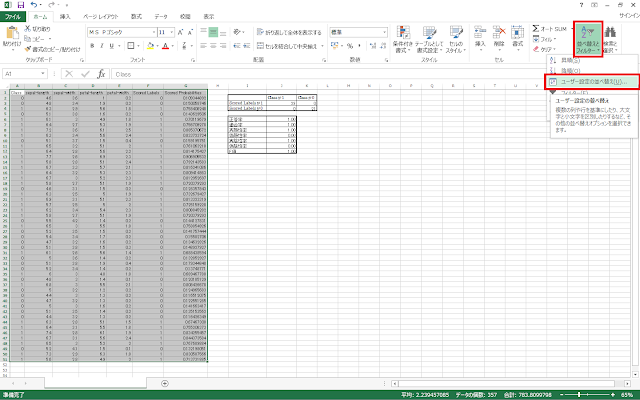
② 表示されたダイアログで、「最優先されるキー」に「Scored Labels」を指定します。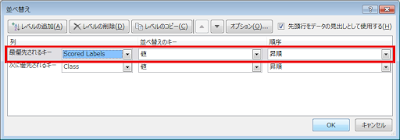
③ ソートされていることを確認します。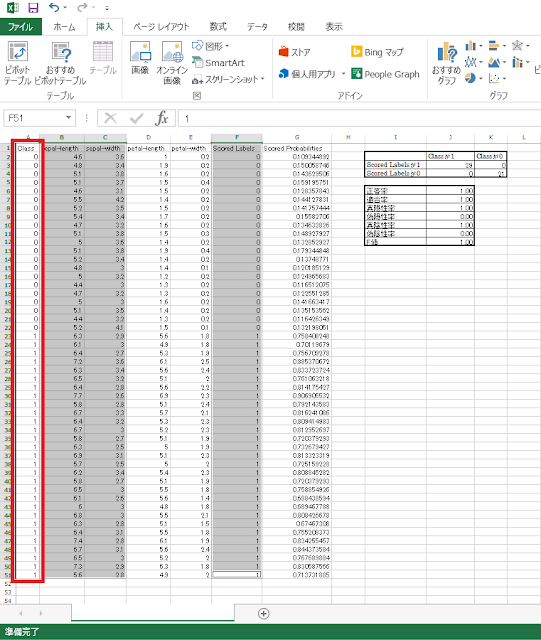
④ シート名に記号や空白が含まれているので、リネームしておきます。ここでは、空白以降を削除して、「Experiment1」とします。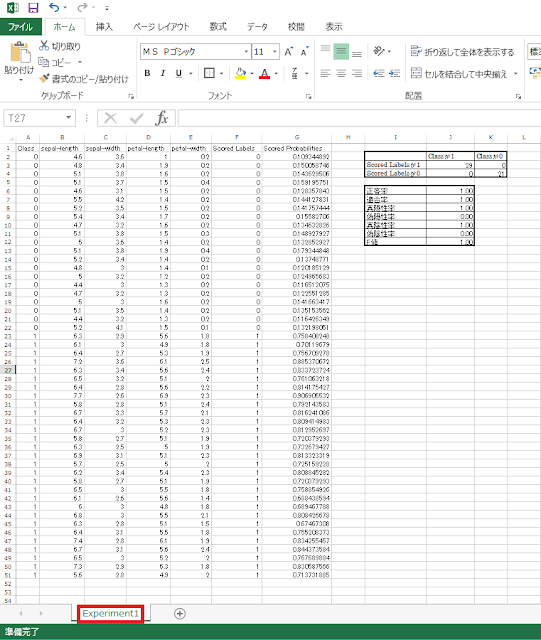
⑤ 余白にあたる空白セルが選択された状態で、リボンの「挿入」タブにある「散布図」ボタンをクリックします。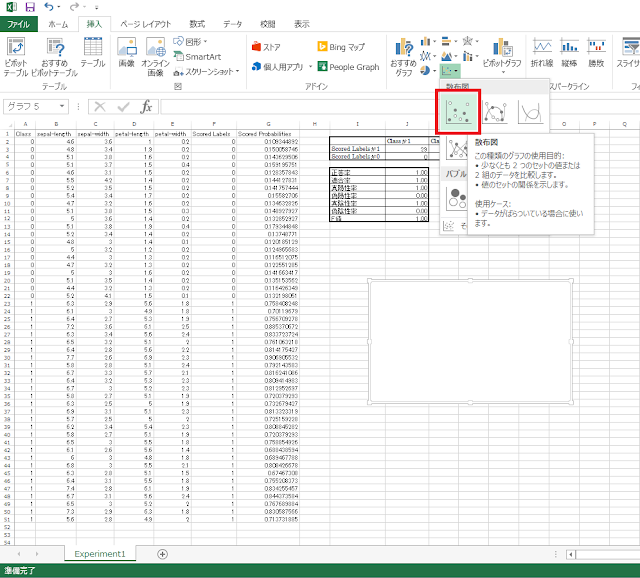
⑥ 挿入されたグラフエリア内で右クリックしてメニューを表示し、「データの選択」をクリックします。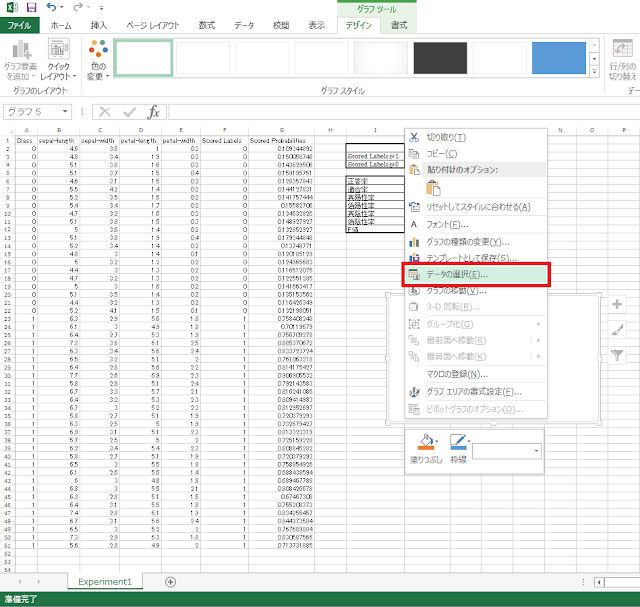
⑦ 表示された「データソースの選択」ダイアログにある、「追加」ボタンをクリックします。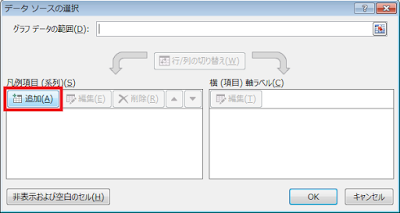
⑧ 表示された「系列の編集」ダイアログの、「系列名」テキストボックスの右隣にあるボタンをクリックしたあと、A2セルを選択し、「系列の編集」ダイアログの右端のボタンをクリックします。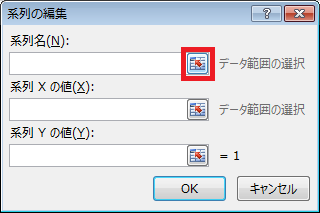
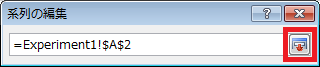
⑨ 「系列の編集」ダイアログの、「系列Xの値」テキストボックスの右隣にあるボタンをクリックした後、B2セルからB22セルの範囲を選択し、「系列の編集」ダイアログの右端のボタンをクリックします。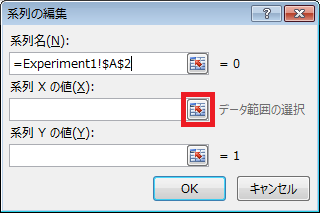
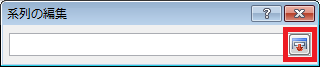
⑩ 「系列の編集」ダイアログの、「系列Yの値」テキストボックスの右隣にあるボタンをクリックした後、C2セルからC22セルの範囲を選択し、「系列の編集」ダイアログの右端のボタンをクリックします。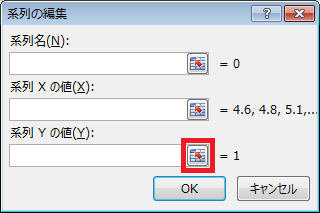
⑪ 「系列の編集」ダイアログの右端に、選択したセルの値が表示されていることを確認し、「OK」ボタンをクリックします。
⑫ 続いて、Classが「1」の系列もClassが「0」の系列と同様に追加します。「データソースの選択」ダイアログの「追加」ボタンをクリックします。
⑬ 表示された「系列の編集」ダイアログの、「系列名」テキストボックスの右隣にあるボタンをクリックした後、A23セルを選択し、「系列の編集」ダイアログの右端のボタンをクリックします。
⑭ 「系列の編集」ダイアログの、「系列Xの値」テキストボックスの右隣にあるボタンをクリックした後、B23セルからB51セルの範囲を選択し、「系列の編集」ダイアログの右端のボタンをクリックします。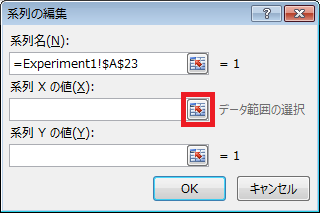
⑮ 「系列の編集」ダイアログの、「系列Yの値」テキストボックスの右隣にあるボタンをクリックした後、C23セルからC51セルの範囲を選択し、「系列の編集」ダイアログの右端のボタンをクリックします。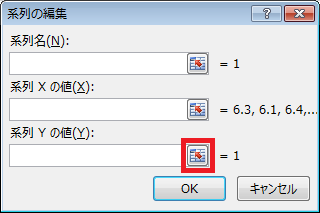
⑯ 「系列の編集」ダイアログの右端に、選択したセルの値が表示されていることを確認し、「OK」ボタンをクリックします。
⑰ 系列が2つ追加されていることを確認したら「OK」ボタンをクリックします。
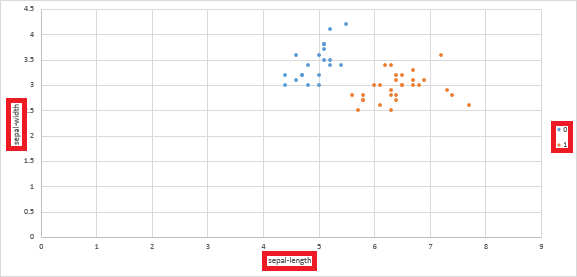
⑱ 散布図が表示されていることを確認します。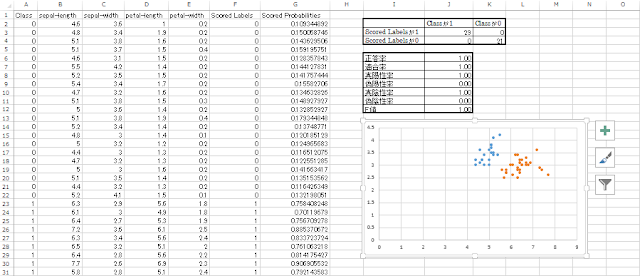
⑲ 必要に応じて、軸ラベルを追加したり、凡例を追加したりすることもできます。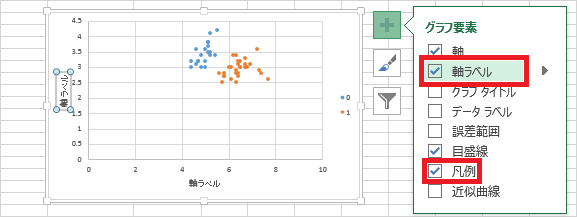
2.2.2.ヒートマップの作成
次にヒートマップを作ります。ヒートマップとは、表形式データの値の大小をグラデーションで表現したものです。
アヤメのデータだとヒートマップを作成するには不向きなので、今回は都道府県別、年別の気温を一覧にした表をもとに、ヒートマップを作成してみます。例に示す気温データでなくても、表形式の量的データであれば同様の手順でヒートマップを作成することができます。
元になるデータを表にしたものが以下の図です。横軸に1から47までの都道府県コードを、縦軸に2004年から2015年までの西暦年をとっています。表の各セルは、その都道府県、その年の日最高気温の平均を示します。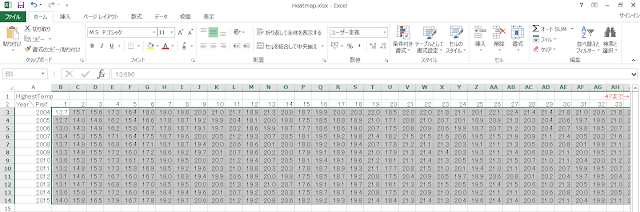
① まず、気温データを選択し、リボンの「ホーム」タブにある「条件付き書式」をクリックします。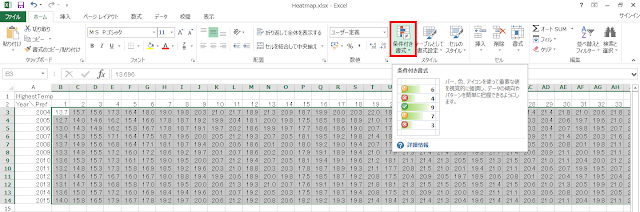
② 「カラースケール」→「赤、黄、緑のカラースケール」をクリックします。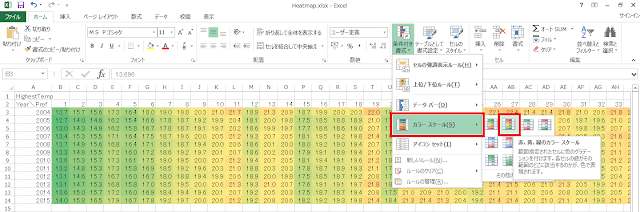
③ 以下のように、色分けされていることを確認します。都道府県コードは北にある都道府県から南にある都道府県へと順に振られているので、都道府県コードが大きくなるほど赤に近い色のセル(気温が高いことを示す)が増えていく様子を確認することができます。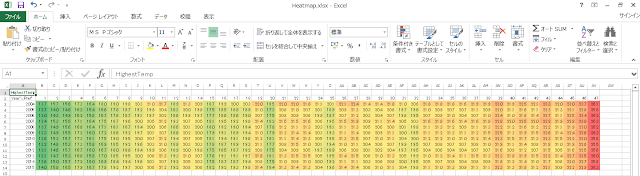
ヒートマップを使用することで、列ごとの比較だけでなく、行ごとの比較もしやすくなります。例えば、2004年と2007年、2010年のデータは似ている(ように見える)というような判断を、統計値を求める前に行うことができます。そのため、どのような分析を行うべきか方針を定める取っ掛かりの部分でヒートマップは非常に役に立つのです。
2.2.3.ヒストグラムの作成
続いて、ヒストグラムを作ってみます。ヒストグラムは、データの分布を表すグラフです。
Excelを使ってヒストグラムを作る方法は2通りあり、1つ目は分析ツールを使用する方法、2つ目は度数分布表を求めた後棒グラフを描く方法です。
ここでは、前者でヒストグラムを作ります。アドインを有効化する手間が必要であるものの、ヒストグラムの作成自体は容易に行える長所があります。
準備としてExcelアドインである「分析ツール」を有効化する手順は以下の通りです。
① Excelを起動し、ファイルを新規作成するか任意のファイルを開きます。左上にある「ファイル」メニューをクリックした後、「オプション」をクリックします。
② 開いた「Excelのオプション」ウィンドウで、左側にある「アドイン」をクリックします。このとき、右側に表示される表の「アクティブなアプリケーションアドイン」に「分析ツール」が含まれている場合は、この後の手順を行う必要がありません。表の「アクティブでないアプリケーションアドイン」に「分析ツール」が含まれている場合は、ウィンドウ下部の「管理:」の右側にあるセレクトメニューで「Excelアドイン」が選択されていることを確認した上で、さらに右側にある「設定」ボタンをクリックします。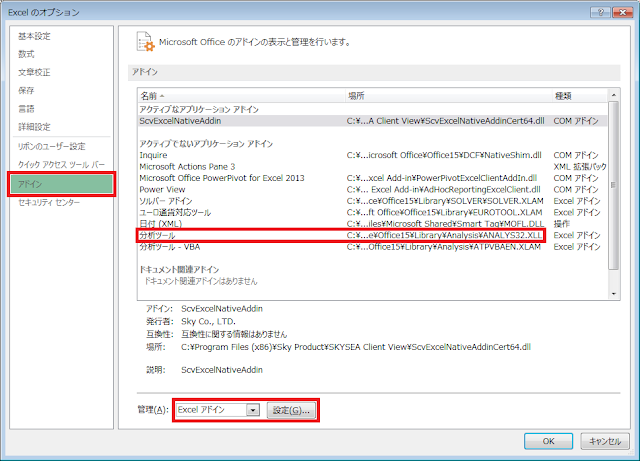
③ 「アドイン」ウィンドウが表示されるので、「分析ツール」の左側にあるチェックボックスをクリックした後、「OK」ボタンをクリックします。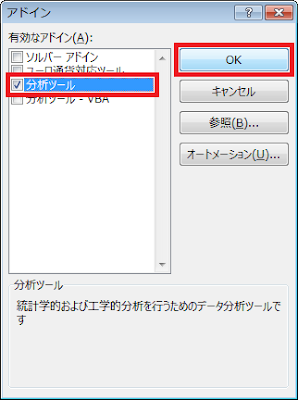
④ リボンにある「データ」タブを開き、「データ分析」ボタンが表示されていることを確認します。
続いて、ヒストグラムを作成する手順を説明します。
① まず、ヒストグラムを作成する対象のデータ(データ列)を決めます。今回は、「Scored Probabilities」をヒストグラムで表すことにします。「Sepal-length」など、他のデータであっても手順は同じです。
② リボンの「データ」タブにある「データ分析」をクリックします。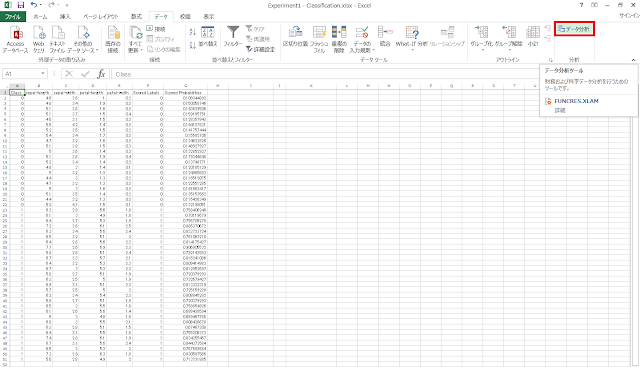
③ 「データ分析」ウィンドウが表示されるので、ヒストグラムを選択した上で「OK」ボタンをクリックします。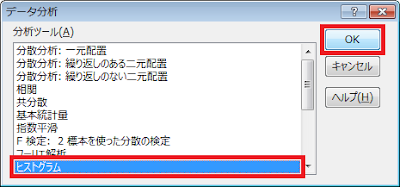
④ 「ヒストグラム」ウィンドウが表示されるので、「入力範囲」の右側にあるボタンをクリックします。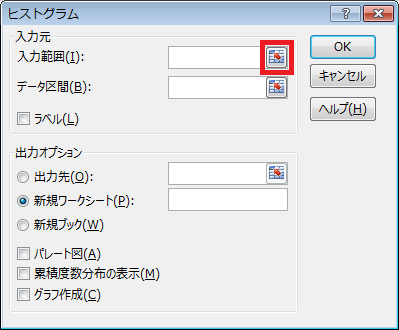
⑤ G2セルからG51セルまでの範囲を選択し、右端にあるボタンをクリックします。
⑥ 「グラフ作成」のチェックマークをクリックした後、「OK」ボタンをクリックします。
⑦ 新規ワークシートが作成され、その中に度数分布表とヒストグラムが作成されます。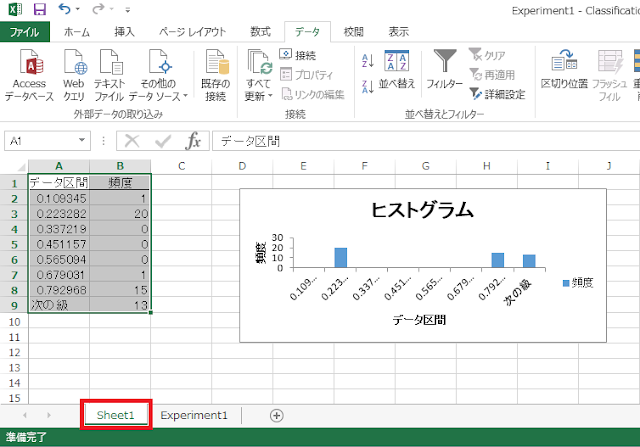
データ分析ツールを使用することで速やかにヒストグラムを作成することができた一方で、この方法では機械的に階級数や階級幅を決めているためデータの特徴に合わないこともあるという問題点があります。先ほどの手順では、「ヒストグラム」ウィンドウで「入力範囲」しか指定しませんでしたが、次に紹介する手順では、「データ区間」も指定することで、よりデータの特徴に合致したグラフを作ることができるようにしたいと思います。
① まず、階級数を決めます。
階級数の決め方に厳密なルールは存在しないため、主張したい内容に合わせて適切な階級数を選ぶ必要があります。
目安の値を求める公式には、以下のようなものがあります。
先ほどの既定値は、上の2式を使用した場合とほぼ同じ値になっていますが、作成されたヒストグラムを見てみると度数が極端に大きいものと極端に小さいものに二極化してしまっているので、もう少し滑らかな変化を示すように階級数を増やします。今回は、階級数を既定値の2倍である にしてみます。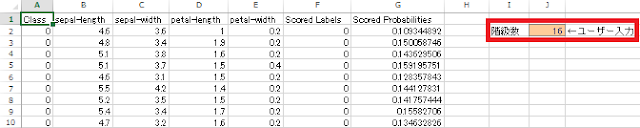
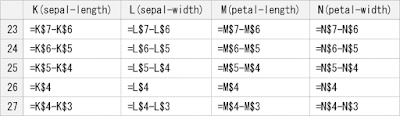
② 以下の数式を使用して、階級数・最大値・最小値をもとに階級幅・階級区間を求めます。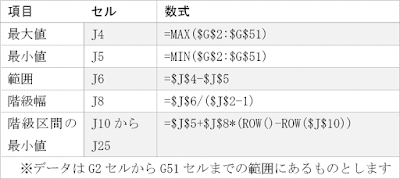
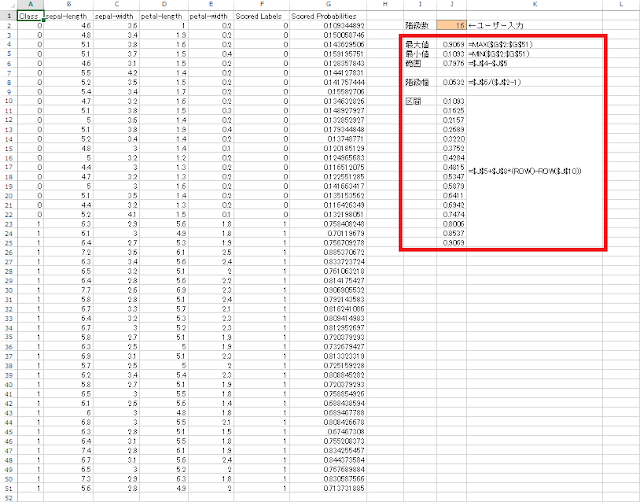
③ 分析ツールを開き、ヒストグラムを選択した上で「OK」ボタンをクリックします。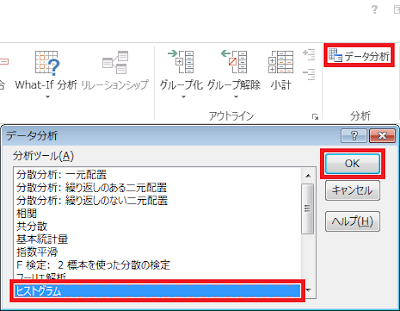
④ 「入力範囲」に「Scored Probabilities」のデータを、「データ区間」に先ほど計算しておいた階級区間の最小値を選択して「OK」ボタンをクリックします。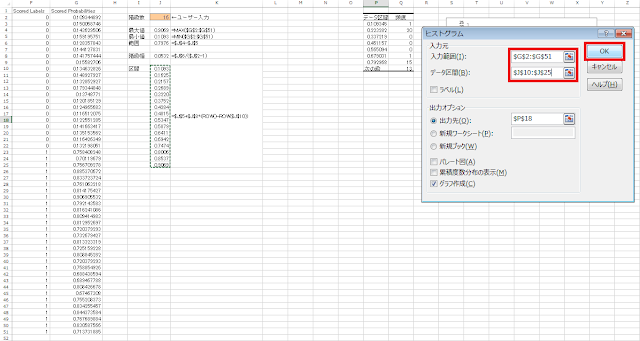
⑤ ヒストグラムが作成されます。しかし、Excelが自動的に「次の級」という区間を追加してしまうので、グラフを選択したときに現れる紫色または青色の枠のサイズを縮めることで「次の級」をグラフの範囲から除去します。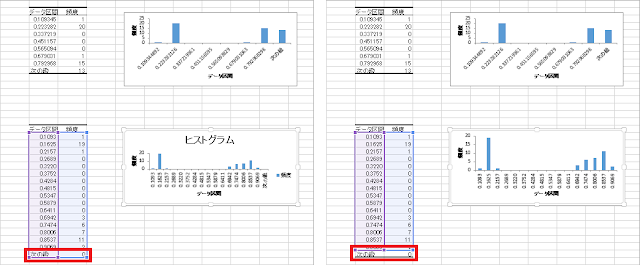
※上半分に表示されているのは既定の階級数で作成したヒストグラムです。
Excel2016を使用している場合には、さらに簡単にヒストグラムを作成できるようになっているようです。
① まず、ヒストグラムを描く対象のデータを選択します。
② リボンの「挿入」タブにある「統計グラフの挿入」をクリックします。
③ ヒストグラムが作成されます。続いて、階級数や軸の書式などを整えます。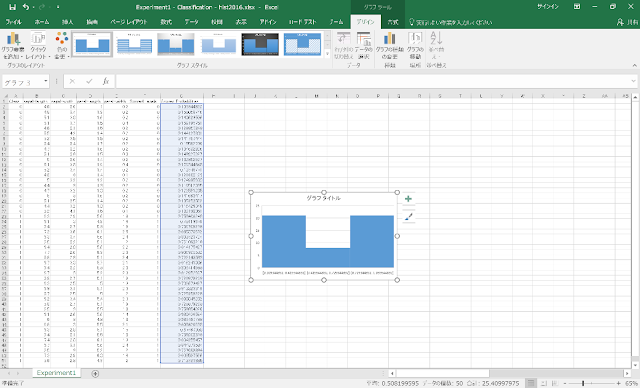
④ グラフを右クリックして、メニューから書式設定(右側パネル)を開きます。パネルの左上の「▼」をクリックして「横 軸」を選択した後、棒グラフのアイコンをクリックして、「軸のオプション」を開きます。
「ビンの数」ラジオボタンをクリックした後、右側のテキストボックスに階級数を入力します。また、「表示形式」の「カテゴリ」を「数値」に変更し、「小数点以下の桁数」を変更します。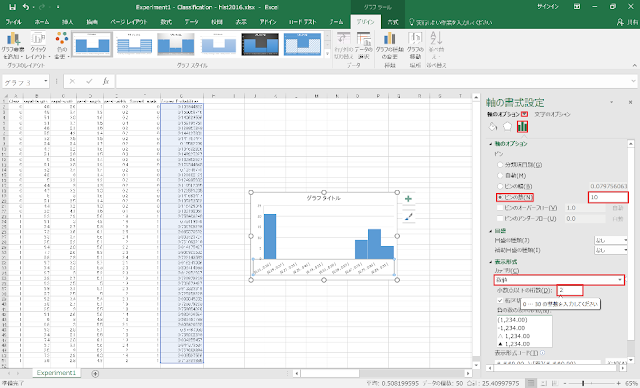
⑤ 階級幅を計算して棒グラフで描く方法よりも容易に階級数を変更することができるので、階級数を細かく変更しながら見やすいグラフを探すことができます。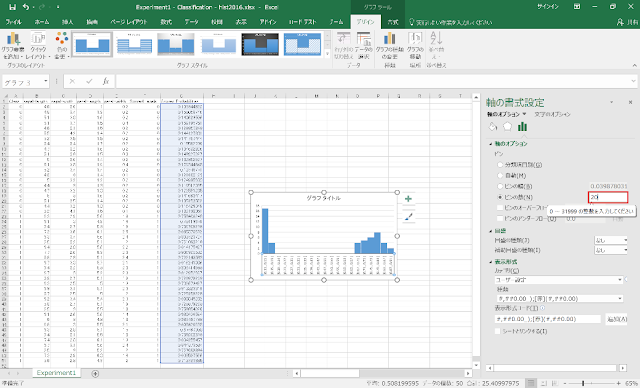
2.2.4.箱ひげ図の作成
ヒストグラムの次は、箱ひげ図を作ります。箱ひげ図もヒストグラムと同様にデータの分布を表すグラフですが、複数のデータのばらつきを同時に確認し、比較することができる特長があります。
① まず、箱ひげ図に含めるデータ列を選択します。今回は、「sepal-length」、「sepal-width」、「petal-length」、「petal-width」の4列を表すことにします。
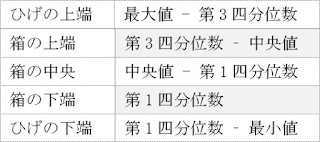
② それぞれのデータ列に対して「最小値」、「第1四分位数」、「中央値」、「第3四分位数」、「最大値」を求めます。Excelでは、いずれもQUARTILE関数を使用して求めることができます。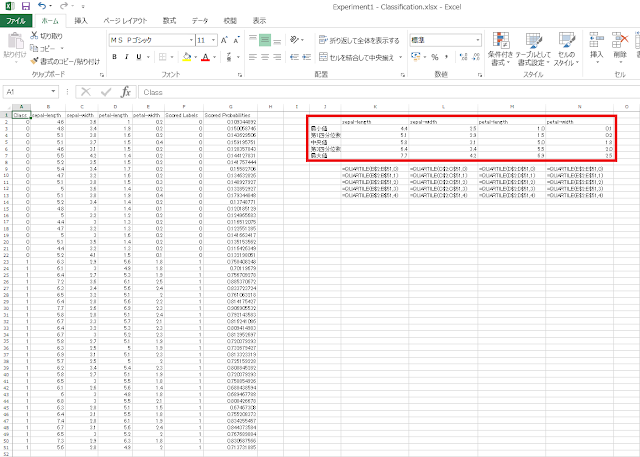
③ Excelで箱ひげ図を書くためには、積み上げ縦棒グラフを応用的に使用しなければならないため、上の表の値そのままでは作成することができません。そこで、グラフにプロットするための値を求めます。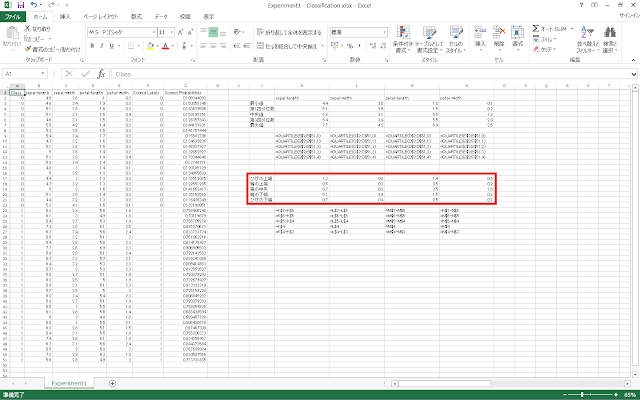
④ まず、箱の部分をプロットします。箱の上端、中央、下端の行を選択して、リボンの「挿入」タブにある「積み上げ縦棒」をクリックします。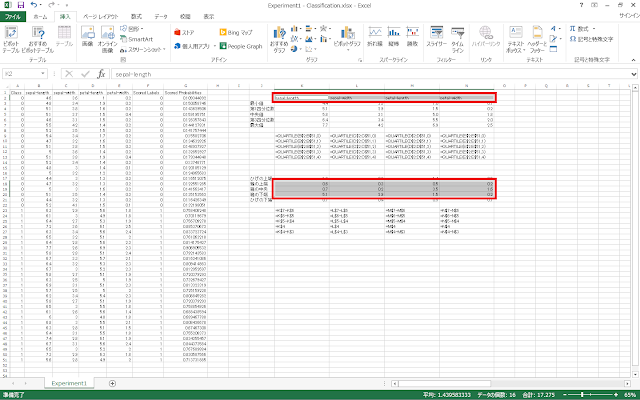
⑤ グラフをクリックすると右外側にアイコンが表示されるので、一番下の「グラフフィルター」をクリックします。続いて、開いたメニューの右下にある「データの選択」をクリックします。
⑥ 系列の順序を入れ替えて、下から「箱の下端」行、「箱の中央」行、「箱の上端」行の系列の順にします。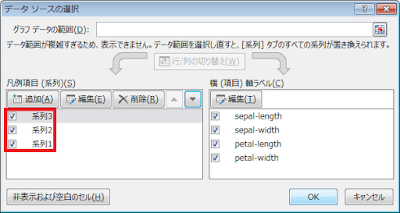
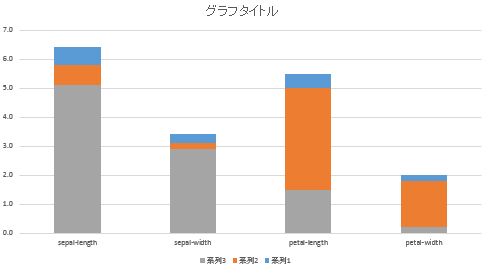
⑦ 棒グラフの書式を変更することで、見た目を箱ひげ図に近づけていきます。まず、「系列3(箱の下端)」の棒グラフ(下の図で言う灰色の部分)が選択された状態で右クリックメニューを開き、「データ系列の書式設定」をクリックします。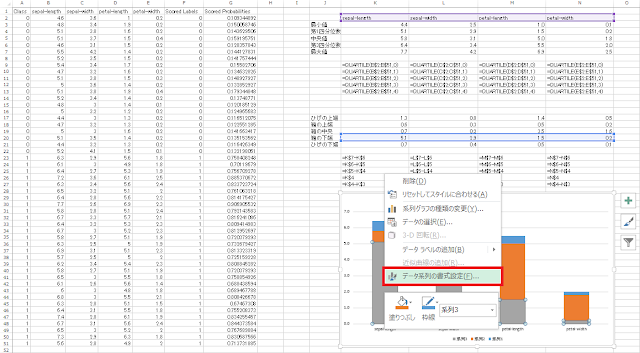
⑧ 「系列3」のグラフを「塗りつぶしなし」に設定します。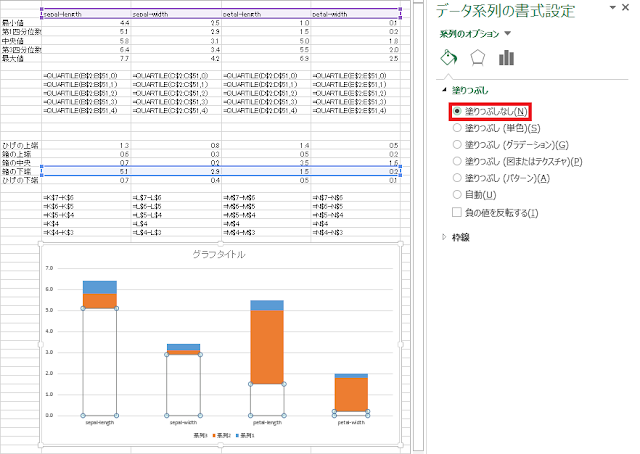
⑨ 続いて、「系列2(箱の中央)」、「系列1(箱の上端)」の塗りつぶしを白色の「塗りつぶし(単色)」に、枠線を黒色の「線(単色)」に設定します。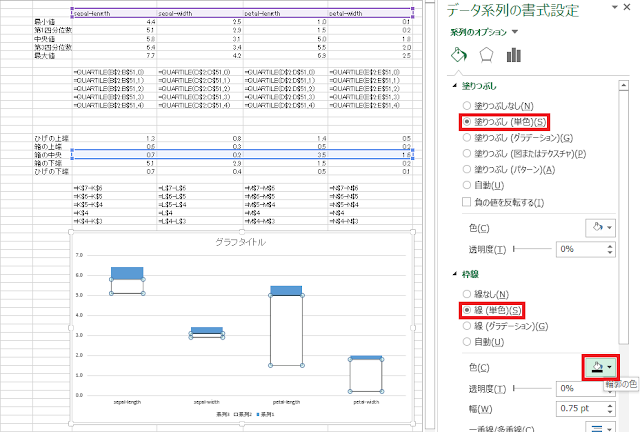
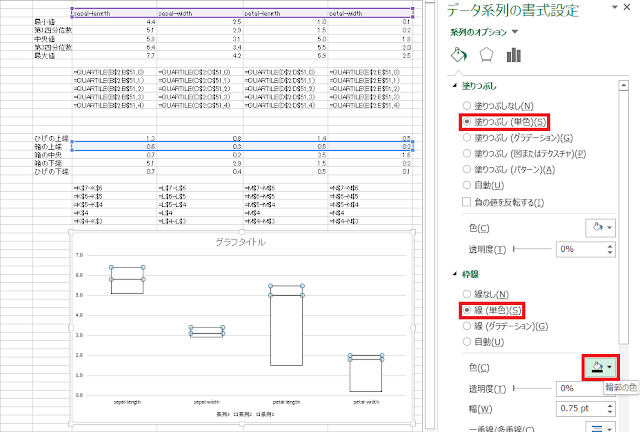
⑩ 次に、ひげを描いていきます。「系列1(箱の上端)」のグラフが選択された状態で、グラフエリアの右外側にある「+」アイコンをクリックし、「誤差範囲」の右側の三角「▶」をクリックし、「その他のオプション」をクリックします。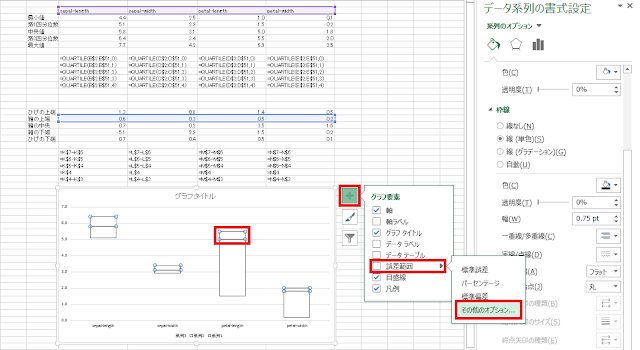
⑪ 「縦軸誤差範囲」の「方向」を、「正方向」に変更した後、「誤差範囲」を「ユーザー設定」に変更して、右側にある「値の指定」ボタンをクリックします。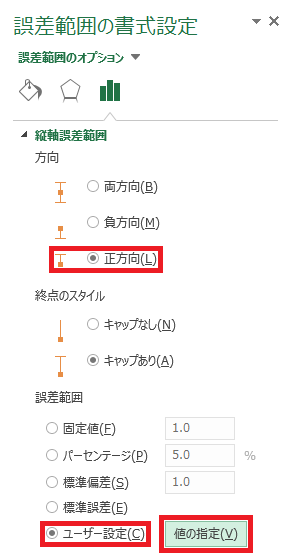
⑫ 「ユーザー設定の誤差範囲」ウィンドウが表示されるので、「正の誤差の値」に、「ひげの上端」行を指定します。「負の誤差の値」は空のままにします。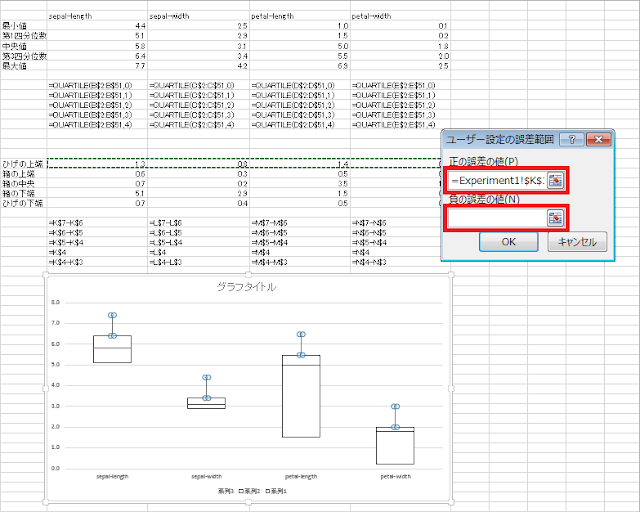
⑬ 続いて、「系列3(箱の下端)」のグラフが選択された状態で、「誤差範囲」の「その他のオプション」を開きます。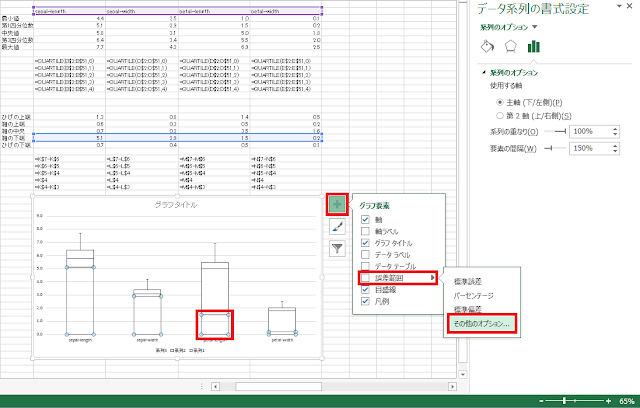
⑭ 「縦軸誤差範囲」の「方向」を「負方向」に変更した後、「誤差範囲」を「ユーザー設定」に変更し、右側にある「値の指定」をクリックします。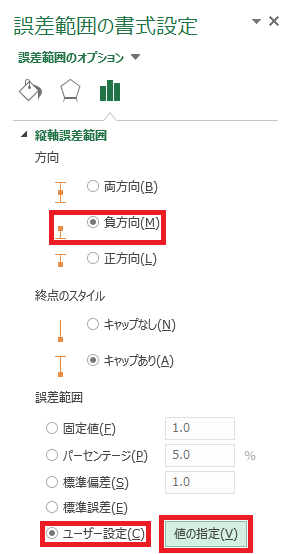
⑮ 「ユーザー設定の誤差範囲」ウィンドウが開くので、「負の誤差の値」に「ひげの下端」行を指定します。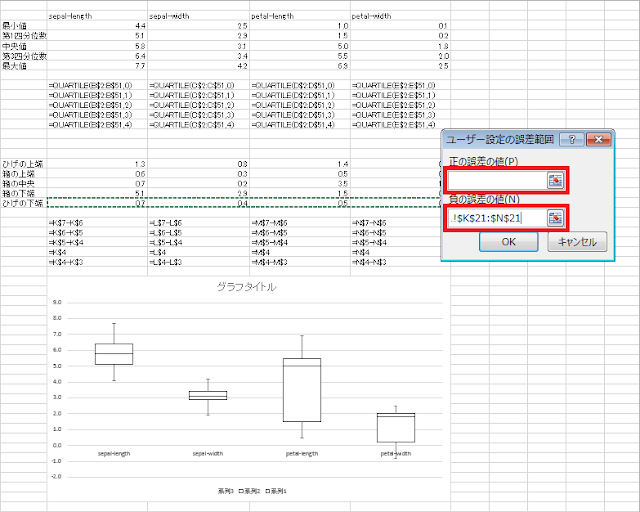
⑯ 必要に応じて、軸の最大値/最小値やグラフタイトルの有無などを修正します。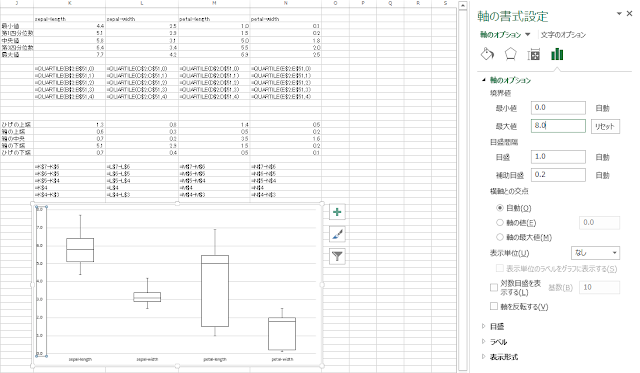
Excel2016を使用している場合には、ヒストグラムと同様に箱ひげ図も「統計グラフの挿入」によって簡単に作成できるようになっているようです。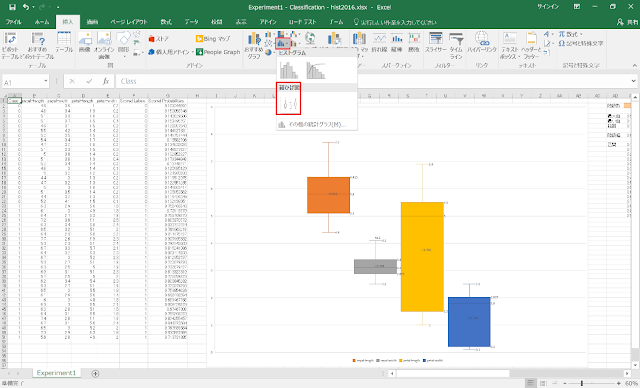
2.2.5.混同行列と評価指標
分類結果の集計の基礎となる、混同行列を作成する手順を紹介します。
Azure Machine Learningで分類した結果がExcelシートのA1セルからG51セルまでの範囲に書かれているものとします。
① 任意の場所に、混同行列を作るための の罫線を引いておきます。今回は、I2セルからK4セルの範囲に混同行列を作ることにします。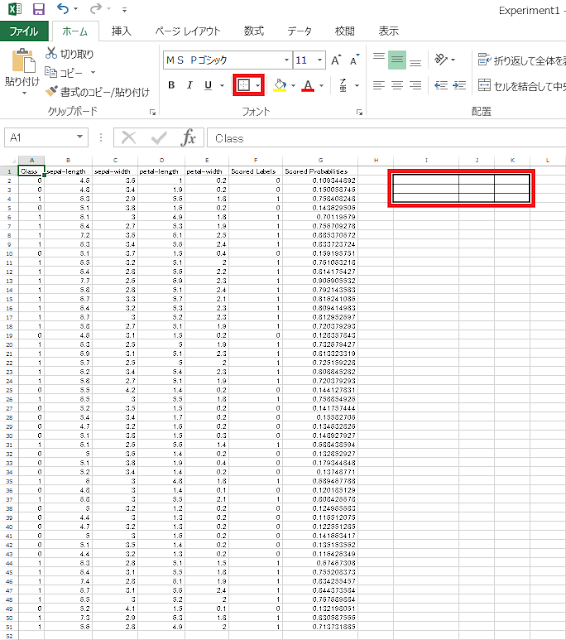
② 罫線を引いた範囲に、以下のように値や数式を入力します。「Class」列のデータはA2セルからA51セルの範囲に、「Scored Labels」列のデータはG2セルからG51セルの範囲に書かれているものとします。
入力すると、以下のような表示になります。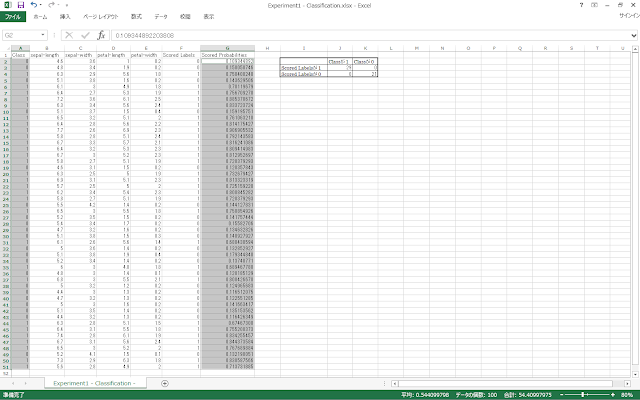
③ 得られた混同行列をもとに、冒頭に示した指標によって評価します。混同行列のときと同様に罫線を引いて、以下の表のように値や数式を入力します。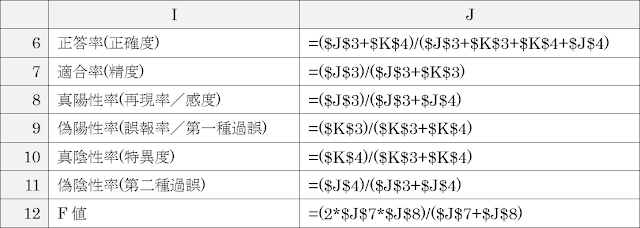
入力すると、以下のような表示結果になります。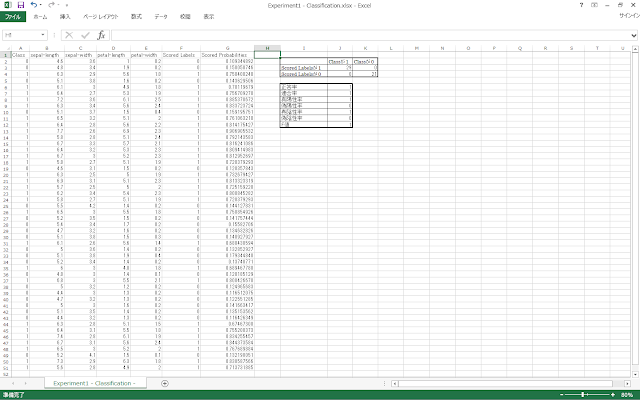
今回は前回学習させたクラス分類の結果を評価し終えました。次回はクラス分類以外の手法で学習させた時に、その評価を行う手順を紹介します。

