記事公開日
最終更新日
第4回 機械学習を試してみる(3/3)
第2章 学習の実行
本章では、実際に学習処理を行います。
2.1.学習ロジックの作成
学習のおおまかな手順を以下に示します。
① 初期化モジュール (Initialize Model)を用意する
② 訓練モジュール(Train)を用意する
③ 初期化モジュールと学習用データを訓練モジュールに入力して、学習済みモデルを作成させる
④ 評価データを学習済みモデルに入力して、未知の評価データに対する予測結果を出力させる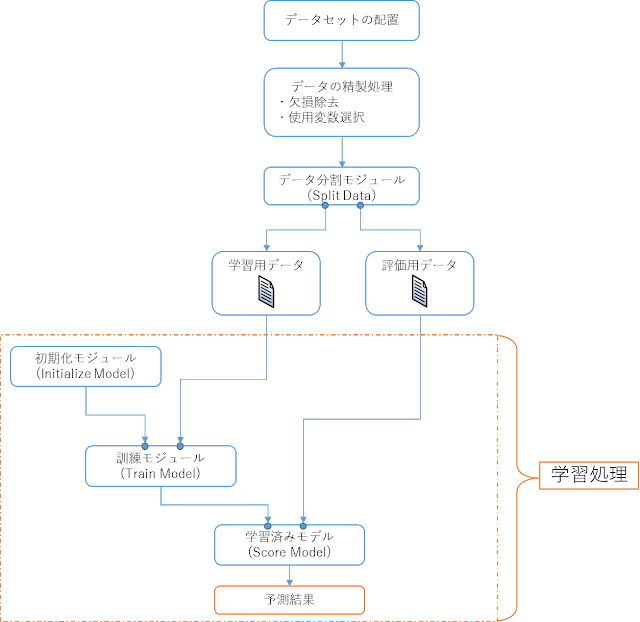
まず、初期化モジュールは、学習に使用するアルゴリズム(手法)を指定するためのものです。次に、訓練モジュールは、初期化モジュールで指定したアルゴリズムによって学習データを学習させた結果を得るために使用するものです。そして、学習済みモデルは、学習させた内容をもとに、新たな入力に対する予測結果を得るために使用するものです。
学習に使用する手法は、求めたい予測結果の特徴に応じて選択します。
|
手法 |
解説 |
結果 |
例 |
|
回帰分析 |
数値の予測を行う際に使用します。 |
連続量 |
製品需要予測 |
|
アノマリ検知 |
多数の正常データと少数の異常データから正常なふるまいを学習し、そこから外れた値を検出する際に使用します。 |
離散値 |
コンピュータ |
|
ウイルス対策 |
|||
|
クラスタリング |
雑多なデータの類似傾向を調べるときに使用します。 |
文字認識 |
|
|
クラス分類 |
分類分けをする際に使用します。 |
医療診断 |
また、それぞれの手法ごとに、使用する学習モデルや計算モジュールが異なります。
|
手法 |
学習モデル |
計算モジュール |
|
回帰分析 |
Train Model |
Score Model |
|
アノマリ検知 |
Train Anomaly Detection Model |
Score Model |
|
クラスタリング |
Train Clustering Model |
Assign Data to Clusters |
|
クラス分類 |
Train Model |
Score Model |
さらに、それぞれの手法の中のどのアルゴリズムで学習させるかは、必要な精度や計算速度に応じて選択します。
今回の例では、データセットに含まれる花びらの長さと幅から、品種名を判別させる学習モデルを作るため、求める結果(=品種名)は離散値になります。また、データセットにもともと含まれている品種名は2種類あり、0と1で示されています。そこで、分析手法としては、2クラスのクラス分類を用いることとします。
まず、初期化モジュールを配置します。今回は、二値の判別分析を行うため、Machine Learning→Initialize Model→Classification→Two-Class Logistic Regressionを、画面中央の灰色の領域に配置します。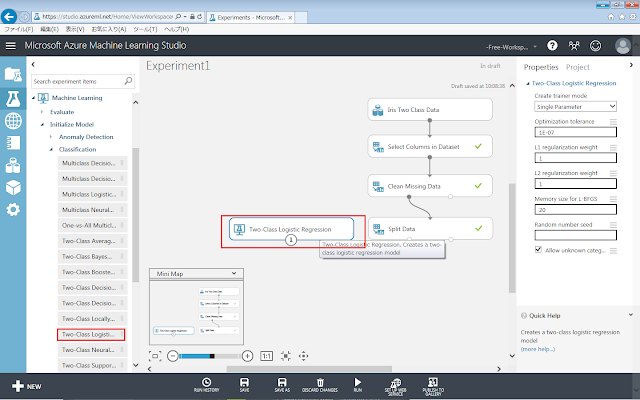
Machine Learning→Train→Train Modelを、画面中央の灰色の領域に配置します。
続いて、初期化モジュール(「Two-Class Logistic Regression」モジュール)および学習データ(「Split Data」モジュールの左下の丸印)から訓練モジュール(Train Model) に向けて、それぞれドラッグアンドドロップします。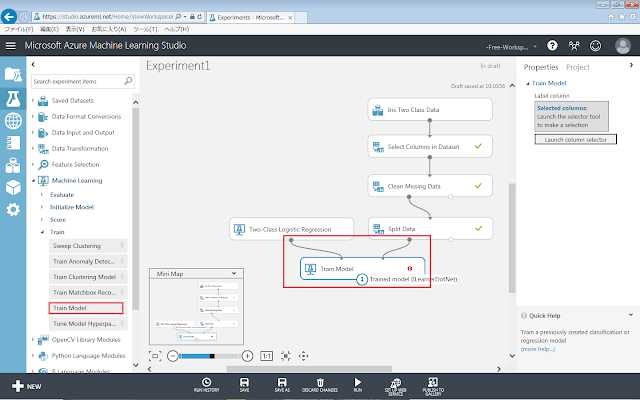
Train Modelに!マークが出ています。
これは値が設定されていないために表示されます。次の手順を行うことで、マークを消すことができます。
Train Modelが選択された状態で、右側にあるLaunch column selectorをクリックします。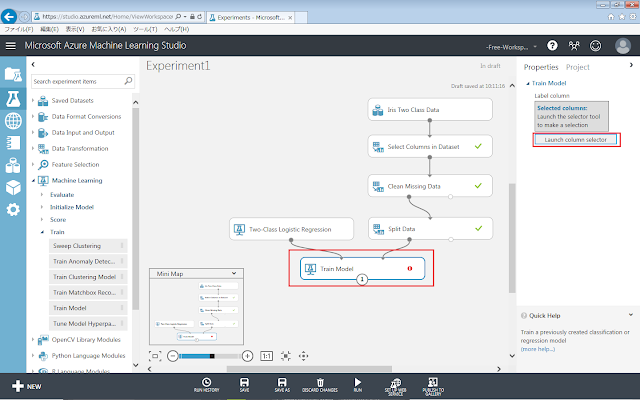
必要なデータ列のタイトル(今回は「Class」)を選択後、「>」ボタンをクリックします。その後、「☑OK」ボタンをクリックします。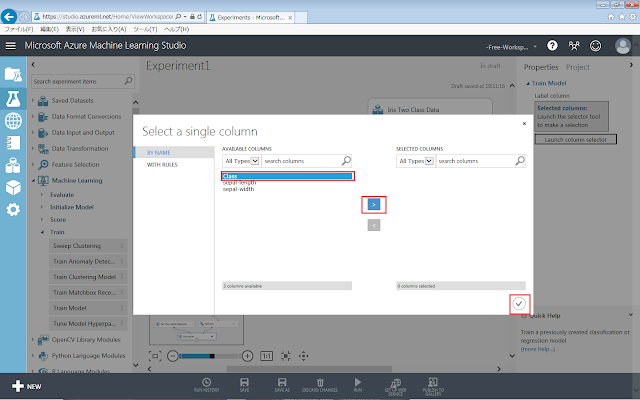
するとTrain Modelの横に合った!マークが消えます。
2.2.クラス分類の実行
作成した学習モデルを使用して未知の評価データをクラス分類させた結果を確認します。
評価データに対して学習結果をもとに分類を行うためには、計算モジュールを使用します。
まず、「Machine Learning」→「Score」からScore Modelモジュールを、画面中央の灰色の領域に配置します。
続いて、訓練モジュール(Train Model)および評価データ(「Split Data」モジュールの右下の丸印)からScore Modelに向けて、それぞれドラッグアンドドロップします。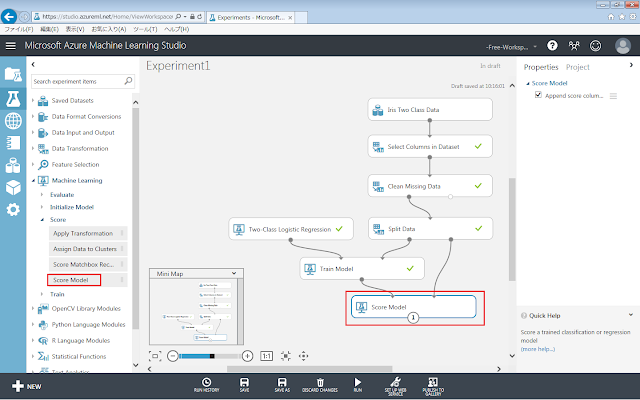
「Run」メニューをクリックします。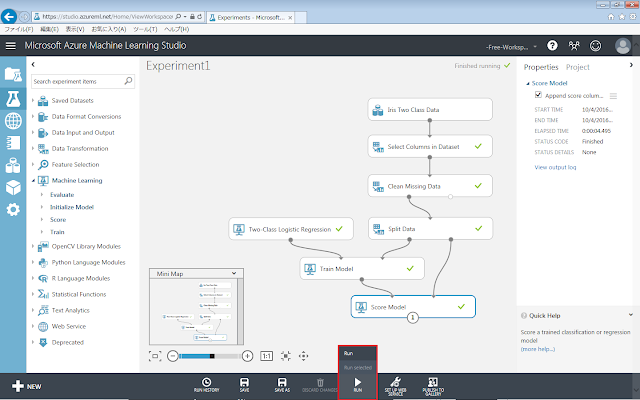
Score Modelの下部の丸印をクリックすると現れるメニューのうち、「Visualize」をクリックして、分類結果を確認します。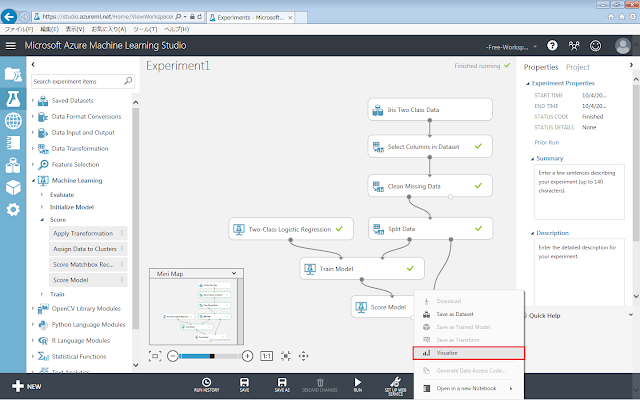
データセットに含まれるデータが表形式で表示されます。
右側のcompare toで、データセットに本来含まれている正答の列名である「Class」を選択すると、分類結果と正答「Class」を比較したグラフを表示させることができます。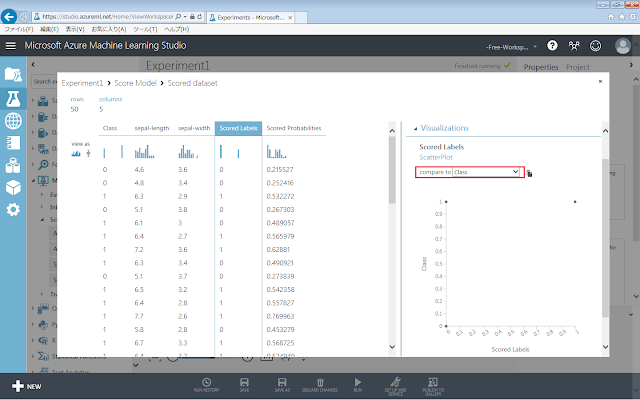
ここで、表示されたグラフに、分類結果と正答が同じ値となる点を結んだ線を重ねてみます。本来は、この緑色の線に乗った2つの点だけ存在していることが理想ですが、実際にはこの線から外れたデータ(橙色で囲んだ点)が出てしまっています。次の手順では、すべての予測のうち、どのくらいの割合のデータが緑色の線から外れてしまったのかを具体的な数値で評価する方法を説明します。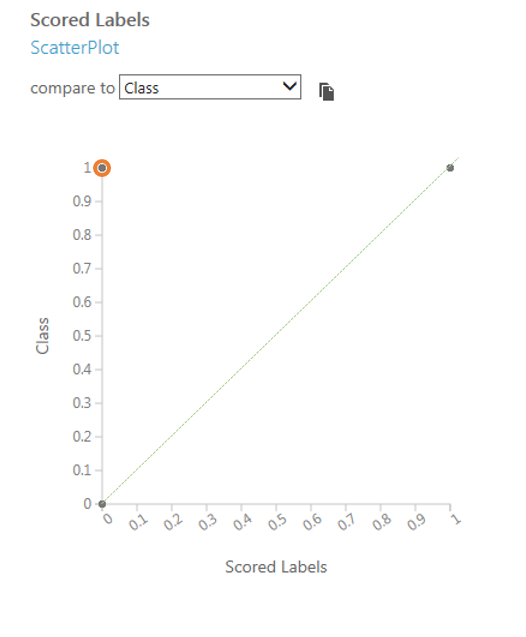
まず、「Statistical Functions」→「Apply Math Operation」モジュールを、画面中央の灰色の領域に配置します。続いて右側のパネルで、以下に示すようにプロパティを設定します。「Value to compare」プロパティおよび「Column set」プロパティについては、「Train Module」モジュールのLabel columnプロパティと同様にcolumn selectorを使用して設定します。
l 「Category」プロパティ
Ø 「Compare」
l 「Value to compare」プロパティ
Ø 「Class」列
l 「Column set」プロパティ
Ø 「Scored Labels」列
この手順によって、分類結果と正答が一致している行と、一致していない行のそれぞれにTrue(正)またはFalse(誤)ラベルを付与します。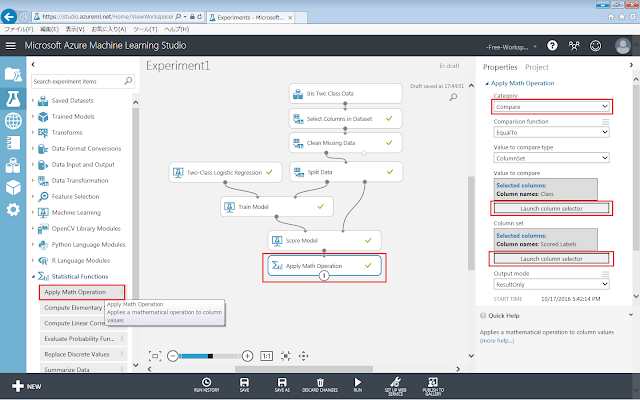
次に、「Apply Math Operation」モジュールで付与したラベルを、次の手順で「Split Data」モジュールに入力するために適した形式に変換します。
「Run」メニューをクリックしてから「Edit Metadata」モジュールを、画面中央の灰色の領域に配置します。続いて右側のパネルで、以下に示すようにプロパティを設定します。「Column」プロパティについては、「Apply Math Operation」モジュールのColumn setプロパティと同様にcolumn selectorを使用して設定します。
l 「Column」プロパティ
Ø 「Scored Labels_Class」
l 「Data type」プロパティ
Ø 「String」
l 「Categorical」プロパティ
Ø 「Make categorical」
l 「New column names」プロパティ
Ø 「Equals」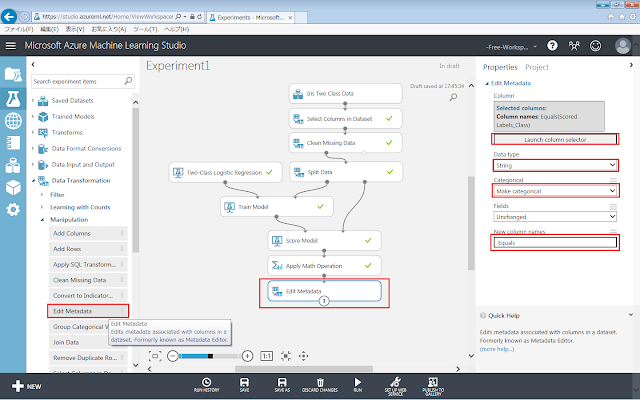
続いて、正答および誤答の数をそれぞれ数えるために、「Split Data」モジュールを使用して「Visualize」します。
「Split Data」モジュールを、画面中央の灰色の領域に配置します。続いて右側のパネルで、以下に示すようにプロパティを設定します。
l 「Splitting mode」プロパティ
Ø 「Regular Expression」
l 「Regular expression」プロパティ
Ø 「\”Equals” True」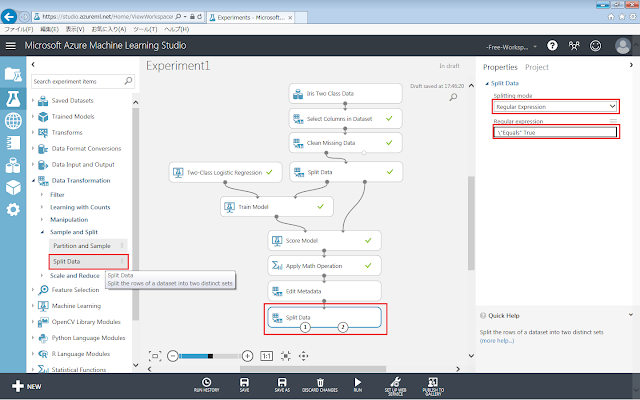
その後、「Run」メニューをクリックして「Split Data」モジュールまで実行が終了したら、「Split Data」モジュール下部の左右にある丸印をクリックすると現れるメニューの「Visualize」をクリックして、分割結果を確認します。「Split Data」モジュール下部の、『左』側の「Visualize」を実行した結果および『右』側の「Visualize」を実行した結果を以下に示します。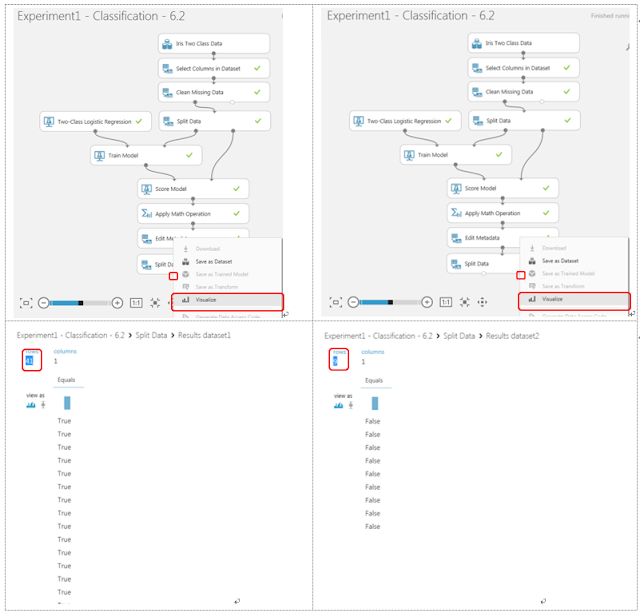
ここで、左側の分割データの行数(rows)が正答と一致した分類件数、右側の分割データの行数(rows)が正答と一致しなかった分類件数を示します。このため、今回の分類では、50件のデータのうち、41件は分類に成功して9件は分類に失敗したため、分類の正答率は、
41/(41+9)=82% となります。
単体の学習ロジックの正答率だけを見ても分類性能が高いのか低いのか判断し難いですが、他の学習ロジックとの比較をする上では、このような定量的な値が役に立ちます。
これで、一通りの機械学習の流れが終わりました。
なんとなく感覚を掴んでいただけたでしょうか?
分析結果の評価については、次回に説明させていただこうと思っております。

