記事公開日
Azure AI Search のスコアについて考えてみる ~ ベクトル&ハイブリッド検索編 ~

前回は、テキスト検索をメインにスコアについて確認しました。
今回は、ベクトル検索とハイブリッド検索(テキスト&ベクトル)を中心に見ていきます。
簡単に言うと、特徴(意味合い)が似ているコンテンツを検索できる仕組みです。
数値的に処理されてしまうので、このコンテンツのどこが似ているのか?というのは、説明しにくいですが・・・
前回のテキスト検索で作成したインデックスには、既にベクトルフィールドも用意していますので、そのまま使用します。SingleCollection で作成されている [vector] 列が該当します。 埋め込みモデルは、Azure OpenAI の [text-embedding-3-large] を使用していますので、3072次元となります。

検索用ドキュメントも、前回用意したものをそのまま使用します。
Azure AI Search のベクトル検索のスコアは、以下の数式で算出されているようです。1.0 に近いほど、ベクトル上では似ているドキュメントということになります。
単純な文章で検索して、類似性の高いとされる 5件をリストアップします。
➡ 「間に合わない」から、時間的要素を含む文章が上位に来ていると思われます。
➡ 「風が治った」から元気、回復的な要素と、「どこかへ行く」から旅?を連想させる文章が上位に来ていると思われます。
➡ 完全一致文章を投入したため、1位の文章は、ほぼ1.0です。システム的な話(ソフトウェア、アプリ)や更新される話が上位に来ています。
➡ 検索例④と言い回しを変えた版です。少し入れ替わりはあるものの近いドキュメントが上位に来ています。意味合いが同じとなる上位2件はかなりの類似性を持つスコアになっています。
この結果を見ても、意味合いが近いドキュメントが検索されていることが分かります。
実際のドキュメント検索においては、このような短文でなく、いろいろな文章の組み合わせとなり複雑化します。単純に検索結果を評価することはできませんが、試してみると確かに似ていると思われるドキュメントが検索できます。
ベクトル的に近いものから順に指定した件数を取得しますので、スコアの高いドキュメントが無ければ、スコアの低いドキュメントが含まれる可能性があります。
<上位5件に絞り込む検索クエリ>
指定する種類は、[vectorSimilarity] と [searchScore] があります。スコアが低いものをカットする使い方であれば、検索結果にそのまま出力される [searchScore] の方が使いやすいかもしれません。
<[searchScore] が、0.6より低いものをカットする検索クエリ>
<「ちょっと」と「間に合わない」を別ベクトルとし、重みづけを含む検索クエリ>
[weight] パラメータは、重みづけの値となります。この場合、[間に合わない] というベクトル検索の [weight] を 0.8としましたので、2割減の効果となります。このような順位になりました。
➡ 「遅れている」の検索結果の重みを下げているため、分割前クエリで 2位だった「電車の遅延により~」が、6位まで下がっています。代わりに「ちょっと」(少し?)に関連しそうな文章が上位に上がってきました。
※ 複数ベクトルで検索した場合、応答スコアは RRFスコア(※ハイブリッド検索の箇所で説明)となるため、スコアの見え方が変わっています。
RRF(Reciprocal Rank Fusion) は、Azure AI Searchの公式サイトでは「以前にランク付けされた複数の結果の検索スコアを評価して、統合された結果セットを生成するアルゴリズム」と説明されています。
具体的にどのような計算をしているか見ていきます。
文字だけでは分かりづらいので、具体的な検索例を見ていきます。
(参考): 10位のドキュメントのスコア計算:1 / (60 + 11位 - 1) + 1 / (60 + 24位 - 1)
テキスト、ベクトル検索方式のスコアを加算したスコアでランク付けされるため、両方の順位が高いものが上位になりやすくなります。ベクトル検索で、一桁順位であっても テキスト検索がランク外の場合、かなり順位が落ちていることが分かります。
7位、8位の文章は、ベクトル検索では関連性が薄いと判断されたものの、テキスト検索の順位が高いので、総合順位が上がってきています。見た感じ、検索文との関連性が高いとは思えません。ハイブリッド検索では、テキスト検索の順位も重要となってきます。
テキスト検索編で示した通り、アナライザーによるトークン分割されたワードで検索されるため、検索クエリを文章でそのまま投入すると、「です」などテキスト検索では意味の無いワードでもスコアがついてしまうことがあるため、クエリ自体の見直しも必要となることもあります。
逆の可能性もあります。テキストの順位が高いもののベクトルの検索数(kパラメータ)を絞り過ぎると、テキスト検索だけの順位で評価され、ハイブリッド順位が落ちてしまうことがあります。ハイブリッド検索においては、両方の検索バランスが重要になってきます。
■検索結果
セマンティックランカーは、Microsoft の経験のもと? 内容を意識して順位を入れ替えてくれます。順位の入替対象となるのは、今回の場合、ハイブリッド検索の結果となります。セマンティックランカーの対象とするには、事前の検索で抽出されることが必要となります。
セマンティックランカーを実行したところ、先ほどのハイブリッド検索順位 7位、8位は押し出されました。かなり下位の順位だったものもトップ10入りしています。
イメージ的には、ハイブリッド検索が予選で、セマンティックランカーは、予選の結果を考慮しない決勝のようなものです。
サンプルデータや検索クエリが悪かったせいで、上記の応答スコアはかなり悪いです。テキスト検索編でも紹介した通り、セマンティックランク付けのスコアは以下のように意味付けされています。
➡ 2.0以下など、低すぎるスコアのものは、検索結果から除外することも考えた方が良いかもしれません。
スコアの付き方を理解すると、どのようにインデックスを構成するか、クエリをどうするかなどチューニング要素が見えてきます。デフォルトの設定で問題無く運用できるケースも多いと思いますが、もう少し精度を上げたいなどがあれば、スコアや順位の状態を確認してみることも良いかと思います。
今回は、ベクトル検索とハイブリッド検索(テキスト&ベクトル)を中心に見ていきます。

ベクトル検索とは
ベクトル化(コンテンツの数値表現)したインデックスを作成し、検索しようとしている情報もベクトル化した上で、類似ベクトルを持つコンテンツを検索する仕組みです。簡単に言うと、特徴(意味合い)が似ているコンテンツを検索できる仕組みです。
数値的に処理されてしまうので、このコンテンツのどこが似ているのか?というのは、説明しにくいですが・・・
ベクトル検索用のフィールドを作成する
Azure AI Search でベクトル検索するには、ベクトル検索用のフィールドを用意する必要があります。前回のテキスト検索で作成したインデックスには、既にベクトルフィールドも用意していますので、そのまま使用します。SingleCollection で作成されている [vector] 列が該当します。 埋め込みモデルは、Azure OpenAI の [text-embedding-3-large] を使用していますので、3072次元となります。
検索用ドキュメントも、前回用意したものをそのまま使用します。
| ・明日の天気は晴れるでしょう。 ・明日は晴天が予想されます。 ・このレストランの料理はとても美味しいです。 ・こちらのお店の食事は、大変風味豊かですね。 ・会議の開始時間は午前10時です。 ・ミーティングは10時にスタートします。 ・新しいプロジェクトがまもなく始動します。 ・近日中に新規案件が立ち上がる予定です。 ・彼の提案は非常に興味深いものでした。 ・彼のアイデアには大変惹かれるものがありました。 ・システムのアップデートが必要です。 ・そのシステムは更新しなければなりません。 ・電車の遅延により到着が遅れます。 ・列車が遅れているため、着くのが少し後になります。 ・この本は多くの読者に感動を与えました。 ・この書籍は多くの人々の心を打ちました。 ・至急、資料をご確認ください。 ・速やかに書類に目を通していただけますか。 ・彼女は優れたコミュニケーション能力を持っています。 ・彼女は人との意思疎通が非常に上手です。 ・来週、新しいソフトウェアがリリースされます。 ・新しいアプリが来週公開される見込みです。 ・この製品の品質は保証されています。 ・この商品のクオリティについては請け合います。 ・昨夜、珍しい夢を見ました。 ・昨晩は不思議な夢を体験しました。 |
・イベントへの参加申し込みは本日までです。 ・行事の登録締め切りは今日です。 ・彼は正直で信頼できる人物です。 ・彼は嘘をつかない、頼りになる人柄です。 ・この問題の解決策を見つけ出す必要があります。 ・この課題に対する答えを導き出さねばなりません。 ・旅行の準備はもう済みましたか。 ・旅支度はもう完了しましたでしょうか。 ・彼の功績は称賛に値します。 ・彼が成し遂げたことは褒められるべきです。 ・景気が少しずつ回復している兆しが見られます。 ・経済状況が徐々に上向いている気配があります。 ・その映画の結末は衝撃的でした。 ・あのフィルムのラストシーンには驚かされました。 ・子供たちは公園で元気に遊んでいます。 ・子どもたちが広場で活発に動き回っています。 ・詳細については、添付ファイルをご覧ください。 ・詳しくは、お送りしたデータをご参照ください。 ・チームの協力なしには成功できませんでした。 ・部門の連携がなければ、この達成は不可能だったでしょう。 ・健康のため、毎日運動を心がけています。 ・健やかな体を維持するため、日々のエクササイズを意識しています。 ・今年の夏は特に暑い日が続いています。 ・例年に比べて、今夏は猛暑が連続しています。 |
ベクトル検索の実行
検索を試す前に、ベクトル検索のスコアについて触れておきます。Azure AI Search のベクトル検索のスコアは、以下の数式で算出されているようです。1.0 に近いほど、ベクトル上では似ているドキュメントということになります。
| 計算式 | @search.score = 1 / (1 + (1 - コサイン類似性)) ※コサイン類似性:ベクトルが指す方向が、どれだけ似ているかを表す指標 |
|---|---|
| 範囲 | 0.333 - 1.000 |
単純な文章で検索して、類似性の高いとされる 5件をリストアップします。
検索例①
ちょっと間に合わない
| 順位 | 文章 | スコア |
|---|---|---|
| 1 | 列車が遅れているため、着くのが少し後になります。 | 0.6648254 |
| 2 | 電車の遅延により到着が遅れます。 | 0.64485043 |
| 3 | 行事の登録締め切りは今日です。 | 0.6037203 |
| 4 | 至急、資料をご確認ください。 | 0.59399164 |
| 5 | イベントへの参加申し込みは本日までです。 | 0.5909212 |
検索例②
風邪が治ったので、どこかに遊びにいこうかな
| 順位 | 文章 | スコア |
|---|---|---|
| 1 | 子供たちは公園で元気に遊んでいます。 | 0.6203234 |
| 2 | 旅行の準備はもう済みましたか。 | 0.59589297 |
| 3 | 景気が少しずつ回復している兆しが見られます。 | 0.5880338 |
| 4 | 明日は晴天が予想されます。 | 0.5863127 |
| 5 | 経済状況が徐々に上向いている気配があります。 | 0.5842481 |
検索例③
システムのアップデートが必要です。
| 順位 | 文章 | スコア |
|---|---|---|
| 1 | システムのアップデートが必要です。 | 0.9999999 |
| 2 | そのシステムは更新しなければなりません。 | 0.84071624 |
| 3 | この問題の解決策を見つけ出す必要があります。 | 0.64573663 |
| 4 | 来週、新しいソフトウェアがリリースされます。 | 0.6263779 |
| 5 | 新しいアプリが来週公開される見込みです。 | 0.61297125 |
検索例④
システムのアップデートをしないとダメです。
| 順位 | 文章 | スコア |
|---|---|---|
| 1 | システムのアップデートが必要です。 | 0.83379865 |
| 2 | そのシステムは更新しなければなりません。 | 0.8087935 |
| 3 | この問題の解決策を見つけ出す必要があります。 | 0.613973 |
| 4 | チームの協力なしには成功できませんでした。 | 0.605596 |
| 5 | 来週、新しいソフトウェアがリリースされます。 | 0.6037541 |
この結果を見ても、意味合いが近いドキュメントが検索されていることが分かります。
実際のドキュメント検索においては、このような短文でなく、いろいろな文章の組み合わせとなり複雑化します。単純に検索結果を評価することはできませんが、試してみると確かに似ていると思われるドキュメントが検索できます。
ベクトル検索のチューニング
検索結果の評価は難しいですが、それでも明らかにおかしい検索結果は改善したいので、チューニングできる要素を見ていきます。取得件数
[k] パラメータを指定することで、取得する件数を制限できます。指定しない場合は、50件となります。ベクトル的に近いものから順に指定した件数を取得しますので、スコアの高いドキュメントが無ければ、スコアの低いドキュメントが含まれる可能性があります。
<上位5件に絞り込む検索クエリ>
{
"count": true,
"vectorQueries": [
{
"kind": "text",
"text": "ちょっと間に合わない",
"fields": "vector",
"k": 5,
}
],
"select": "text_ja_microsoft"
}
しきい値の設定
スコアが低いドキュメントを切り捨てたい場合は、[threshold] パラメータを使用できます。指定する種類は、[vectorSimilarity] と [searchScore] があります。スコアが低いものをカットする使い方であれば、検索結果にそのまま出力される [searchScore] の方が使いやすいかもしれません。
<[searchScore] が、0.6より低いものをカットする検索クエリ>
{
"count": true,
"vectorQueries": [
{
"kind": "text",
"text": "ちょっと間に合わない",
"fields": "vector",
"k": 50,
"threshold": {
"kind": "searchScore",
"value": 0.6
}
}
],
"select": "text_ja_microsoft"
}
複数ベクトルによる検索
ベクトルクエリは、リストになっているため、複数のベクトル値からの検索も可能です。それぞれのベクトル条件に重み付けすることもできるので、特定の要素(ベクトル)の重みを強くすることもできます。<「ちょっと」と「間に合わない」を別ベクトルとし、重みづけを含む検索クエリ>
{
"count": true,
"vectorQueries": [
{
"kind": "text",
"text": "ちょっと",
"fields": "vector",
"k": 5
},
{
"kind": "text",
"text": "間に合わない",
"fields": "vector",
"k": 5,
"weight": 0.8
}
],
"select": "text_ja_microsoft"
}
[weight] パラメータは、重みづけの値となります。この場合、[間に合わない] というベクトル検索の [weight] を 0.8としましたので、2割減の効果となります。このような順位になりました。
| 順位 | 文章 | スコア |
|---|---|---|
| 1 |
列車が遅れているため、着くのが少し後になります。
|
0.02950819581747055
|
| 2 |
景気が少しずつ回復している兆しが見られます。
|
0.01666666753590107
|
| 3 |
至急、資料をご確認ください。
|
0.016129031777381897
|
| 4 |
経済状況が徐々に上向いている気配があります。
|
0.01587301678955555
|
| 5 |
新しいプロジェクトがまもなく始動します。
|
0.015625 |
| 6 |
電車の遅延により到着が遅れます。
|
0.0133333345875144 |
※ 複数ベクトルで検索した場合、応答スコアは RRFスコア(※ハイブリッド検索の箇所で説明)となるため、スコアの見え方が変わっています。
ハイブリッド検索
ベクトル検索の結果のみの場合、検索結果がなんとなく近いものという感じでしたが、テキスト検索を併用したハイブリッド検索とすると、もっともらしいドキュメントが検索される可能性が高くなります。 ハイブリッド検索のスコアは、RRF方式となっています。RRF(Reciprocal Rank Fusion) は、Azure AI Searchの公式サイトでは「以前にランク付けされた複数の結果の検索スコアを評価して、統合された結果セットを生成するアルゴリズム」と説明されています。
具体的にどのような計算をしているか見ていきます。
- 各検索方式(テキスト検索、ベクトル検索)で 順位付け を行います。
- 順位の逆数(1位なら 1/1、2位なら 1/2)をスコアとします。上位の順位間のスコア差を調整するため、Azure AI Searchでは 60 という値を基準に補正されます(1位は1/60、2位は1/61など)。
- 各検索方式で計算された値を 合計 したものが最終的なスコアとなります。
文字だけでは分かりづらいので、具体的な検索例を見ていきます。
{
"count": true,
"search": "彼女は優秀な人物です",
"vectorQueries": [
{
"kind": "text",
"text": "彼女は優秀な人物です",
"fields": "vector"
}
],
"select": "text_ja_microsoft",
"searchFields": "text_ja_microsoft"
}
| 順位 | 文章 | ハイブリッドスコア | テキスト順位 | ベクトル順位 |
|---|---|---|---|---|
| 1 | 彼女は人との意思疎通が非常に上手です。 | 0.033060111 | 1 | 2 |
| 2 | 彼女は優れたコミュニケーション能力を持っています。 | 0.032795697 | 3 | 1 |
| 3 | 彼は正直で信頼できる人物です。 | 0.032002047 | 4 | 3 |
| 4 | 彼は嘘をつかない、頼りになる人柄です。 | 0.030550372 | 8 | 5 |
| 5 | 彼が成し遂げたことは褒められるべきです。 | 0.029469121 | 12 | 6 |
| 6 | このレストランの料理はとても美味しいです。 | 0.028381642 | 13 | 10 |
| 7 | イベントへの参加申し込みは本日までです。 | 0.02681011 | 2 | 37 |
| 8 | 近日中に新規案件が立ち上がる予定です。 | 0.026779423 | 7 | 27 |
| 9 | 健やかな体を維持するため、日々のエクササイズを意識しています。 | 0.026519142 | 14 | 19 |
| 10 | 昨晩は不思議な夢を体験しました。 | 0.026333906 | 11 | 24 |
| 11 | 行事の登録締め切りは今日です。 | 0.025934279 | 5 | 38 |
| 12 | 会議の開始時間は午前10時です。 | 0.025384616 | 6 | 41 |
| 13 | システムのアップデートが必要です。 | 0.02536232 | 10 | 33 |
| 14 | 新しいアプリが来週公開される見込みです。 | 0.0252322 | 9 | 36 |
| 15 | 彼の功績は称賛に値します。 | 0.015873017 | ランク外 | 4 |
| 16 | 彼の提案は非常に興味深いものでした。 | 0.015151516 | ランク外 | 7 |
| 17 | この商品のクオリティについては請け合います。 | 0.014925373 | ランク外 | 8 |
| 18 | 彼のアイデアには大変惹かれるものがありました。 | 0.014705882 | ランク外 | 9 |
| 19 | こちらのお店の食事は、大変風味豊かですね。 | 0.014285714 | ランク外 | 11 |
| 20 | 健康のため、毎日運動を心がけています。 | 0.014084507 | ランク外 | 12 |
テキスト、ベクトル検索方式のスコアを加算したスコアでランク付けされるため、両方の順位が高いものが上位になりやすくなります。ベクトル検索で、一桁順位であっても テキスト検索がランク外の場合、かなり順位が落ちていることが分かります。
7位、8位の文章は、ベクトル検索では関連性が薄いと判断されたものの、テキスト検索の順位が高いので、総合順位が上がってきています。見た感じ、検索文との関連性が高いとは思えません。ハイブリッド検索では、テキスト検索の順位も重要となってきます。
テキスト検索編で示した通り、アナライザーによるトークン分割されたワードで検索されるため、検索クエリを文章でそのまま投入すると、「です」などテキスト検索では意味の無いワードでもスコアがついてしまうことがあるため、クエリ自体の見直しも必要となることもあります。
逆の可能性もあります。テキストの順位が高いもののベクトルの検索数(kパラメータ)を絞り過ぎると、テキスト検索だけの順位で評価され、ハイブリッド順位が落ちてしまうことがあります。ハイブリッド検索においては、両方の検索バランスが重要になってきます。
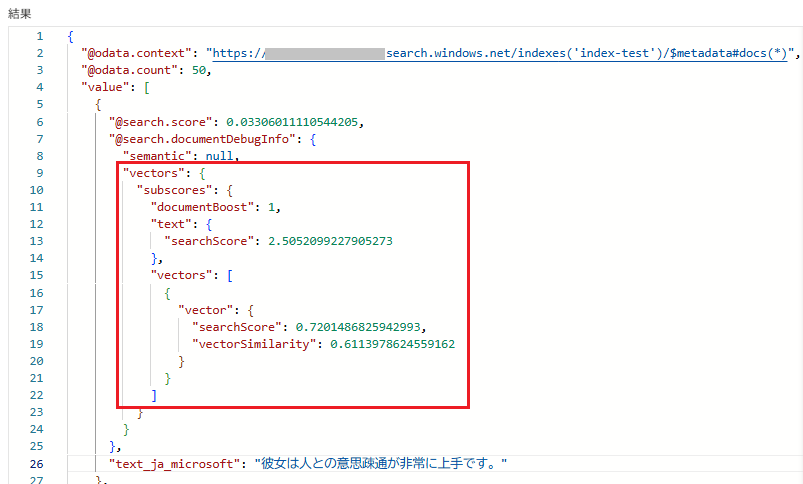
元のスコアを確認する
RRFスコアになってしまうと、もとのテキスト検索スコアやベクトル検索スコアが分からなくなってしまいます。[debug] パラメータで、元のスコアを確認できます。{
"search": "彼女は優秀な人物です",
"count": true,
"vectorQueries": [
{
"kind": "text",
"text": "彼女は優秀な人物です",
"fields": "vector"
}
],
"select": "text_ja_microsoft",
"searchFields": "text_ja_microsoft",
"debug": "vector"
}
■検索結果
セマンティックランク付けを併用する
テキスト検索編でも使用しましたが、セマンティックランク付けを有効にしてみます。ハイブリッド検索だけでは、イマイチな結果を調整してくれます(必ず良くなるとは限りませんが・・・)。{
"search": "彼女は優秀な人物です",
"count": true,
"vectorQueries": [
{
"kind": "text",
"text": "彼女は優秀な人物です",
"fields": "vector"
}
],
"queryType": "semantic",
"semanticConfiguration": "index-test-semantic-configuration",
"queryLanguage": "ja-jp",
"select": "text_ja_microsoft",
"searchFields": "text_ja_microsoft"
}
| 順位 | 文章 | リランカ―スコア | ハイブリッド順位 |
|---|---|---|---|
| 1 | 彼女は優れたコミュニケーション能力を持っています。 | 2.06752634 | 2 |
| 2 | 彼女は人との意思疎通が非常に上手です。 | 1.915104628 | 1 |
| 3 | 彼の功績は称賛に値します。 | 1.86778295 | 15 |
| 4 | 彼のアイデアには大変惹かれるものがありました。 | 1.707917452 | 18 |
| 5 | 彼の提案は非常に興味深いものでした。 | 1.692320824 | 16 |
| 6 | 彼は正直で信頼できる人物です。 | 1.667507887 | 3 |
| 7 | 彼が成し遂げたことは褒められるべきです。 | 1.561876178 | 5 |
| 8 | この本は多くの読者に感動を与えました。 | 1.466878414 | 29 |
| 9 | その映画の結末は衝撃的でした。 | 1.450572848 | 27 |
| 10 | この書籍は多くの人々の心を打ちました。 | 1.424342155 | 28 |
セマンティックランカーは、Microsoft の経験のもと? 内容を意識して順位を入れ替えてくれます。順位の入替対象となるのは、今回の場合、ハイブリッド検索の結果となります。セマンティックランカーの対象とするには、事前の検索で抽出されることが必要となります。
セマンティックランカーを実行したところ、先ほどのハイブリッド検索順位 7位、8位は押し出されました。かなり下位の順位だったものもトップ10入りしています。
イメージ的には、ハイブリッド検索が予選で、セマンティックランカーは、予選の結果を考慮しない決勝のようなものです。
サンプルデータや検索クエリが悪かったせいで、上記の応答スコアはかなり悪いです。テキスト検索編でも紹介した通り、セマンティックランク付けのスコアは以下のように意味付けされています。
| スコア | スコアの意味 |
|---|---|
| 4.0 | ドキュメントは関連性が高く、質問に完全に回答しますが、文節には、質問と関係のない追加のテキストが含まれている可能性があります。 |
| 3.0 | ドキュメントは、関連性はありますが、完全なものにする詳細は含まれていません。 |
| 2.0 | ドキュメントは、ある程度関連性があり、質問に部分的に回答するか、質問の一部の側面にのみ対処します。 |
| 1.0 | ドキュメントは質問に関連しており、質問のほんの一部に回答します。 |
| 0.0 | ドキュメントは関連性がありません。 |
おわりに
今回は、Azure AI Search のベクトル、ハイブリッド検索、セマンティックランク付けのスコアについて、見ていきました。スコアの付き方を理解すると、どのようにインデックスを構成するか、クエリをどうするかなどチューニング要素が見えてきます。デフォルトの設定で問題無く運用できるケースも多いと思いますが、もう少し精度を上げたいなどがあれば、スコアや順位の状態を確認してみることも良いかと思います。
QUICK E-Solutions では、Azure AI Search を含む 各Azure AI サービスを利用したシステム導入のお手伝いをしております。それ以外でも様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
※このブログで参照されている、Microsoft、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
※その他の会社名、製品名は各社の登録商標または商標です。

