記事公開日
【Azure AI Search】取込み機能の「マルチモーダルRAG」を試してみた

こんにちは。今回は Azure AI Search の 2025年5月に追加された機能で
「データのインポートとベクター化ウィザードの機能強化」にある「マルチモーダルRAG」を試してみます。
本記事は、2025/06/11 時点の情報をもとにしています。
「マルチモーダルRAG」と言っていますが、Azure AI Searchの取込み部分だけ(インデックス作成まで)の確認となりますのでご注意ください。
➡ MSサイトの手順はこちら
データのインポートとベクター化
早速ウィザードを使って、データの取り込み&インデックスの作成を行います。
(1) AI Searchの [概要] ページにある [データのインポートとベクター化] をクリックします。
(2) データソースは、[Azure Blob Storage] を選択します。
(3) [マルチモーダルRAG] を選択します。
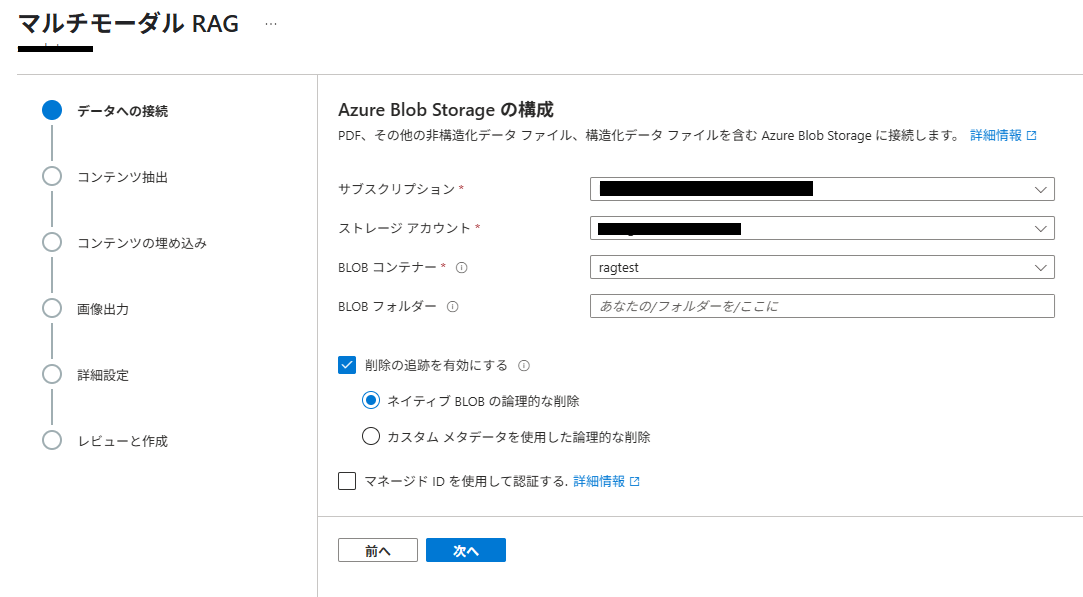
(4) 「データへの接続」では、Azure Blob Storage の BLOBコンテナーを指定します。
※あらかじめ、ストレージアカウントとコンテナーは作成済で、取込みデータも配置済です。
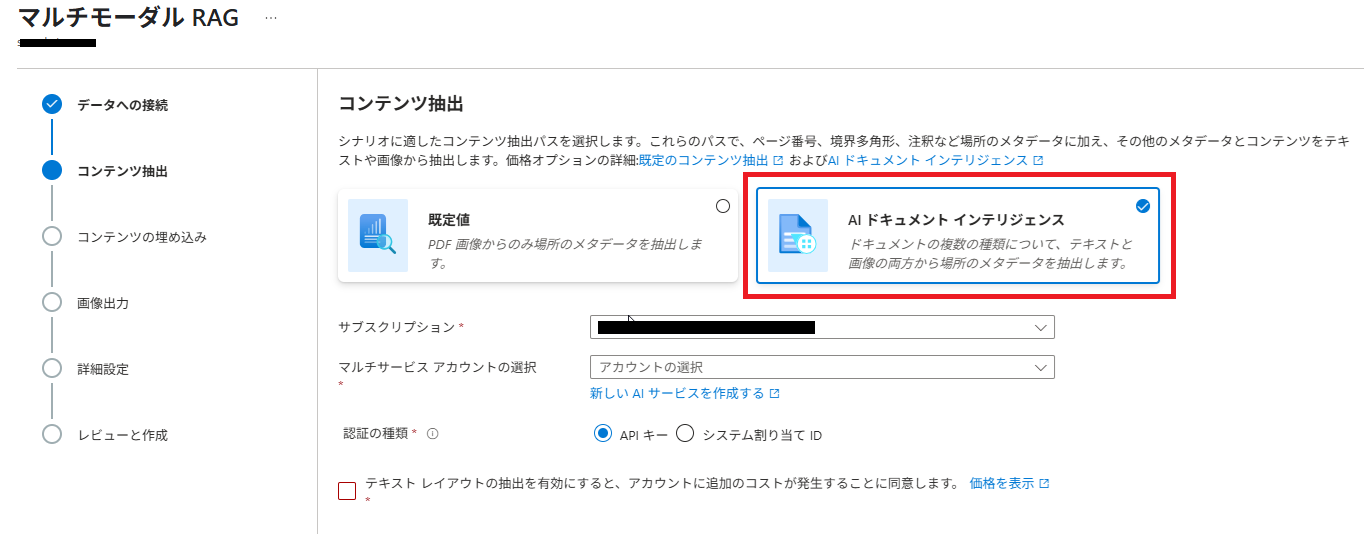
(5) 「コンテンツ抽出」では、[AI ドキュメントインテリジェンス] を選択し、AIサービスのマルチサービスアカウントを指定します。[AIドキュメントインテリジェンス]が使用できないリージョンの場合は、選択できません。
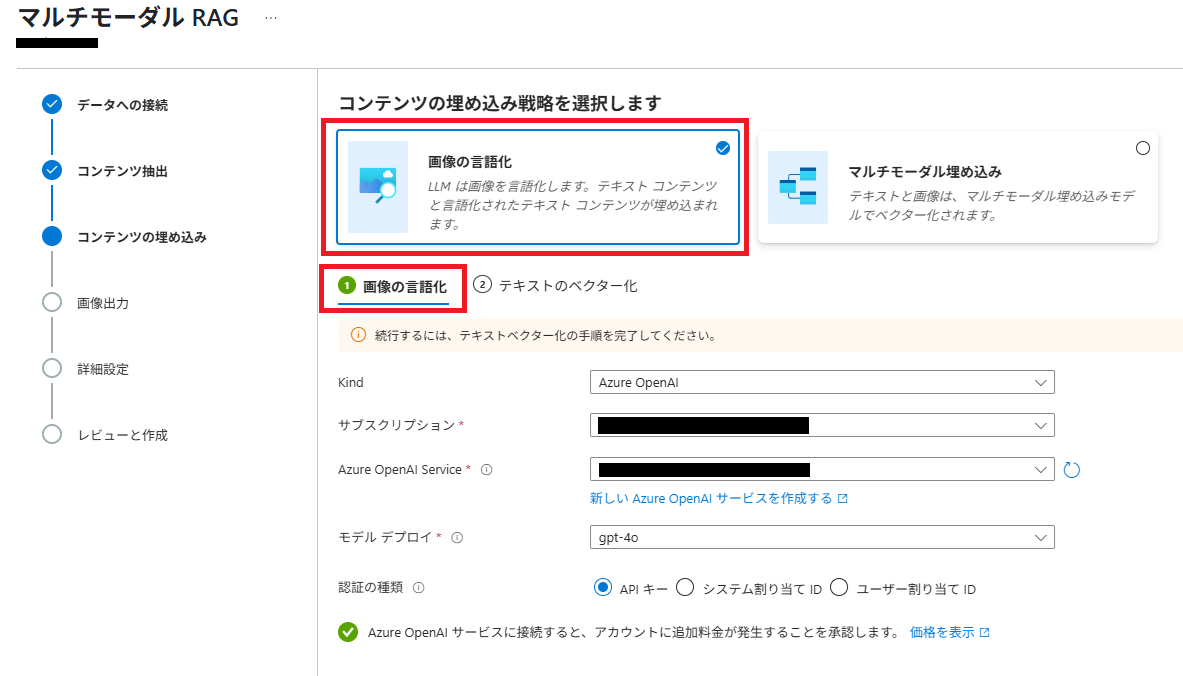
(6) 「コンテンツの埋め込み」では、[画像の言語化]を選択し、[① 画像の言語化] 部分に画像説明に使用する Azure OpenAI デプロイを指定します。ここでは、[gpt-4o] を指定しています。
画像の言語化:画像の説明文の生成、説明文のベクトルデータを生成
マルチモーダル埋め込み:テキストと画像のベクトルデータを生成
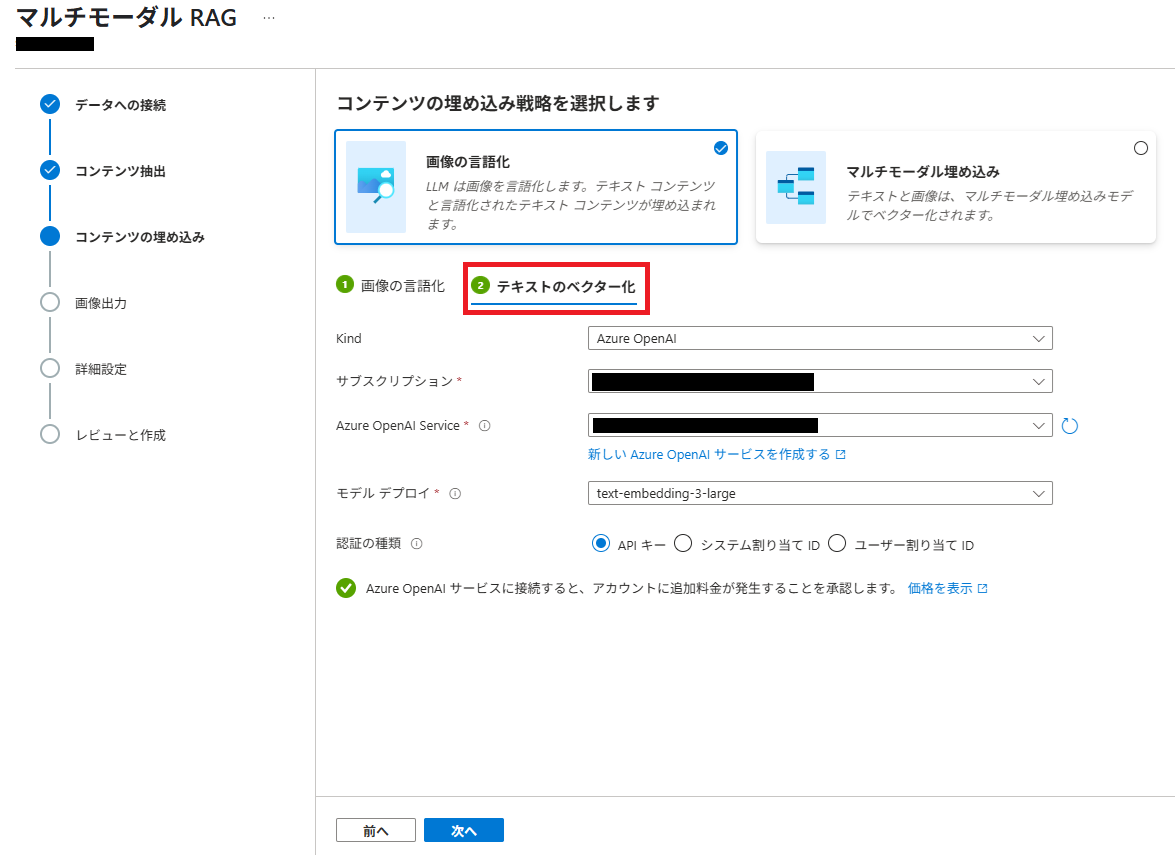
(7) 続けて [② テキストのベクター化] を選択し、ベクター化に使用する Azure OpenAI デプロイを指定します。
ここでは、[text-embedding-3-large] を指定しています。
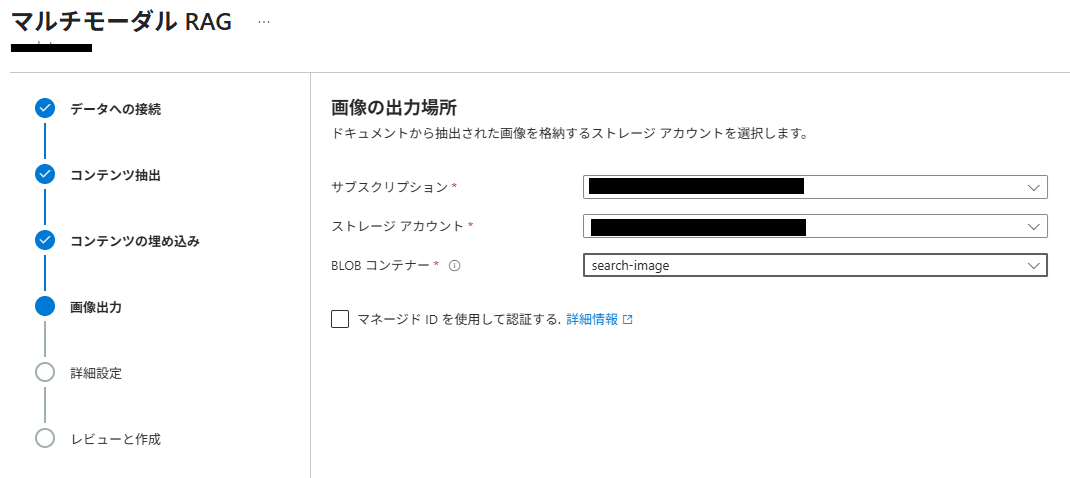
(8) 「画像出力」で、抽出された画像の保存先 BLOBコンテナーを指定します。
ドキュメントから抽出された画像の出力先になります。
(9) 「詳細設定」は、既定値のまま次に進みます。
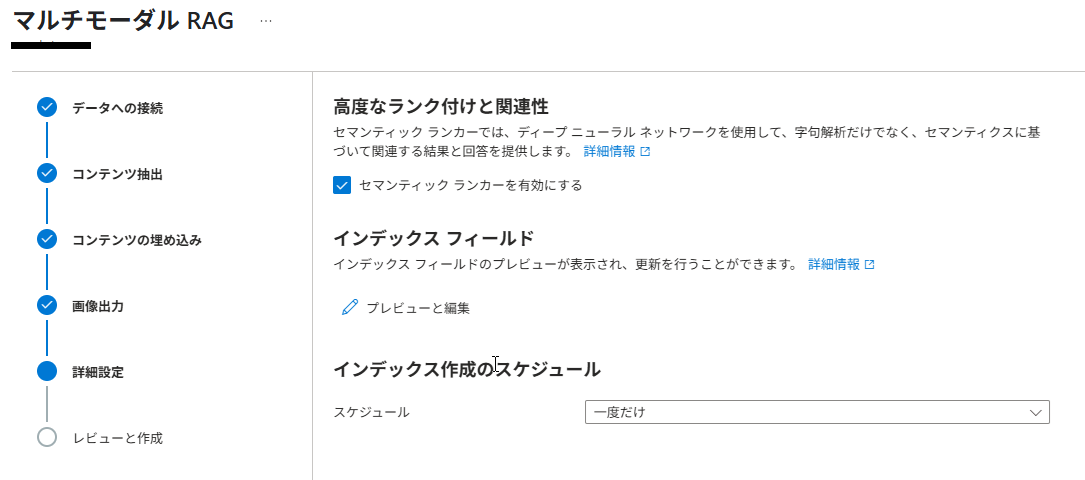
(10) 「レビューと作成」で内容を確認し「作成」ボタンをクリックします。
オブジェクト名のプレフィックスがインデックス名になりますので、任意の名称を設定してください。
この後、インデクサーが自動的に起動しますので、データが取り込まれるまでしばらく待ちます。
構成の確認
ウィザードで自動的に生成された構成を見てみます。
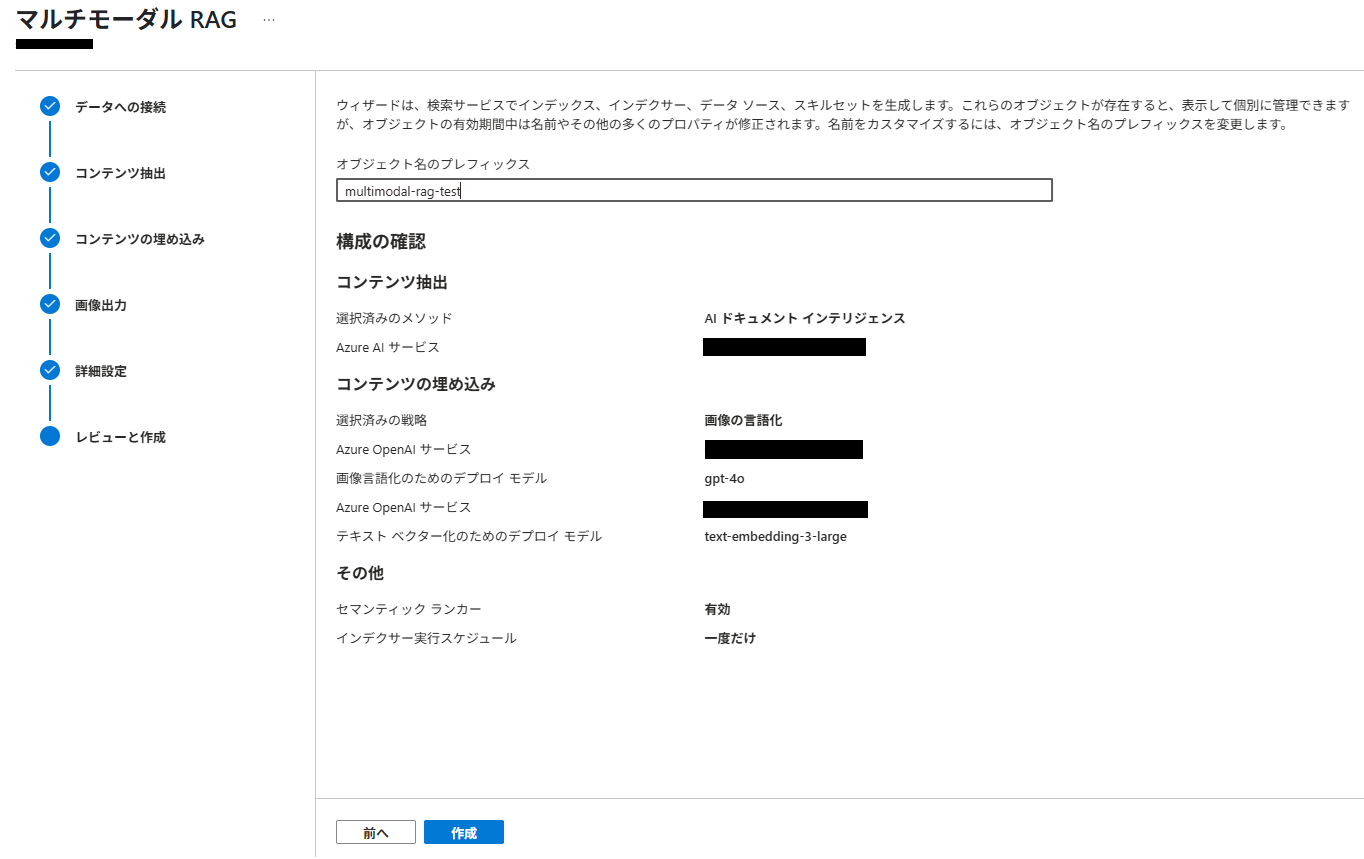
インデックス
インデックスは、このような形で作成されました。検索可能な文字列フィールドのアナライザーは、「Standard-Lucene」になっています。日本語メインの場合は、検索時の精度を高めるためにアナライザーを「日本語Microsoft」または「日本語Lucene」にすべきですが、今回は無視します。
変更する場合は、一旦インデックスを削除して再作成する必要があります。
スキルセット
スキルセットは、以下のようになりました。
画像の言語化で使用されるスキルは、「GenAIプロンプトスキル」と呼ばれるもので、
2つ目に設定されている[#Microsoft.Skills.Custom.ChatCompletionSkill]が該当します。
画像を説明するためのプロンプトが設定されていることが分かります。
{
"@odata.etag": "\"0x8DDA34B5C09B582\"",
"name": "multimodal-rag-test-skillset",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentIntelligenceLayoutSkill",
"name": "#1",
"context": "/document",
"outputMode": "oneToMany",
"outputFormat": "text",
"extractionOptions": [
"images",
"locationMetadata"
],
"inputs": [
{
"name": "file_data",
"source": "/document/file_data",
"inputs": []
}
],
"outputs": [
{
"name": "text_sections",
"targetName": "text_sections"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
],
"chunkingProperties": {
"unit": "characters",
"maximumLength": 2000,
"overlapLength": 200
}
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"name": "#2",
"context": "/document/normalized_images/*",
"uri": "https://******.openai.azure.com/openai/deployments/gpt-4o/chat/completions?api-version=2025-01-01-preview",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1000,
"apiKey": "",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'",
"inputs": []
},
{
"name": "userMessage",
"source": "='Please describe this image.'",
"inputs": []
},
{
"name": "image",
"source": "/document/normalized_images/*/data",
"inputs": []
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
],
"httpHeaders": {}
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#3",
"context": "/document/text_sections/*",
"resourceUri": "https://******.openai.azure.com",
"apiKey": "",
"deploymentId": "text-embedding-3-large",
"dimensions": 3072,
"modelName": "text-embedding-3-large",
"inputs": [
{
"name": "text",
"source": "/document/text_sections/*/content",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#4",
"context": "/document/normalized_images/*",
"resourceUri": "https://******.openai.azure.com",
"apiKey": "",
"deploymentId": "text-embedding-3-large",
"dimensions": 3072,
"modelName": "text-embedding-3-large",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='search-image/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.AIServicesByKey",
"subdomainUrl": "https://******.cognitiveservices.azure.com/"
},
"knowledgeStore": {
"storageConnectionString": null,
"projections": [
{
"tables": [],
"objects": [],
"files": [
{
"storageContainer": "search-image",
"generatedKeyName": "search-imageKey",
"source": "/document/normalized_images/*",
"inputs": []
}
]
}
],
"parameters": {
"synthesizeGeneratedKeyName": true
}
},
"indexProjections": {
"selectors": [
{
"targetIndexName": "multimodal-rag-test",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/text_sections/*",
"mappings": [
{
"name": "content_text",
"source": "/document/text_sections/*/content",
"inputs": []
},
{
"name": "content_embedding",
"source": "/document/text_sections/*/text_vector",
"inputs": []
},
{
"name": "document_title",
"source": "/document/document_title",
"inputs": []
},
{
"name": "locationMetadata",
"source": "/document/text_sections/*/locationMetadata",
"inputs": []
}
]
},
{
"targetIndexName": "multimodal-rag-test",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector",
"inputs": []
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath",
"inputs": []
},
{
"name": "document_title",
"source": "/document/document_title",
"inputs": []
},
{
"name": "locationMetadata",
"source": "/document/normalized_images/*/locationMetadata",
"inputs": []
},
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
}
}
スキルセットの構成は、以下のようになっています。
| スキルセット名 | 説明 |
|---|---|
| ドキュメントレイアウトスキル | Document Intelligence を使用して、ドキュメントのレイアウトを分析します。 画像の抽出、テキストの抽出を行います。 |
| GenAIプロンプトスキル | 抽出された画像の説明を生成します。 |
| Azure OpenAI Embeddingスキル | 抽出したテキスト、画像を説明したテキストのベクトルデータを生成します。 |
| Shaper コグニティブスキル | イメージのパスを設定しています。 |
取り込みデータの確認
インデクサーの実行後に取り込みデータを確認してみます。
※今回は、マイクロソフト社の「Microsoft Azure利用ガイド」を取り込んでいます。
元データから取り込まれた画像は、[image_document_id] が付与され、[content_text] に生成AIによって画像を説明したテキストが設定されています。ただし、デフォルトのままでは、説明文が英語になってしまいました。
[context_path] に画像の出力パスが設定されていることも確認できます。
さらに [locationMetadata]には、ページ番号も埋め込まれています。テキストブロックにもページ番号が埋め込まれていますが、ページ単位のテキストになってしまっているようです。PDF文書の場合、ページ番号が取れるのは魅力ですが、ドキュメントによっては極端にテキスト量が少ないチャンクができる可能性もありますので実装上の考慮が必要になりそうです。
画像の出力先に指定した、BLOBコンテナーを覗いてみると、画像ファイルが格納されていました。
一部画像を見てみると、このような画像が出力されていました。取り込んだドキュメントから抽出された画像になります。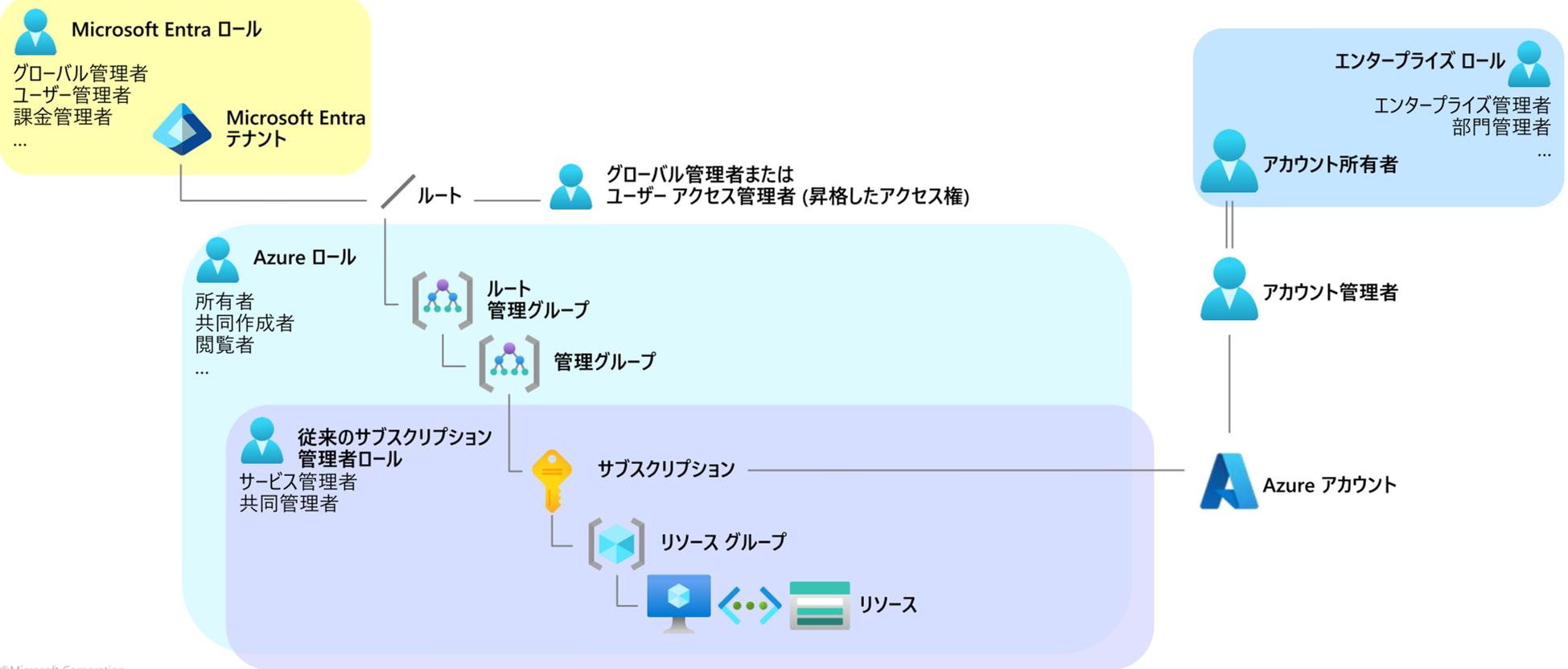
この画像の説明文は、このように生成されています。図を説明していることが分かります。
The diagram illustrates roles and hierarchies within Microsoft Entra and Azure systems.
At the top left, the "Microsoft Entra Tenant" is connected with global, user, and billing
management roles.
These roles have elevated access to the root level, leading to Azure roles such as owner,
collaborator, and viewer, which manage root and other management groups.
Further in the hierarchy are traditional subscription administrator roles,
including service and co-admin, with access to subscriptions, resource groups,
and individual resources. On the right side, enterprise roles like
enterprise administrator and departmental manager oversee
the Azure account and are linked with the account owner and manager roles.
GenAI プロンプトスキルの確認と日本語化
スキルセットの確認
[GenAI プロンプトスキル]の内容を見てみると、プロンプト部分(システムメッセージとそれに続くユーザーメッセージ)が英語になっていました。このため、生成される説明も英語になっていました。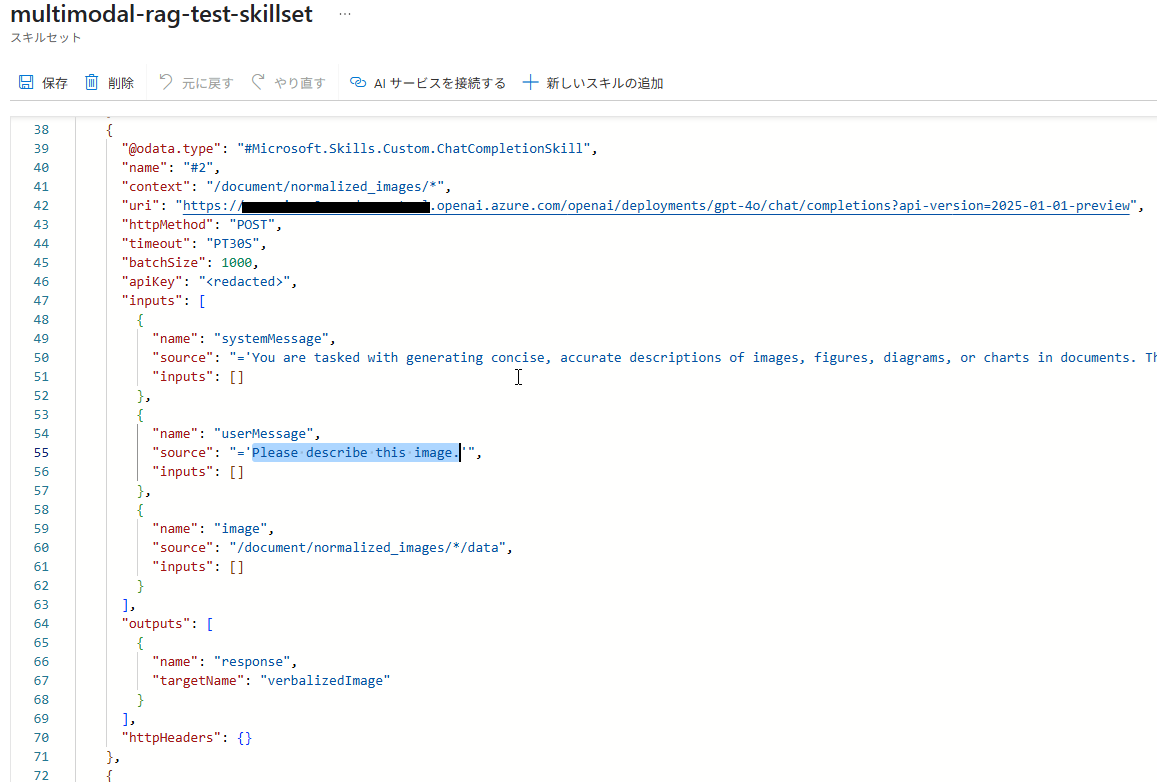
生成する説明の日本語化
生成されるメッセージを日本語化するには、プロンプト部分を日本語とするか、日本語で出力するように指示を修正すれば良いですが、今回は、ユーザーメッセージ部分を「このイメージを日本語で説明してください。」に修正します。
修正後、スキルセットを保存します。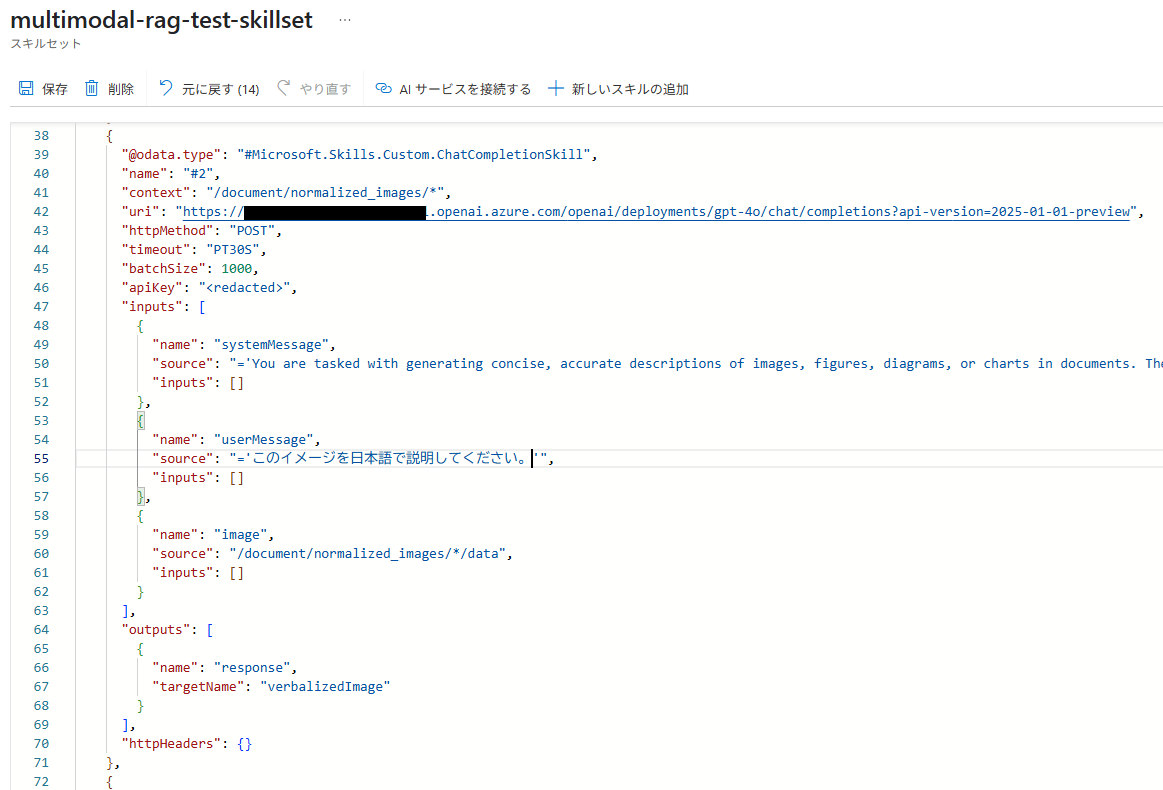
今回、システムメッセージ部分は英語のままとしましたが、日本語に機械翻訳してみると以下のような指示文になっていました。
文書内の画像、図、ダイアグラム、チャートについて、簡潔で正確な説明を作成することが課されます。
ゴールは、スタイル、色、視覚的な美しさ、サイズなどの余計な詳細を含めずに、画像が伝える重要な情報と意味を捉えることです。 指示 内容重視: 画像に描かれている核となる内容や関係を説明する。 ダイアグラムの場合は、主な要素と、それらがどのようにつながっているか、または相互作用しているかを明記する。 図表の場合は、主要なデータポイント、傾向、比較、結論を強調する。 図やテクニカルイラストの場合は、構成要素とその重要性を明確にする。 明確さと正確さ: 明確さと技術的正確さを確保するため、簡潔な表現を用いる。
主観的または解釈的な記述は避ける。 視覚的な説明は避ける:詳細は避ける: 色、陰影、視覚的スタイル。 画像のサイズ、レイアウト、装飾要素。 フォント、ボーダー、文体の装飾。 文脈: 関連性がある場合は、画像を技術文書の幅広い内容やトピックに関連付ける。 説明の例 ダイアグラム: 機械学習パイプラインの4つの段階(データ収集、前処理、モデル学習、評価)を示すフローチャート。タスクの連続した流れを示す矢印。 チャート: 3つのデータセットで4つのアルゴリズムのパフォーマンスを比較した棒グラフ。
アルゴリズムAがデータセット1で一貫して他を上回っていることを示している。 図: エンコーダ、デコーダ、自己注意メカニズム、フィードフォワード層を含むトランスフォーマーモデルの構成要素を示すラベル付き図。
データの確認
スキルセットを修正後、インデクサーをリセットし再度実行します。
インデクサーの実行が完了したら、再びインデックスの内容を確認してみます。
画像の説明箇所は、無事日本語化されたようです。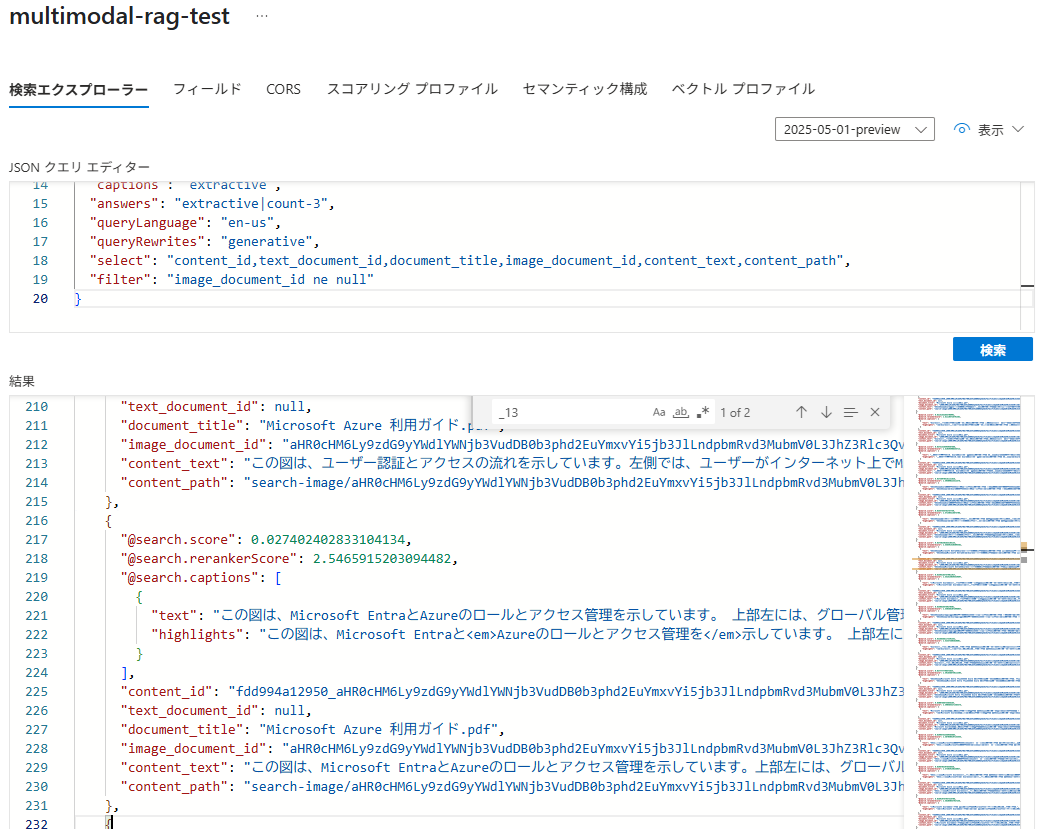
先ほど確認した画像の説明は、このようになっています。図を説明できていることが分かります。
この図は、Microsoft EntraとAzureのロールとアクセス管理を示しています。
上部左には、グローバル管理者、ユーザー管理者、課金管理者などの
Microsoft Entraのロールがあります。
右側では、エンタープライズ管理者や部門管理者を含むエンタープライズロールが表示されています。
中央の部分には、Azureアカウントに関連するルート管理グループと管理グループがあり、
その下に従来のサブスクリプション管理者ロールとして、サービス管理者と共同管理者の
役割が記載されています。サブスクリプションに関連するリソースグループと
リソースも示されています。
インデックスの中に、画像部分の説明が加わることで画像部分にしか含まれていなかった情報の検索にも利用でき、RAGの応答精度が高くなりそうです。
GenAIプロンプトスキルでは、画像の言語化のほかに通常のテキスト情報からの生成もできます。要約文の生成や別の言い回しの生成、ノイズとなる部分の除去など、プロンプトを工夫することで検索精度を高めることもできそうです。
おわりに
今回は、Azure AI Searchの新しい取込みウィザードを試してみました。
他にも新しい機能が追加されているので、別の機能も試してみたいと思います。
QUICK E-Solutions では、各AIサービスを利用したシステム導入のお手伝いをしております。それ以外でも様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
※このブログで参照されている、Microsoft、Azure AI Search、Azure OpenAI、Document Intelligence、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
※その他の会社名、製品名は各社の登録商標または商標です。

