記事公開日
最終更新日
第3回 アマゾンウェブサービス(AWS) AWS Glue⁺Amazon Redshiftを利用したデータウェアハウス構築
はじめに
皆様こんにちは。システムソリューション営業本部の中島です。
今回の記事では、AWS Glue⁺Amazon Redshiftを利用したデータウェアハウス構築についてご説明したいと思います。
今回の記事では、AWS Glue⁺Amazon Redshiftを利用したデータウェアハウス構築についてご説明したいと思います。
AWS Glueについて
AWS Glueは、データエンジニア、抽出、変換、読み込み (ETL) デベロッパー、データアナリスト、データサイエンティストがデータを簡単に抽出、クリーンアップ、強化、正規化、読み込みできるようにするサーバーレスのデータ準備サービスです。このサービスを用いてAmazon Redshiftへのデータインポートを行います。この構築を行う過程で注意するべき点なども解説します。
AWS Glueジョブのタイプについて
AWS GlueジョブにはSpark、Pythonシェル、Spark Streamingの3つのタイプが存在します。
このうち、Spark、Pythonシェルはバッチ等の一定周期のETL処理、Spark Streamingは断続的なETL処理に用います。
本項ではSpark及びPythonシェルのタイプについて説明します。
まずSparkタイプは最初にローンチされたタイプで、分散処理フレームワークのSparkを用いたETL処理の実行が可能です。
また、Sparkタイプのジョブではさらに標準、G.1X、およびG.2Xの3つのワーカータイプを選択出来ます。
用途及び処理を行うデータ量に応じて使い分ける必要があります。
通常のデータ処理では標準で問題ありませんが、大量データの処理を行う場合、ETL処理中にエラー中断する可能性があります。
Pythonシェルタイプは名前の通り、AWS Glue でシェルとして Python スクリプトを実行できます。1ワーカー辺りのサイズを1 DPU (Data Processing Unit) または 0.0625 DPUのいずれかを選択可能です。
またSparkタイプ、Pythonシェルのいずれにおいてもワーカー数の指定(水平スケーリング)が可能です。
このうち、Spark、Pythonシェルはバッチ等の一定周期のETL処理、Spark Streamingは断続的なETL処理に用います。
本項ではSpark及びPythonシェルのタイプについて説明します。
まずSparkタイプは最初にローンチされたタイプで、分散処理フレームワークのSparkを用いたETL処理の実行が可能です。
また、Sparkタイプのジョブではさらに標準、G.1X、およびG.2Xの3つのワーカータイプを選択出来ます。
用途及び処理を行うデータ量に応じて使い分ける必要があります。
通常のデータ処理では標準で問題ありませんが、大量データの処理を行う場合、ETL処理中にエラー中断する可能性があります。
Pythonシェルタイプは名前の通り、AWS Glue でシェルとして Python スクリプトを実行できます。1ワーカー辺りのサイズを1 DPU (Data Processing Unit) または 0.0625 DPUのいずれかを選択可能です。
またSparkタイプ、Pythonシェルのいずれにおいてもワーカー数の指定(水平スケーリング)が可能です。
SparkタイプのGlueを用いたロード処理
今回は以下の構成にてS3バケットからVPC内のRedShiftへのロードを行います。
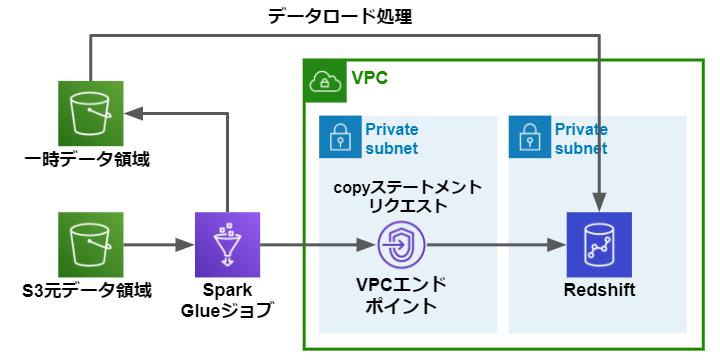
Glueジョブの実装はこちらを参考にしてください。
GlueジョブはS3からRedShiftへロードするにあたり、以下の処理を行います。
Glueジョブの実装はこちらを参考にしてください。
GlueジョブはS3からRedShiftへロードするにあたり、以下の処理を行います。
- 元データのS3パスからデータ取得
- データの抽出および変換
- 変換後データをS3の一時領域へアップロード
- S3の一時領域からRedShiftへのcopyステートメントリクエスト
SparkタイプのGlueジョブの注意点
実装は上記URLを参考にすることで問題ありませんがいくつかの注意する点があります。
1)GlueのVPCエンドポイント用サブネットのCIDR設計
GlueのVPCエンドポイントが確保するIPアドレスはGlueジョブのワーカー数及び同時実行数に依存し、ジョブ実行時に動的に増えます。
VPCエンドポイント用サブネットのCIDRが必要なIPアドレス数以下の場合、Glueジョブは失敗します。
例えばワーカータイプが標準の場合、以下のようにIPアドレスが確保されます。
また、G.1X、およびG.2Xの場合、以下のようになります。
そのため、GlueのVPCエンドポイント用サブネットのCIDRは実行に応じた設計を行う必要があります。
VPCエンドポイント用サブネットのCIDRが必要なIPアドレス数以下の場合、Glueジョブは失敗します。
例えばワーカータイプが標準の場合、以下のようにIPアドレスが確保されます。
IPアドレス数 = DPU × ジョブ実行数
また、G.1X、およびG.2Xの場合、以下のようになります。
IPアドレス数 = (ワーカー数 ⁺ 1) × ジョブ実行数
そのため、GlueのVPCエンドポイント用サブネットのCIDRは実行に応じた設計を行う必要があります。
2)大量のファイルをRedShiftへのロードする場合のワーカータイプ指定
大量のファイルをRedShiftへロードする場合、非常に大きなメモリ負荷がかかりOOM エラーが発生することがあります。
GlueジョブがS3からデータをダウンロードする処理にてS3関連のAPIをコールします、この処理のメモリ負荷によりエラーが発生します。
この処理は親ノードが単独で実行するため1ノード辺りのメモリ量が影響します。したがって、いくらノード数を増やしてもエラーを解消することができません。
そのため、この現象を解消するためにはワーカー数を増やす水平スケーリングではなく、ワーカータイプを変更する垂直のスケーリングを行う必要があります。
ロードするファイル数に応じて適切なワーカータイプを設定してください。
GlueジョブがS3からデータをダウンロードする処理にてS3関連のAPIをコールします、この処理のメモリ負荷によりエラーが発生します。
この処理は親ノードが単独で実行するため1ノード辺りのメモリ量が影響します。したがって、いくらノード数を増やしてもエラーを解消することができません。
そのため、この現象を解消するためにはワーカー数を増やす水平スケーリングではなく、ワーカータイプを変更する垂直のスケーリングを行う必要があります。
ロードするファイル数に応じて適切なワーカータイプを設定してください。
3)データロード処理のチューニングについて
Glueはデータ取得~変換~一時データアップロード~copyのステートメントリクエストを実行します。
上記の通り、RedShiftへのcopyはステートメントリクエストまではGlueジョブが行いますが実際のロード処理はRedShiftが処理を行うためRedShiftの処理能力がレイテンシーに影響します。
そのため、RedShiftへロード処理のチューニングはGlueジョブとRedShiftのCloudWatchメトリクスの両方を確認しながら行う必要があります。
また、RedShiftのcopy処理実行中はGlueジョブのステータスは実行中と表示されていますが実際のGlueのワーカーは待機している状態です。待機中も設定したワーカー数及びDPUに応じたAWS利用料金が発生するので注意が必要です。
上記の通り、RedShiftへのcopyはステートメントリクエストまではGlueジョブが行いますが実際のロード処理はRedShiftが処理を行うためRedShiftの処理能力がレイテンシーに影響します。
そのため、RedShiftへロード処理のチューニングはGlueジョブとRedShiftのCloudWatchメトリクスの両方を確認しながら行う必要があります。
また、RedShiftのcopy処理実行中はGlueジョブのステータスは実行中と表示されていますが実際のGlueのワーカーは待機している状態です。待機中も設定したワーカー数及びDPUに応じたAWS利用料金が発生するので注意が必要です。
4)Glueジョブが使用するS3の一時領域について
Glueジョブにより一時領域へアップロードされた実データはGlueジョブが終了後も削除されずS3に残ります。
そのためセキュリティやコスト面を考慮し、ジョブ終了をトリガーとした一時データ削除又は一定周期のデータ削除などの対応を行う必要があります。
また、アップロードされるデータは実データのため一時アップロード領域の暗号化、アクセス制御も合わせて設定する必要があります。
そのためセキュリティやコスト面を考慮し、ジョブ終了をトリガーとした一時データ削除又は一定周期のデータ削除などの対応を行う必要があります。
また、アップロードされるデータは実データのため一時アップロード領域の暗号化、アクセス制御も合わせて設定する必要があります。
PythonシェルタイプのGlueを用いたロード処理
以下の構成にてPythonシェルタイプのRedShiftへのロードを行います。
データロードの過程でデータの抽出および変換が必要ない場合等はこちらを採用することでレイテンシーが低くなる可能性があります。
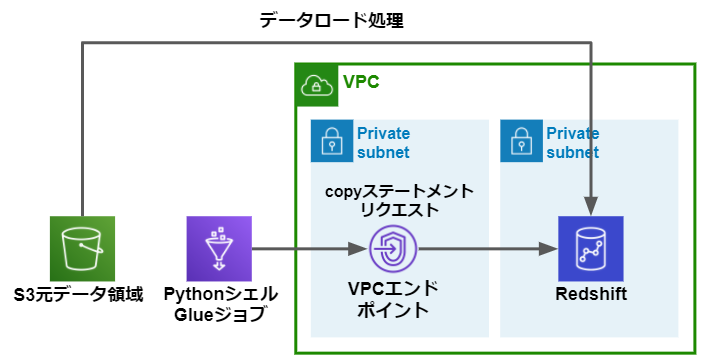
Glueジョブの実装はこちらを参考にしてください。
PythonシェルタイプのGlueジョブはS3からRedShiftへロードするにあたり、以下の処理のみを行います。
データロードの過程でデータの抽出および変換が必要ない場合等はこちらを採用することでレイテンシーが低くなる可能性があります。
Glueジョブの実装はこちらを参考にしてください。
PythonシェルタイプのGlueジョブはS3からRedShiftへロードするにあたり、以下の処理のみを行います。
- 元データのS3パスからRedShiftへのcopyステートメントリクエスト
PythonシェルタイプのGlueジョブの注意点
PythonシェルタイプのGlueジョブによるロード処理の注意点は多くはありませんが変換処理やデータの分割処理が存在しないため、大量ファイルのロードや大容量の単一ファイル取込み等はRedShiftのCloudWatchメトリクスを注視する必要があります。
まとめ
いかがでしたでしょうか。
今回は AWS Glueを用いた2パターンのデータウェアハウスへのロードを解説させていただきました。
元データの変換処理が必要な場合はSparkタイプ、そうでない場合はPythonシェルを採用する等の使い分けを行うことで効率的なデータロードが可能かと思います。
最後までお読みいただき、誠にありがとうございました!
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください! のちほど当ブログにてご紹介させていただくか、複雑な内容に関するお問い合わせの内容の場合には直接営業からご連絡を差し上げます。
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
今回は AWS Glueを用いた2パターンのデータウェアハウスへのロードを解説させていただきました。
元データの変換処理が必要な場合はSparkタイプ、そうでない場合はPythonシェルを採用する等の使い分けを行うことで効率的なデータロードが可能かと思います。
最後までお読みいただき、誠にありがとうございました!
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問合せフォームまでお気軽にご連絡ください! のちほど当ブログにてご紹介させていただくか、複雑な内容に関するお問い合わせの内容の場合には直接営業からご連絡を差し上げます。
※Amazon Web Services、”Powered by Amazon Web Services”ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※Pythonは、Python Software Foundationの登録商標です。
※Apache Spark、Sparkは、Apache Software Foundationの米国およびその他の国における登録商標または商標です。
※Apache Spark、Sparkは、Apache Software Foundationの米国およびその他の国における登録商標または商標です。

