記事公開日
MCPサーバーを自作してClaude Codeで使ってみた!

この記事のポイント
この記事では、自作のMCPサーバーをAmazon ECS上にリモート公開し、Amazon Cognitoの認証付きでClaudeから利用するまでを、検証ベースで解説します。
- 結論:ローカルのMCPサーバーは、コードを大きく変えずにリモート公開できる:
トランスポートをstdioから Streamable HTTP に切り替え、トークン検証を足すだけで、Claudeのリモートコネクタとして動かせました。 - ECS Express Modeなら基盤構築の手間が小さい:
コンテナイメージを指定するだけで、VPC・ロードバランサー・Fargateサービス・オートスケールまで自動構成され、認証はアプリ側(リソースサーバー)でJWTを検証する役割分担になります。 - Claudeの個人カスタムコネクタから3つのツールが呼べた:
OAuthログインを経て、add_memo/list_memos/delete_memoがユーザーごとに分離されたデータに対して動作することを確認しました。
こんにちは!DXソリューション営業本部の菊池です。
普段からClaudeなどでModel Context Protocol(MCP)を使っているのですが、ふと「中身はどうなっているんだろう?」と気になり、自分でMCPサーバーを作ってみることにしました。今回は、自作したメモ管理用のMCPサーバーを、Amazon ECS(Express Mode)でリモート公開し、Amazon Cognitoの認証を付けてClaudeから使うところまでを試してみたので、その様子をご紹介します!
※本記事は2026/06/24時点の検証結果です。最新情報は公式ドキュメントをご確認ください。
検証環境は次の通りです。
- リージョン:ap-northeast-1
- 開発環境のPython:3.14.4
- コンテナのベースイメージ:
python:3.12-slim - 主要パッケージ:
mcp>=1.2.0/pyjwt[crypto]/boto3 - Claude Code:2.1.195(開発・動作確認に使用)
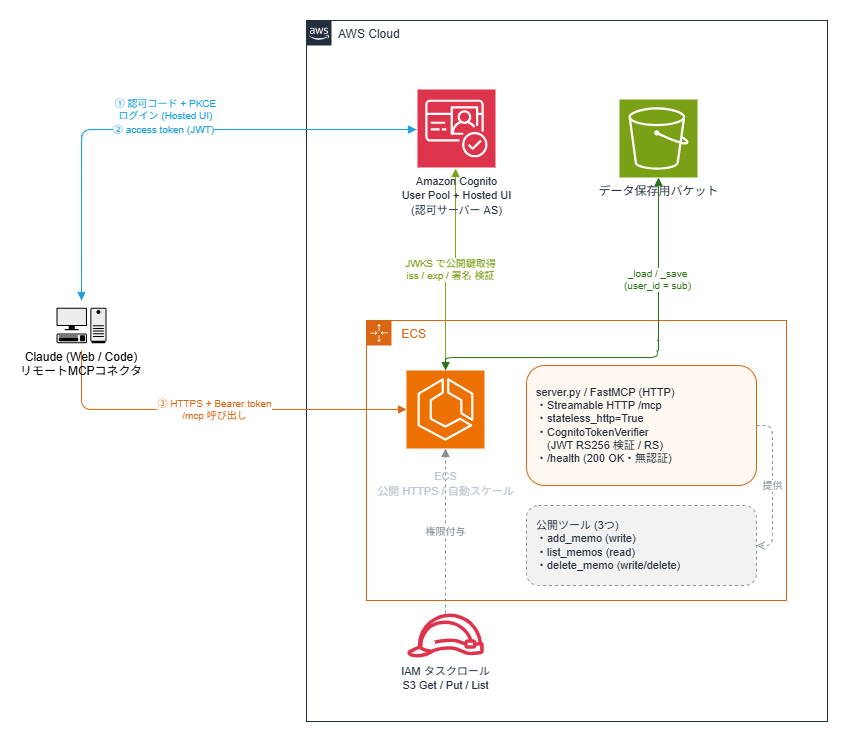
リモートMCPの全体像
本題に入る前に、登場人物と役割を整理しておきます。
今回の構成では、認可サーバー(Cognito)とリソースサーバー(ECS上のMCPサーバー)が分かれています。
- Claude(クライアント):カスタムコネクタとしてMCPサーバーを呼び出す側。OAuthでログインし、アクセストークンを取得します。
- Amazon Cognito(認可サーバー / AS):ユーザーのログイン画面(Hosted UI)を提供し、検証済みのユーザーにアクセストークン(JWT)を発行します。
- ECS上のMCPサーバー(リソースサーバー / RS):届いたアクセストークンを検証するだけ。ログインUIは持ちません。検証が通ったらツールを実行します。
- Amazon S3(データ保存):メモデータを、ユーザーごとに分離して保存します。
ポイントは、ECS(App側)は認証機能を持たないということです。「誰をログインさせるか」はCognitoに任せ、MCPサーバーは「正しいトークンか」を検証する責務に徹します。
ここから、まずMCPサーバー本体(server.py)が何をしているかを見ていきます。
MCPサーバー(server.py)の説明
サーバーは FastMCP を使って実装しています。
提供するツールは add_memo / list_memos / delete_memo の3つだけのシンプルなものです。
クリックして server.py の全文を表示
import json
import os
import sys
from datetime import datetime
from pathlib import Path
import boto3
import botocore.exceptions
import jwt
from jwt import PyJWKClient
from starlette.requests import Request
from starlette.responses import JSONResponse
from mcp.server.auth.middleware.auth_context import get_access_token
from mcp.server.auth.provider import AccessToken, TokenVerifier
from mcp.server.auth.settings import AuthSettings
from mcp.server.fastmcp import FastMCP
DATA_FILE = Path(
os.environ.get("MEMO_STORE_PATH", Path.home() / ".memo-store" / "memos.json")
)
def _build_auth():
if os.environ.get("MEMO_AUTH", "none").lower() != "cognito":
return None, None
region = os.environ["COGNITO_REGION"]
pool_id = os.environ["COGNITO_USER_POOL_ID"]
resource_url = os.environ["MEMO_RESOURCE_SERVER_URL"]
expected_client_id = os.environ.get("COGNITO_CLIENT_ID")
issuer = f"https://cognito-idp.{region}.amazonaws.com/{pool_id}"
jwks_url = f"{issuer}/.well-known/jwks.json"
class CognitoTokenVerifier(TokenVerifier):
def __init__(self) -> None:
self._jwks = PyJWKClient(jwks_url)
async def verify_token(self, token: str) -> "AccessToken | None":
try:
signing_key = self._jwks.get_signing_key_from_jwt(token)
claims = jwt.decode(
token,
signing_key.key,
algorithms=["RS256"],
issuer=issuer,
options={"verify_aud": False},
)
except Exception as e:
print(f"[memo-store] トークン検証に失敗: {e}", file=sys.stderr)
return None
if claims.get("token_use") not in (None, "access"):
return None
if expected_client_id and claims.get("client_id") != expected_client_id:
print("[memo-store] client_id が一致しません", file=sys.stderr)
return None
scope = claims.get("scope", "")
return AccessToken(
token=token,
client_id=claims.get("client_id", ""),
scopes=scope.split() if scope else [],
expires_at=claims.get("exp"),
subject=claims.get("sub"),
claims=claims,
)
auth_settings = AuthSettings(
issuer_url=issuer,
resource_server_url=resource_url,
required_scopes=[],
)
print(f"[memo-store] OAuth 認証を有効化 (issuer={issuer})", file=sys.stderr)
return CognitoTokenVerifier(), auth_settings
_token_verifier, _auth_settings = _build_auth()
_is_http = os.environ.get("MEMO_TRANSPORT", "stdio") == "http"
mcp = FastMCP(
"memo-store",
host=os.environ.get("MEMO_HOST", "127.0.0.1"),
port=int(os.environ.get("MEMO_PORT", "8000")),
token_verifier=_token_verifier,
auth=_auth_settings,
stateless_http=_is_http,
)
@mcp.custom_route("/health", methods=["GET"])
async def health_check(_request: Request) -> JSONResponse:
return JSONResponse({"status": "ok"})
STORE_BACKEND = os.environ.get("MEMO_STORE_BACKEND", "file").lower()
S3_BUCKET = os.environ.get("MEMO_S3_BUCKET")
S3_PREFIX = os.environ.get("MEMO_S3_PREFIX", "memos/")
def _current_user_id() -> str:
try:
token = get_access_token()
if token and token.subject:
return token.subject
except Exception:
pass
return "local"
def _file_path(user_id: str) -> Path:
if user_id == "local":
return DATA_FILE
return DATA_FILE.parent / f"{user_id}.json"
def _s3_key(user_id: str) -> str:
return f"{S3_PREFIX}{user_id}.json"
def _load(user_id: str) -> list[dict]:
if STORE_BACKEND == "s3":
try:
obj = boto3.client("s3").get_object(Bucket=S3_BUCKET, Key=_s3_key(user_id))
return json.loads(obj["Body"].read().decode("utf-8"))
except botocore.exceptions.ClientError as e:
if e.response.get("Error", {}).get("Code") in ("NoSuchKey", "404"):
return []
raise
except json.JSONDecodeError:
print("[memo-store] S3 オブジェクトの JSON 解析に失敗しました", file=sys.stderr)
return []
path = _file_path(user_id)
if not path.exists():
return []
try:
return json.loads(path.read_text(encoding="utf-8"))
except json.JSONDecodeError:
print(f"[memo-store] {path} の読み込みに失敗しました", file=sys.stderr)
return []
def _save(user_id: str, memos: list[dict]) -> None:
body = json.dumps(memos, ensure_ascii=False, indent=2)
if STORE_BACKEND == "s3":
boto3.client("s3").put_object(
Bucket=S3_BUCKET,
Key=_s3_key(user_id),
Body=body.encode("utf-8"),
ContentType="application/json",
)
return
path = _file_path(user_id)
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(body, encoding="utf-8")
@mcp.tool()
async def add_memo(title: str, content: str, tags: list[str] | None = None) -> dict:
"""メモを1件追加して保存する(認証ユーザーごとに分離)。
Args:
title: メモのタイトル(短い見出し)
content: メモの本文
tags: 任意のタグの一覧(省略可。例: ["仕事", "MCP"])
Returns:
追加されたメモ(id・作成日時を含む)
"""
user_id = _current_user_id()
memos = _load(user_id)
next_id = max((m["id"] for m in memos), default=0) + 1
memo = {
"id": next_id,
"title": title,
"content": content,
"tags": tags or [],
"created_at": datetime.now().isoformat(timespec="seconds"),
}
memos.append(memo)
_save(user_id, memos)
return {"message": "メモを追加しました", "memo": memo}
@mcp.tool()
async def list_memos() -> list[dict]:
"""保存されているメモを全件、新しい順で返す(認証ユーザーごとに分離)。
Returns:
メモの一覧。1件もなければ空のリスト。
"""
memos = _load(_current_user_id())
return sorted(memos, key=lambda m: m["id"], reverse=True)
@mcp.tool()
async def delete_memo(memo_id: int) -> dict:
"""指定したIDのメモを削除する(認証ユーザーごとに分離)。
Args:
memo_id: 削除するメモのID(list_memos で確認できる)
Returns:
削除結果のメッセージ。該当IDが無ければエラー内容を返す。
"""
user_id = _current_user_id()
memos = _load(user_id)
target = next((m for m in memos if m["id"] == memo_id), None)
if target is None:
return {"error": f"ID {memo_id} のメモは見つかりませんでした"}
memos = [m for m in memos if m["id"] != memo_id]
_save(user_id, memos)
return {"message": f"ID {memo_id} のメモを削除しました", "deleted": target}
if __name__ == "__main__":
transport = os.environ.get("MEMO_TRANSPORT", "stdio")
if transport == "http":
print(
f"[memo-store] Streamable HTTP で起動します "
f"(http://{mcp.settings.host}:{mcp.settings.port}/mcp)",
file=sys.stderr,
)
mcp.run(transport="streamable-http")
else:
mcp.run()
FastMCP は、MCPサーバーを少ないコードで実装できるmcpパッケージに同梱のフレームワークです。ツールの定義に加え、トランスポート(stdio / Streamable HTTP)や認証(リソースサーバー)といった今回使う機能もまとめて扱えます。詳細は以下の公式ドキュメントをご確認ください。
1. トランスポートの切り替え(stdio → Streamable HTTP)
ローカルでは stdio、リモートでは Streamable HTTP で待ち受けます。環境変数 MEMO_TRANSPORT で切り替えられるようにし、コードの本体は共通にしています。
ローカルのポートはデプロイ前の疎通確認で使用しました。
server.py(抜粋)
mcp = FastMCP(
"memo-store",
host=os.environ.get("MEMO_HOST", "127.0.0.1"), # 公開時は 0.0.0.0
port=int(os.environ.get("MEMO_PORT", "8000")),
token_verifier=_token_verifier,
auth=_auth_settings,
stateless_http=_is_http, # HTTP公開時は True
)
# ...
if transport == "http":
mcp.run(transport="streamable-http") # 公開エンドポイントは既定で /mcp
else:
mcp.run() # stdio
ECSはスケールアウトするとリクエストが複数のコンテナに分散し、セッションアフィニティ(同じコンテナに振り続けること)は保証されません。
そのため、stateless_http=True を設定しステートレスにすることで、どのコンテナに振られてもセッションが壊れないようにしています。
今回のメモMCPは進捗通知やサンプリングといったステートフルな機能を使わないため、ステートレスで問題ありません。
2. リソースサーバー化(Cognito発行のJWTを検証する)
リモート公開で一番のキモが、トークン検証です。FastMCP はOAuth 2.1のリソースサーバー機能を持っており、別の認可サーバー(今回はCognito)が発行したアクセストークンを検証できます。
Cognitoの公開鍵(JWKS)を使ってJWTの署名・発行者・有効期限を検証する TokenVerifier を実装します。骨子は次の通りです。
server.py(抜粋)
class CognitoTokenVerifier(TokenVerifier):
def __init__(self) -> None:
# 公開鍵はキャッシュされる(毎回JWKSを取りに行かない)
self._jwks = PyJWKClient(jwks_url)
async def verify_token(self, token: str) -> "AccessToken | None":
try:
signing_key = self._jwks.get_signing_key_from_jwt(token)
claims = jwt.decode(
token,
signing_key.key,
algorithms=["RS256"],
issuer=issuer,
options={"verify_aud": False}, # ← 後述
)
except Exception as e:
print(f"[memo-store] トークン検証に失敗: {e}", file=sys.stderr)
return None
# access token であること & client_id の照合(任意)
if claims.get("token_use") not in (None, "access"):
return None
return AccessToken(
token=token,
client_id=claims.get("client_id", ""),
scopes=(claims.get("scope") or "").split(),
expires_at=claims.get("exp"),
subject=claims.get("sub"), # ← ユーザー識別に使う
claims=claims,
)
ここで一番ハマりやすいのが verify_aud=False です。
Cognitoのアクセストークンは、デフォルトでは aud(audience)を持ちません。代わりに client_id を持ち、種別は token_use: access で示されます。そのため aud 検証を有効にすると「aud が無い」で必ず失敗します。
今回は aud 検証を無効化し、代わりに iss(発行者)・exp(有効期限)・署名(RS256)を検証したうえで、token_use == "access" と client_id を照合しています(RS256の署名検証に公開鍵暗号が要るため、依存に pyjwt[crypto] を入れています)。
なお、クライアントに「どこの認可サーバーでログインすべきか」を知らせる保護リソースメタデータ(/.well-known/oauth-protected-resource)は、SDKが自動で生成してくれます。
※MCPの仕様では、リソースサーバーは「そのトークンが自分宛て(intended audience)に発行されたか」を検証すべきとされています。今回の client_id 照合はその代替で、より仕様に忠実にするなら、Cognitoでリソースサーバー(カスタムスコープ)を定義してアクセストークンに aud を持たせ、aud で検証する方法があります。
Cognitoのアクセストークンの仕様については、以下の公式ドキュメントをご参照ください。
3. ユーザーごとのデータ分離とS3保存
検証に成功したトークンからは subject(CognitoのユーザーID、sub)が取り出せます。これをそのままデータの分離キーに使い、ユーザーごとにメモを分けて保存します。
server.py(抜粋)
def _current_user_id() -> str:
token = get_access_token()
if token and token.subject:
return token.subject # Cognito の sub
return "local" # 未認証(ローカル stdio など)
保存先はバックエンドを環境変数 MEMO_STORE_BACKEND で切り替えられるようにしてあり、リモート公開時は Amazon S3 を使います。キーは memos/<sub>.json という形で、ユーザーごとに1オブジェクトです。
server.py(抜粋)
# s3 バックエンド時のキー
def _s3_key(user_id: str) -> str:
return f"{S3_PREFIX}{user_id}.json" # 例: memos/<sub>.json
ECSのコンテナファイルシステムは揮発性で、再デプロイやスケールで消えてしまいます。そのため、永続化したいデータはコンテナの外で持つようにします。(今回はS3を採用。用途によってはEFSやEBSも選択肢になります)。
4. 認証不要のヘルスチェック用エンドポイント
最後に細かいですが効いてくるポイントです。ロードバランサーは「HTTPで200が返るパス」でコンテナの健全性を判定します。
MCPの /mcp はGETだと 406 を返すためヘルスチェックに使えません。そこで、認証不要で、リクエストが届けば200を返す /health を別途用意しています。これは「プロセスが起動してHTTPを処理できる」ことの確認用で、S3やCognitoといった依存先の健全性までチェックするものではない、という点には留意してください。
server.py(抜粋)
@mcp.custom_route("/health", methods=["GET"])
async def health_check(_request: Request) -> JSONResponse:
return JSONResponse({"status": "ok"})
MCPの仕様については、以下の公式ドキュメントをご参照ください。
サーバー側の準備ができたので、次はこれを動かすAWS環境を見ていきます。
AWS環境の説明
ここからは、MCPサーバーを公開するためのAWS環境の構成を説明します。
全体としては「コンテナ実行=ECS Express Mode」「認証=Cognito」「保存=S3+IAM」の3ブロックです。
ECS Express Modeとは
Amazon ECSのExpress Modeは、コンテナイメージを指定するだけで、Webアプリの実行に必要な一式をまとめて立ち上げてくれるデプロイ方式です。
個別にVPCやロードバランサーを設計しなくても、裏で次のようなリソースが自動的に構成されます。
- ネットワーク設定とセキュリティグループ
- 外部公開用のロードバランサーとターゲットグループ(HTTPSの公開URLを払い出し)
- AWS Fargateで動くECSサービス/タスク(サーバーレスでコンテナを実行)
- 負荷に応じたオートスケール設定
従来、ECS Fargateで公開Webアプリを動かすには、VPC・ALB・ターゲットグループ・サービス・タスク定義・スケーリングを自分で組み合わせる必要がありました。Express Modeはそこを大きく省力化してくれます。
1. コンテナ化(Dockerfile)
ECSはコンテナを動かすので、まず Dockerfile を用意します。HTTPで公開するための環境変数を設定し、ポートを開けておきます。
Dockerfile
FROM python:3.12-slim
WORKDIR /app
# 依存だけ先に入れてレイヤキャッシュを効かせる
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY server.py .
# HTTPで公開する設定(ポートは公開先に合わせる)
ENV MEMO_TRANSPORT=http \
MEMO_HOST=0.0.0.0 \
MEMO_PORT=8080
EXPOSE 8080
CMD ["python", "server.py"]
このサーバー自体は平文HTTPで動作します。TLS終端(HTTPS化)はロードバランサーに任せており、Express Modeがその部分も含めて払い出してくれます。
2. イメージをECRにpushしてデプロイする
ビルドしたイメージをAmazon ECRに登録し、それをECS Express Modeのソースとして指定してデプロイします。
ターミナルで実行(AWS CLI)
export AWS_REGION=ap-northeast-1
export ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
export REPO=local-memo-mcp
# リポジトリ作成(初回のみ)
aws ecr create-repository --repository-name $REPO --region $AWS_REGION
# ログイン
aws ecr get-login-password --region $AWS_REGION \
| docker login --username AWS --password-stdin \
$ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com
# ビルド & タグ付け & push
docker build -t $REPO .
docker tag $REPO:latest \
$ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$REPO:latest
docker push $ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/$REPO:latest
デプロイ時には、コンテナに渡す環境変数(MEMO_TRANSPORT=httpやCognito・S3関連の値)と、後述のタスクロールを指定します。デプロイが完了すると、公開用のHTTPS URLが払い出されます(この末尾に /mcp を付けたものがMCPのエンドポイントです)。
3. 認証基盤(Amazon Cognito)
認可サーバーとしてCognitoのユーザープールを用意しました。重要な設定は次の通りです。
- Hosted UIのドメイン:ユーザーが実際にログインする画面(マネージドのフロント)です。これを有効化しないと
authorizeエンドポイント=ログイン画面が生えず、OAuthフローが成立しません。 - アプリクライアント:認可コードフロー(PKCE併用)を有効化。Claudeのコネクタ側に手入力するClient ID / Client Secretを発行します。
- コールバックURL:Claudeがコネクタ登録時に示すリダイレクトURIを許可しておきます。
Cognitoから払い出される主要なメタデータは次の通りで、これらをMCPサーバー側の環境変数(issuerやJWKSの参照)に渡します。
Issuer : https://cognito-idp.<region>.amazonaws.com/<userPoolId> 認可 : https://<domain>.auth.<region>.amazoncognito.com/oauth2/authorize トークン: https://<domain>.auth.<region>.amazoncognito.com/oauth2/token JWKS : https://cognito-idp.<region>.amazonaws.com/<userPoolId>/.well-known/jwks.json
※MCPのOAuthは動的クライアント登録(DCR / RFC 7591)を使用する場面がありますが、Cognitoは現状DCRに非対応です。ただし、Claudeのカスタムコネクタは詳細設定でClient ID / Secretを手入力でき、事前登録したクライアントを使えるため、DCRなしでも成立します。今回はこの方式を採りました。
DCRと事前登録クライアントの扱いについては、以下の公式仕様をご参照ください。
4. データ保存(S3)とIAMタスクロール
メモの保存先となるS3バケットと、コンテナがS3へアクセスするためのIAMタスクロールを用意しました。コンテナ内の boto3 は、このタスクロールの権限でS3を読み書きします。
付与する権限は、メモの読み書きに必要な最小限に絞っています。
- Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource: "arn:aws:s3:::<バケット名>/memos/*" # memos/ 配下に限定
- Effect: Allow
Action:
- s3:ListBucket
Resource: "arn:aws:s3:::<バケット名>"
ここでハマりやすいのが s3:ListBucket です。
S3では、存在しないキーへの GetObject は、ListBucket 権限がないと 403 AccessDenied、あると 404 NoSuchKey を返すという仕様があります。サーバーは「初回(オブジェクト未作成)」を NoSuchKey で判定して空リストにするため、ListBucket がないと初回アクセスで 403 になって落ちてしまいます。そのためバケットに対する ListBucket を付与しています。
これでAWS環境が整いました。いよいよClaudeから動かしてみます。
Claudeで試してみた
準備が整ったので、Claudeの個人カスタムコネクタとして登録し、実際にメモ操作を試していきます。
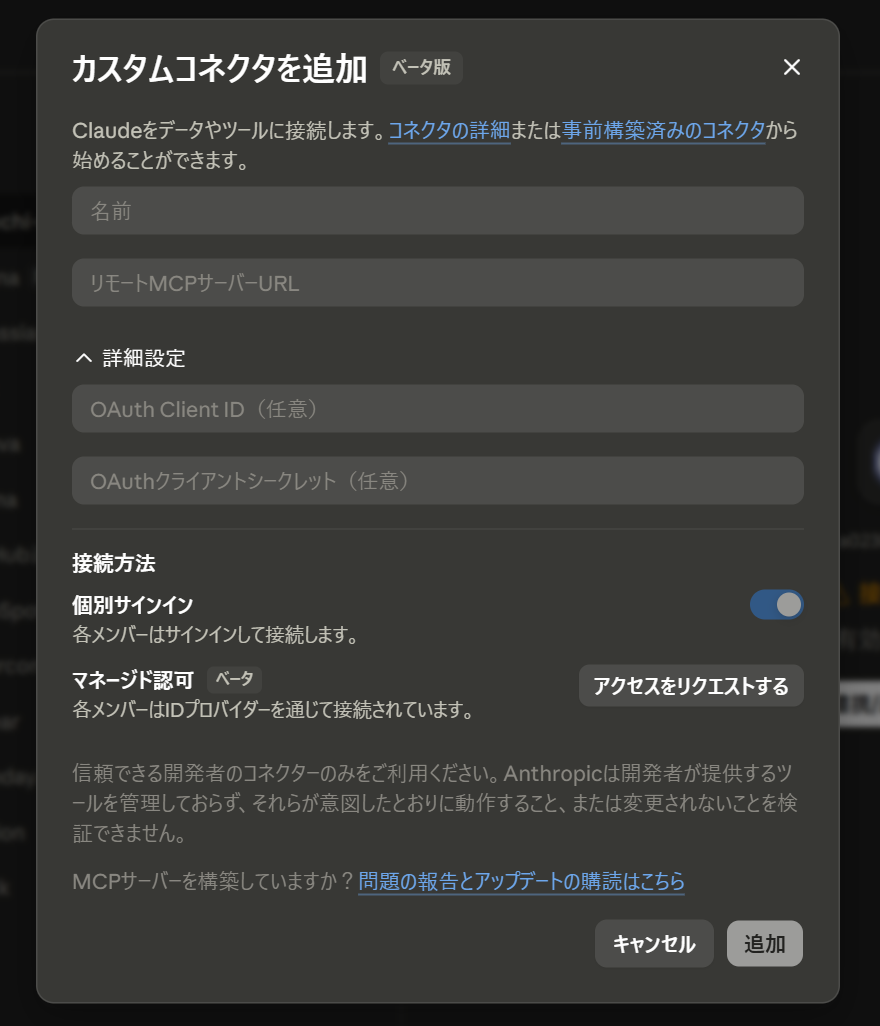
1. カスタムコネクタに登録する
Claude(デスクトップ版)の カスタマイズ → コネクタから、名前とURL(払い出されたHTTPS URLの末尾に /mcp を付けたもの)を入力します。さらに 詳細設定に、Cognitoで発行したClient ID / Client Secretを入力します。これが「事前登録クライアント」として機能し、DCR非対応のCognitoでも接続できます。
2. OAuthログイン(Cognito Hosted UI)
コネクタを追加して Connect すると、CognitoのHosted UIにリダイレクトされます。
ログインすると認可コードがトークンに交換され、以降のツール呼び出しにアクセストークン(Bearer)が付与されます。
認証フローを整理すると、次のように進みます。
1. Claude → /mcp : 401 + 保護リソースメタデータ(issuer=Cognito) を返す 2. Claude : Cognito の OIDC メタデータから authorize/token を発見 3. ブラウザ → Hosted UI : ★ここでログイン★(Cognito マネージドフロント) 4. Cognito → Claude : 認可コード → トークンに交換 5. Claude → /mcp : Bearer 付きで呼ぶ → サーバーが JWT を検証
3. メモを操作してみる
ログイン後に、自然文でメモ操作を依頼します。
全ツールを呼び出して結果を確認します。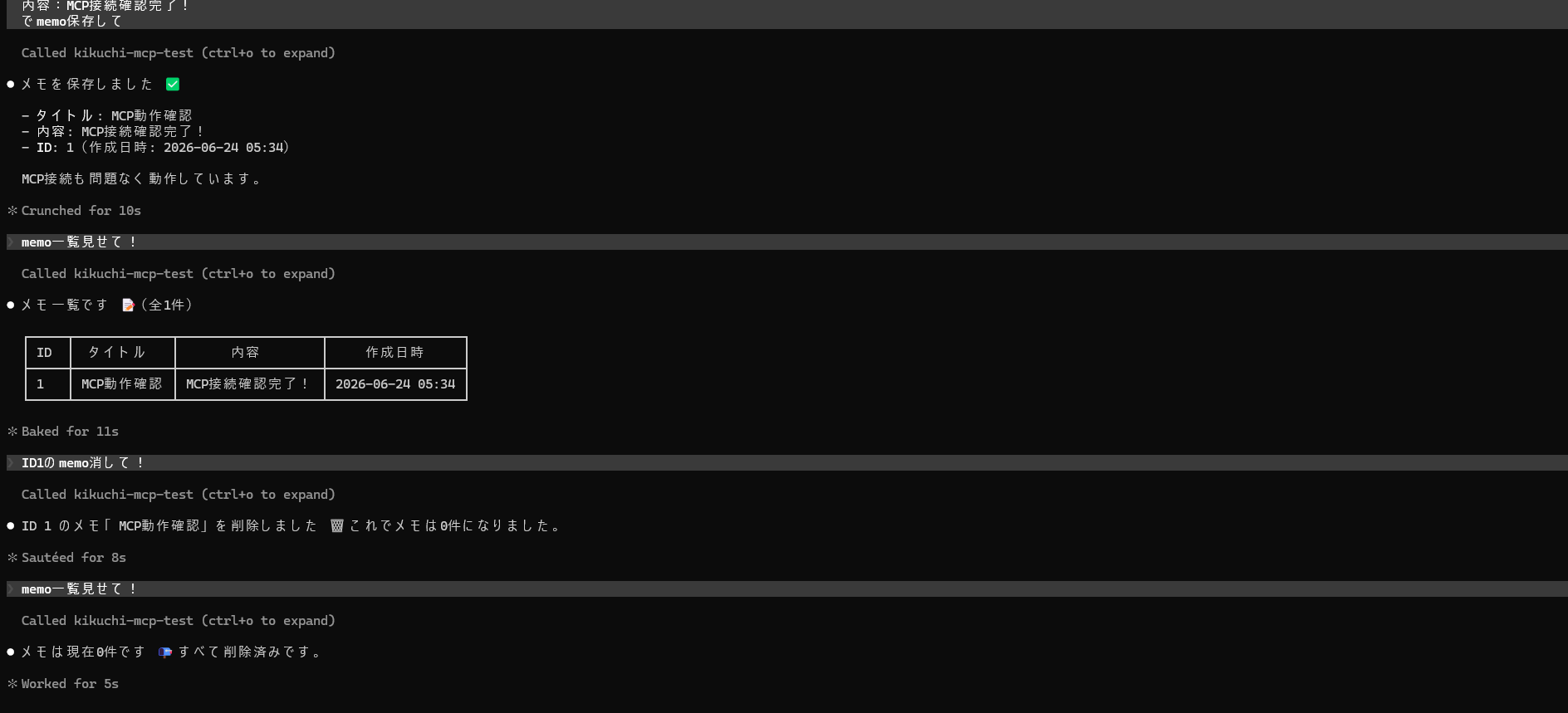
無事 add_memo / list_memos / delete_memo すべてが動作してくれました!
検証結果
今回の検証で分かったことを整理します。
- 役割分担が明確:ログインはCognito(AS)、トークン検証はMCPサーバー(RS)という分担が、そのまま実装とAWS環境の構成に対応していて、見通しよく組めました。
- ユーザーごとのデータ分離が機能した:トークンの
subをキーにS3へ保存することで、ログインユーザーごとにメモが分離されることを確認できました。 - 基盤の省力化と、アプリ側の作り込みは両立が必要:ECS Express Modeで基盤構築は大きく省力化できる一方、
stateless_httpや/healthのように、「ロードバランサー配下で動く」前提のアプリ側の考慮は引き続き必要だと実感しました。
まとめ
今回は、MCPの中身を知る手始めに自作したMCPサーバーを、Amazon ECS(Express Mode)でリモート公開し、Amazon Cognitoの認証付きでClaudeから利用するまでを検証しました。まとめると、次の通りです。
ポイントまとめ
- MCPサーバー:トランスポートをStreamable HTTPに切り替え、Cognito発行のJWTを検証するリソースサーバーにするだけで、ツール本体はほぼそのままリモート化できる。
- AWS環境:ECS Express Modeが、VPC・ロードバランサー・Fargateサービス・オートスケールを自動構成。認証はCognito、保存はS3+最小権限のIAMタスクロールで分担する。
- テスト:個人カスタムコネクタに登録し、OAuthログイン経由で
add_memo/list_memos/delete_memoがユーザーごとに分離されたデータに対して動作した。
「基盤はマネージドに任せ、アプリは認証検証とデータ設計に集中する」という分担が、リモートMCPをすっきり組むコツだと感じました。
引き続き、AI関連の検証を行い、最新情報を追いかけていこうと思います。
もし「このサービスについて知りたい」「AWS環境の構築、移行」などのリクエストがございましたら、弊社お問い合わせフォームまでお気軽にご連絡ください。 複雑な内容に関するお問い合わせの場合には直接営業からご連絡を差し上げます。 また、よろしければ以下のリンクもご覧ください!
<QES関連ソリューション/ブログ>

※Amazon Web Services、"Powered by Amazon Web Services"ロゴ、およびブログで使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※Claude、Claude Code、Anthropic、およびブログで使用されるその他のAnthropicの商標は、米国その他の諸国における、Anthropic PBC またはその関連会社の商標です。

