記事公開日
最終更新日
Power Apps / Power Automate で大量データを扱うときのポイント(後編)

こんにちは。システムソリューション営業本部の吾妻です。
後編の今回の記事では、Power Automateから大量データを扱うときに気を付けるべきポイントをご紹介します。
Power Apps → Power Automate
Power Automateで大量データを扱う場合でも、基本的には、前編の記事でご紹介したキャンバスアプリの場合と同様に、できるだけ取得するデータの数を絞って処理を軽くしてあげる必要があります。例えば、各レコードに固有のIDで処理対象のレコードを特定できる場合には、「行を一覧にする」アクションではなく「ID で行を取得する」アクションを利用して、単一のレコードのみを取得するようにします。しかしながら、ロジックを組むうえで、どうしても複数のレコードを対象に一括処理を行わなければならない状況がしばしば出てきます。このような場合には、SharePointやDataverseからデータを取得するためのフィルタリング条件を考慮して実装していくことが重要かと思います。幸い、Power Automateでは、 OData クエリを利用したフィルタリングがサポートされているので、これを活用していきます。ただ、Power Automateそのものの機能というよりは、"Power Automate外"との連携に関わる部分なので、どうしても公式ドキュメントの内容が薄くなっている部分でもあります。ですので、技術的な背景や具体的な実装方法を交えてご紹介していきたいと思います。データソースには、一旦SharePointとDataverseを利用して、差異を見ていきます。
OData?
Odataとは、Open Data Protocolの略で、REST APIの上でCRUD処理を行うためのプロトコルを定義している規格です。「REST APIの上で」というのは、REST APIだけだと不足している部分をきちんと定義して補っているイメージです。
ここで、従業員を管理するDBテーブルを持つWebシステムを例に考えてみます。ユーザー情報を一覧取得するエンドポイントは以下のようになるかと思います。
URL:
|
結果: { |
REST APIにおいて、すべてのリソースはURIで一意の識別子で識別されるという原則になっています。そのため、特定のユーザーを1人指定してユーザー情報を取得するためには、先程のユーザー一覧を取得するエンドポイントの後ろにユーザーのIDを階層的に繋げた、以下のようなエンドポイントにアクセスすることになります。
URL:
|
結果: { |
ここからが問題になるのですが、次にユーザーを検索するエンドポイントを用意したいと思います。IDではなくユーザー名などの別の項目から検索して、かつ、複数ユーザーの結果が返ってくる可能性がある、という点が先程のような「取得」処理とは異なります。REST APIにおいて、リソースへの処理はHTTPメソッドと対応付けられているので、先程の「取得」処理の場合はGETメソッドで問題ありませんでした。しかし「検索」処理についてはHTTPメソッドが定義されていないため、実装する人によって以下のようないくつかの方法に分かれてしまいます。実際には、パラメータを受け取った後での検索方法(完全一致、前方一致、…)や結果の取得件数(上限値、ページ/ページごとの件数)といったパラメータも必要になるので、それらもリクエストに含めさせるか、APIの制約として呼び出し側に受け入れさせるしかなくなります。GETメソッドを利用する場合、クエリ文字列の長さの制約も気になります。
1: GETメソッドにクエリ文字列を追加
|
2: POSTメソッドにリクエスト本文を追加 |
また、検索結果としては「取得」処理と同様のJSON文字列が返ってくることになりますが、検索処理を利用する場面を考えてみると、必ずしもすべてのフィールドを返してもらう必要はなく、以下のように表示名とメールアドレスだけ返してもらえば済む場面もあるかもしれません(「過剰な取得」を避けるため)。
結果: { |
このように、REST APIだけだと実装がカチッと決まらなかったり、無駄な通信コストが発生してしまったりするといった課題があり、これらを解決するために定義された規格が、ODataです(検索での課題に関していえば、GraphQLのような別の解決策もあります)。
Power Automateでは(というよりもDataverseコネクタ・SharePointコネクタでは)、ODataに定義された関数・演算子のすべてがサポートされているわけではないのですが、いくつかについては利用できるようになっているので、次項以降で具体的にどれが利用できてどれが利用できないのか、ご紹介します。
クラウドフローでのODataクエリ
個々のサービス(Dataverse、SharePoint)でどのようなODataクエリを利用できるか記載されているドキュメントはあるのですが、Power Automateを経由した際にも同様に利用できるのか記載されているドキュメントは見つからなかったため、以下のようなクラウドフローを用意して、実際に呼び出してみました。
①SharePoint
| 「手動でフローをトリガーします」トリガー |
| ↓ |
(SharePoint)「複数の項目の取得」アクション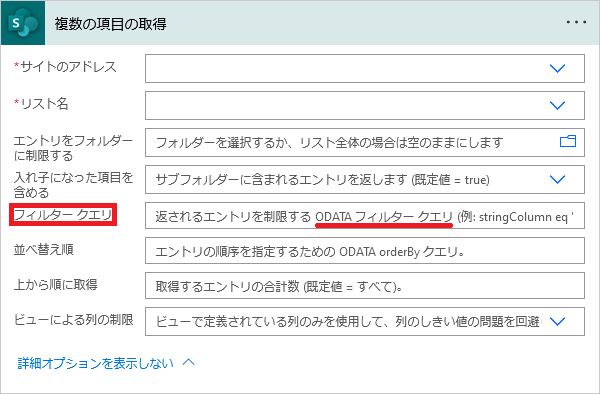 「フィルタークエリ」パラメータにODataクエリを入力しておく |
②Dataverse
| 「手動でフローをトリガーします」トリガー |
| ↓ |
(Dataverse)「行を一覧にする」アクション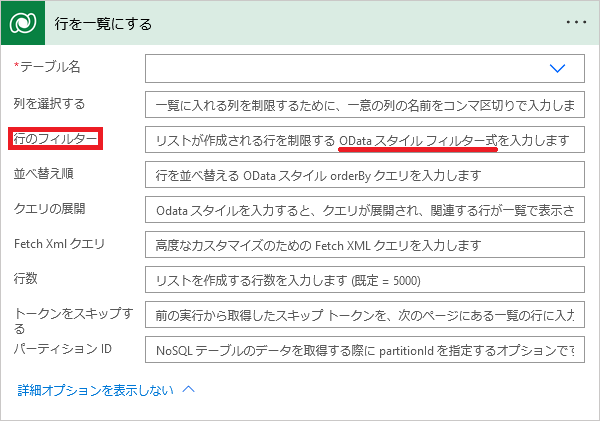 「行のフィルター」パラメータにODataクエリを入力しておく |
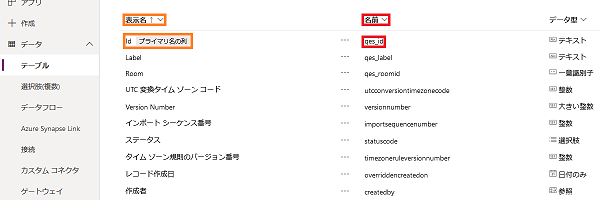
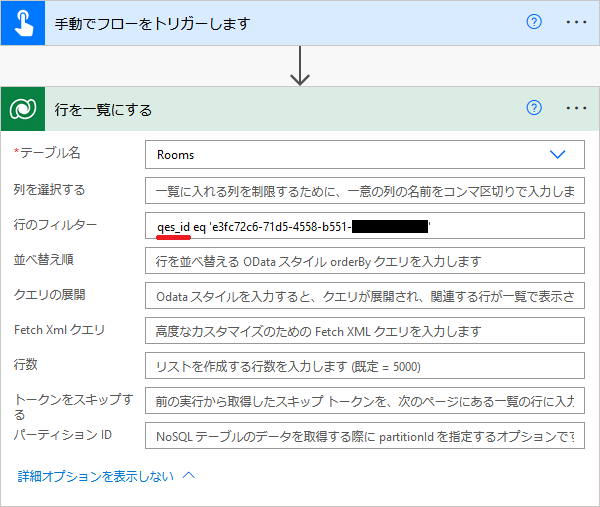
Dataverseの「行を一覧にする」アクションでODataクエリを記述する際には、列名として「表示名」ではなく「名前」の方を指定します。以下のテーブルの例だと、 Id ではなく qes_id を指定しています。
 |
 |
きちんとフィルタリングされているかどうか確認するためには、「未加工出力の表示」をクリックしてアクションの結果を表示します。
この際、クラウドフローの結果をPower Appsのメーカーポータル( make.powerapps.com )から開いていると「未加工出力の表示」が表示されないようなので、Power Automateのサイト( japan.flow.microsoft.com )から開いてあげる必要があります(いま気づいた)。
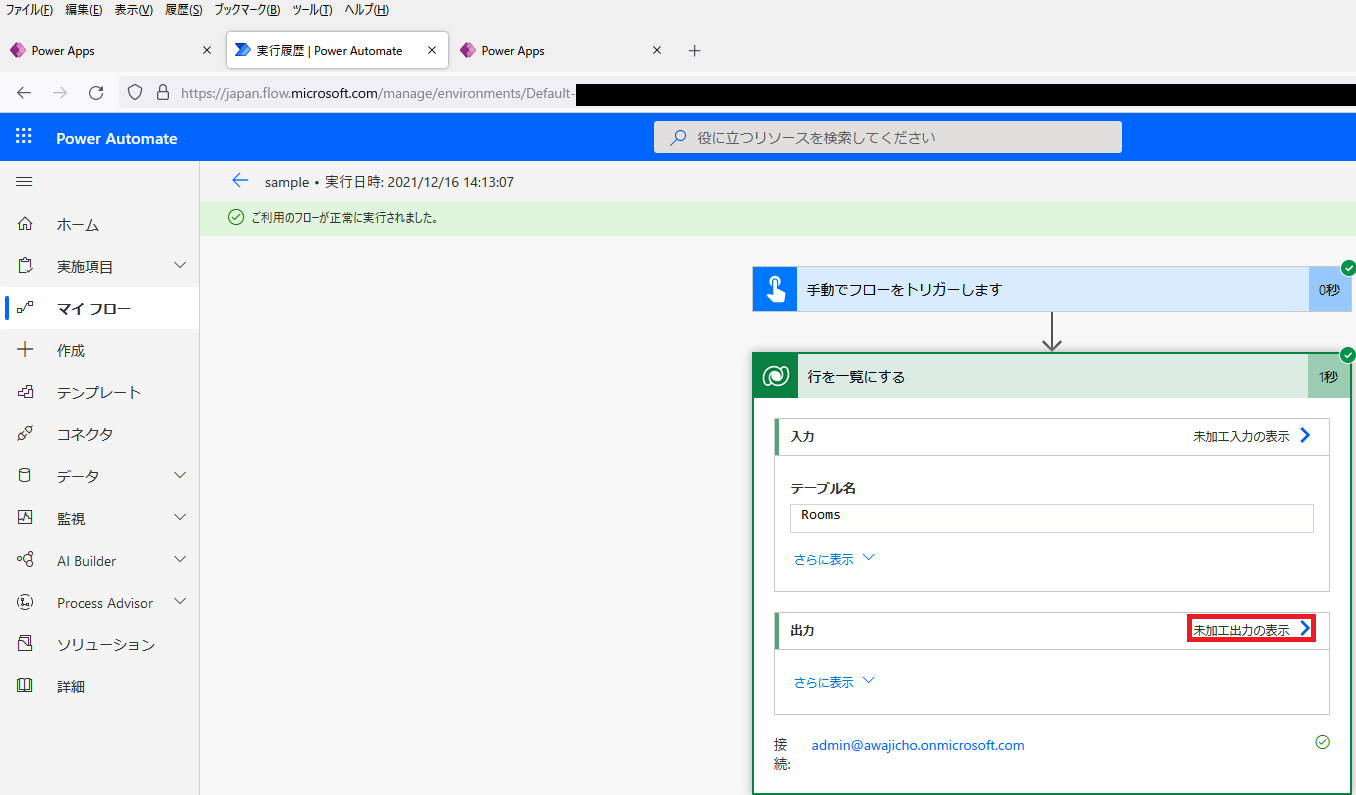
ODataの規格で定義されている演算子・関数の各々について、クラウドフローで利用できるか実際に試してみた結果を以下の表に示します。
| 区分 | 種類 | 項目 | SharePoint | Dataverse |
| 演算子 | 比較演算子 | eq | ○ | ○ |
| ne | ○ | ○ | ||
| gt | ○ | ○ | ||
| ge | ○ | ○ | ||
| lt | ○ | ○ | ||
| le | ○ | ○ | ||
| has | × | × | ||
| in | × | × | ||
| 論理演算子 | and | ○ | ○ | |
| or | ○ | ○ | ||
| not | ○ | ○ | ||
| 算術演算子 | add | × | × | |
| sub | × | × | ||
| mul | × | × | ||
| div | × | × | ||
| divby | × | × | ||
| mod | × | × | ||
| グルーピング演算子 | ( ) | ○ | ○ | |
| 関数 | 文字列/コレクション | concat | × | × |
| contains | × | ○ | ||
| endswith | × | ○ | ||
| indexof | × | × | ||
| length | × | × | ||
| startswith | ○ | ○ | ||
| substring | × | × | ||
| コレクション | hassubset | × | × | |
| hassubsequence | × | × | ||
| 文字列 | matchesPattern | × | × | |
| tolower | × | × | ||
| toupper | × | × | ||
| trim | × | × | ||
| substringof ※1 | ○ | × | ||
| 日時 | day ※2 | × | × | |
| date | × | × | ||
| fractionalseconds | × | × | ||
| hour | × | × | ||
| maxdatetime | × | × | ||
| mindatetime | × | × | ||
| minute | × | × | ||
| month | × | × | ||
| now | × | × | ||
| second | × | × | ||
| time | × | × | ||
| totaloffsetminutes | × | × | ||
| totalseconds | × | × | ||
| year | × | × | ||
| 算術 | ceiling | × | × | |
| floor | × | × | ||
| round | × | × | ||
| 型 | cast | × | × | |
| isof | × | × | ||
| isof | × | × | ||
| 地理 | geo.distance | × | × | |
| geo.intersects | × | × | ||
| geo.length | × | × | ||
| 条件 | case | × | × |
※2 …SharePoint REST サービスでサポートされる OData クエリ演算子だが、Power Automateでは利用できなかった関数(400エラー)
関数に関しては、ODataクエリの中で何らかの処理をするのではなく、Power Automateのアクションの側で予め処理をさせておいてから値をクエリで利用するのが前提とされているようです。例えば、ODataクエリの中でODataのadd関数を利用して 1 add 2 を計算するのではなく、Power Automateのadd関数で予め add(1, 2) と計算しておいてODataクエリの中で計算結果の 3 を利用することを前提としているので、OData側の関数は未実装のままとなっているのだと考えられます。また、SharePointで startswith は使えるものの endswith は使えない、というのは見落としがちな気がします。
まとめ
「Power Apps / Power Automate で大量データを扱うときのポイント」として、 前編 ではPower Appsのキャンバスアプリから、後編の本記事ではPower Automateのクラウドフローから、それぞれ大量データにアクセスして処理を行うためのポイントについてご紹介しました。従業員マスタやリソースマスタといったマスタデータの場合はそこまで極端にデータ量が大きくなることは少ないかもしれませんが、ログデータや商品取引のようなトランザクションデータの場合はあっという間にデータ量が増大してしまい、キャンバスアプリやクラウドフローのUXが悪くなってしまうことが想定されます。今回ご紹介したようなポイントに少しだけ気を配ってあげることで、皆さんのアプリケーションが改善されることがあるかもしれませんので、頭の片隅に置いておいていただければと思います。
また、こうした諸課題について困ったときに相談できるサポート窓口と、共有されているアプリケーションを選んで若干カスタマイズを加えて導入できるアプリカタログを組み合わせた Power Apps サポートサービス「サポート&アプリカタログサービス」の提供を開始いたしました。開発コストを削減しながらPower Platformを活用できる便利なサービスになっていますので、まずはお気軽にお問い合わせください。

他にも、Power Platform関連の記事があります。


このブログで参照されている、Microsoft、Windows、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
このブログで参照されている、Android、Google Maps、その他のGoogle製品およびサービスは、米国およびその他の国におけるGoogle LLCの商標または登録商標です。

