記事公開日
最終更新日
Power Apps / Power Automateを使ってテキスト抽出する方法 (2021年版)

こんにちは。システムソリューション営業本部の吾妻です。
みなさんは、注文書や申請書といった「帳票」に記載された内容をデータベースに転記するような業務をお持ちでしょうか?
手入力で転記すると、入力ミスの可能性が高く、作業時間も掛かってしまうため、できる限り省力化・自動化したいという要望が多いテーマだと思います。
従来低コストなOCRといえば、TesseractのようなOCRエンジンをラッパー経由で呼び出すプログラムを開発して実現することが多かったと思います。
ローカルで処理が完結するというメリットの一方で、それほど精度が高くなく、プログラム開発が必要なため敷居が高かったといえます。
ところが、数年前からクラウド上でOCR技術を利用できるサービスが各種ベンダーから公開されるようになりました。
例えばMicrosoftでは、Cognitive Service(Project Oxford)のCustom VisionとしてAPIを公開しています。
クラウドのOCRサービスを利用する場合、ユーザーが増えるとともに学習データが増えるので、高い認識精度が得られるメリットがあります。しかしながら、OCR処理に関するプログラム開発は不要になったものの、前処理を行ったりAPIとの連携を行ったりする必要があるために、まだプログラム開発が必要な状況でした。
そこで今回ご紹介するのが、ソースコードを書くことなくアプリ開発できるローコードツール「 Power Apps 」に含まれている、「フォーム処理 (Form processing) 」というOCR機能です。
もともとローコードツールの一機能として実装されているものなので、元データのアップロードや機械学習モデルのトレーニング、モデルのデプロイ(公開)、モデルを利用したOCRアプリケーションの作成まですべてソースコードを書かずに行うことができます。
本記事では、フォーム処理で給与明細のPDFからテキストを抽出するモデルを作成して、そのモデルを呼び出すPower AppsアプリやPower Automateフローを作成する、という手順で進めていこうと思います。
尚、本記事の内容を試すためには、 Microsoft 365 (Office 365) に付属する Power Apps では利用することができない「プレミアムコンポーネント」を組み込む必要があるため、Microsoft 365 ライセンスの範囲内の Power Apps ではなく、Power Appsの有償ライセンス(またはその評価版)が必要になります。「 Microsoft 365 開発者プログラム」と Power Apps 試用版プランを併用することによって Power Apps 試用環境を用意する手順については、こちらの記事をご覧ください。
(試用環境以外で)準備するもの
- 帳票(同じフォーマットのものを最低6枚)
- 最低5枚を機械学習モデルのトレーニング用に、最低1枚をテスト用に使用します
- PDFファイルを利用する場合、パスワードで保護されている場合は、Microsoft Print to PDFで「印刷」し直すなどして解除しておく必要があります
- 根気
Power Appsで「フォーム処理」を準備する
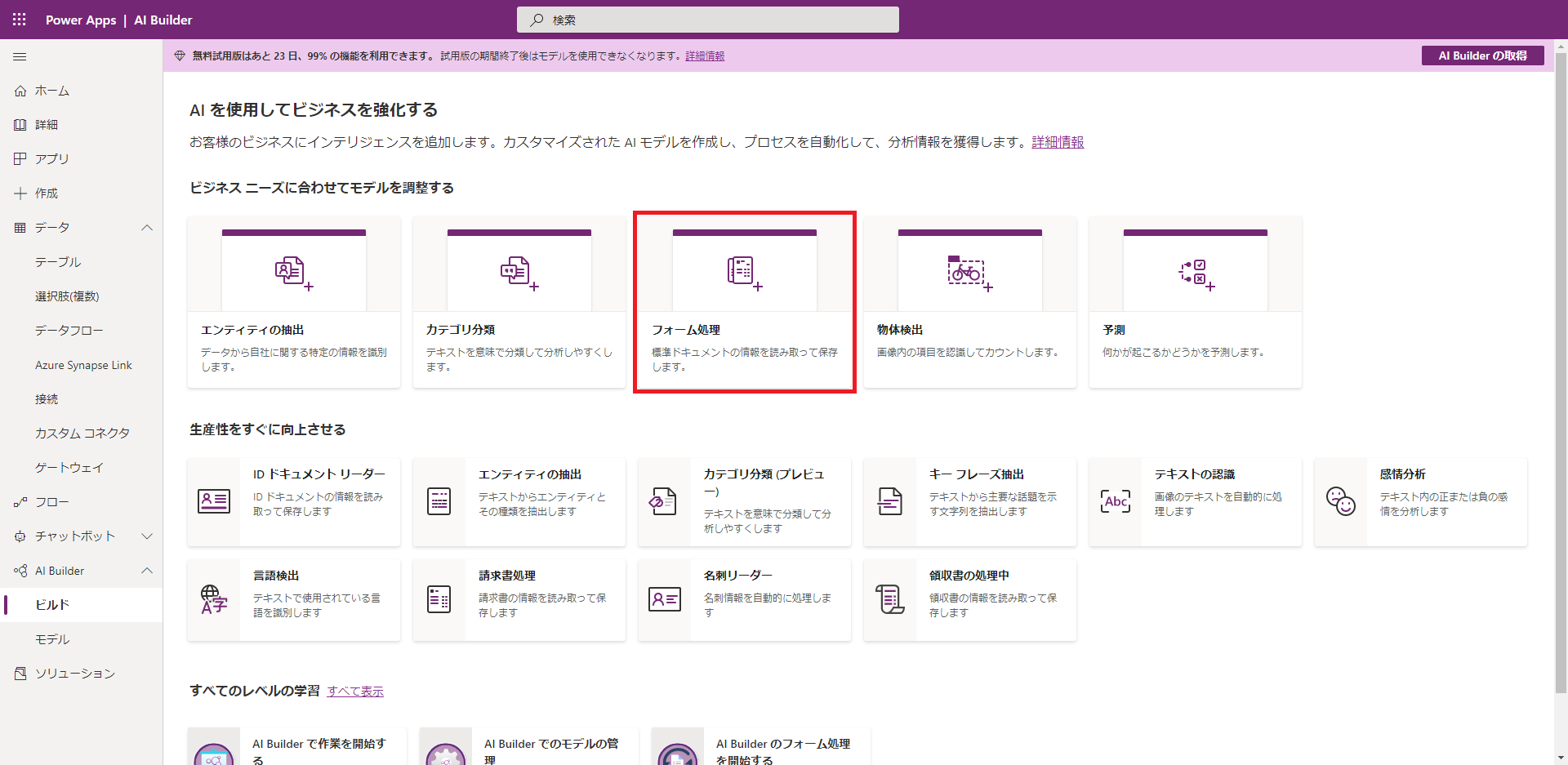
(1) Power Apps メーカーポータルにアクセスして、「AI Builder」>「ビルド」を開き、右側の「フォーム処理」をクリックします。
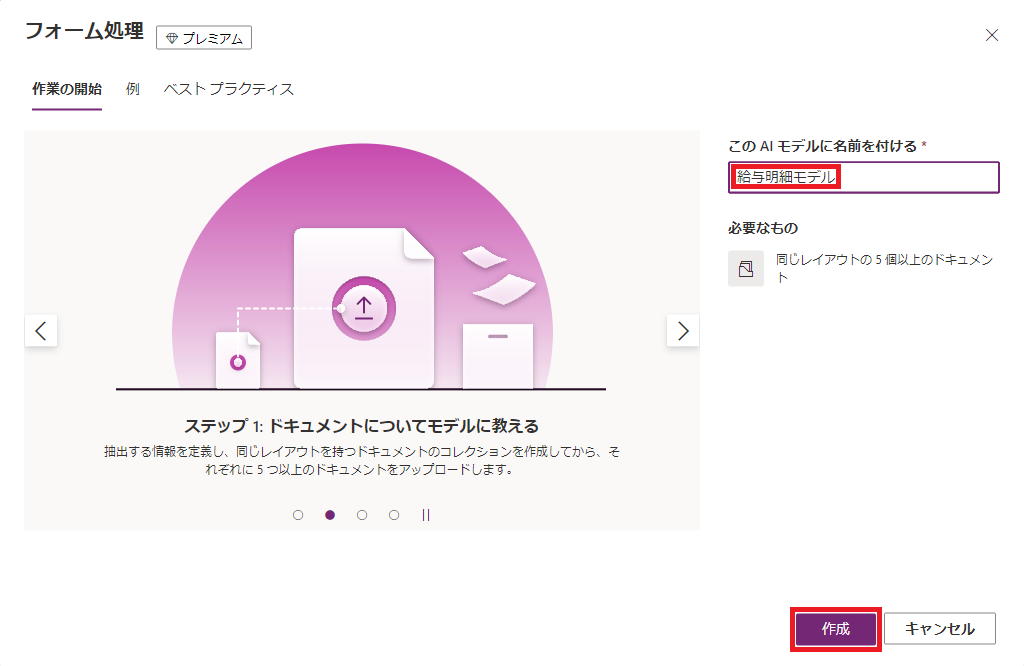
(2) AI モデルの名前をつけて、次へ進みます。
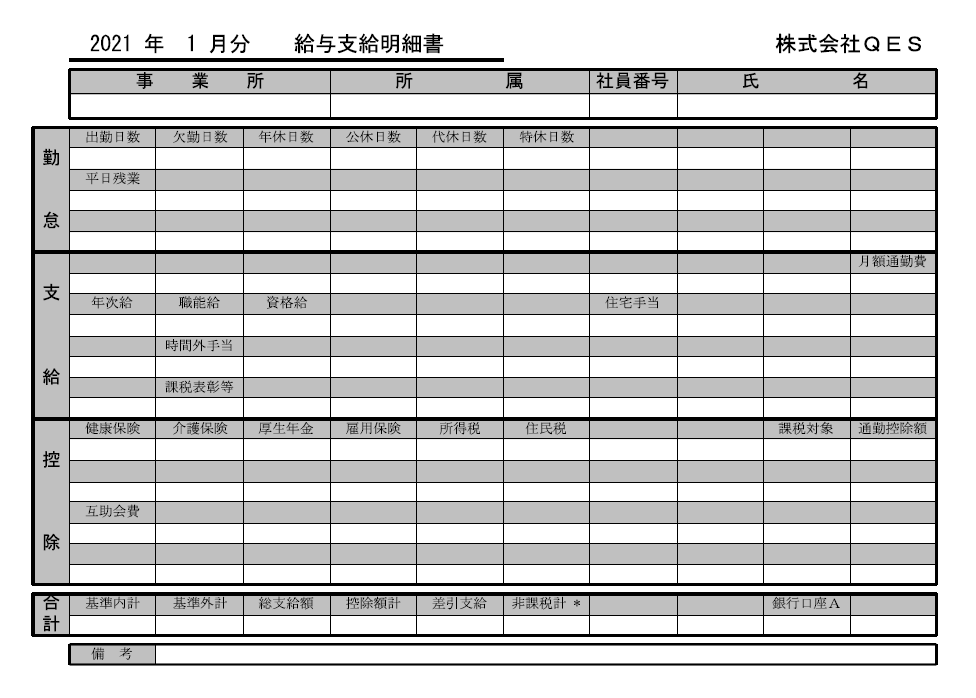
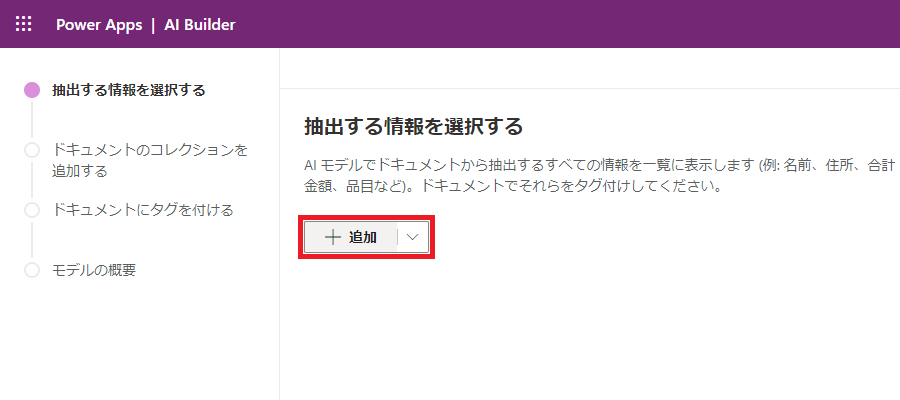
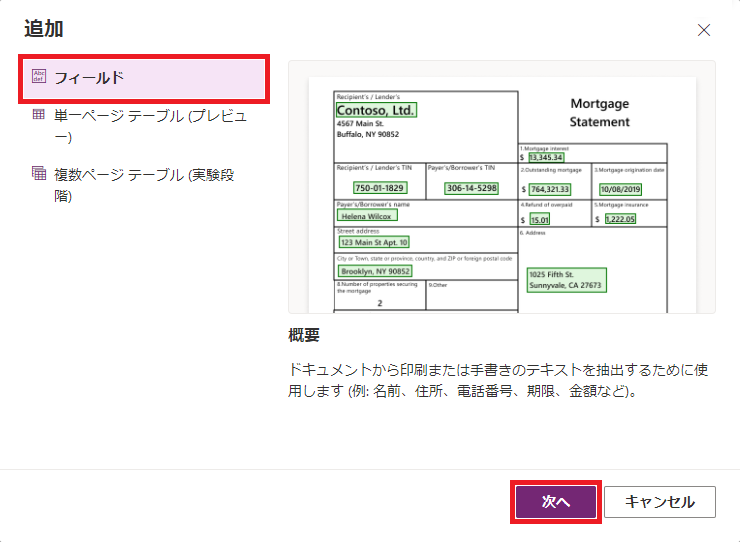
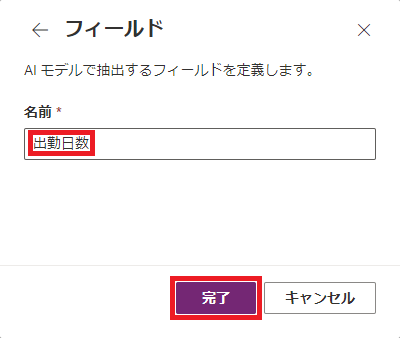
(3) 帳票に記載されているデータ項目(給与明細の例でいう「出勤日数」や「住宅手当」)を定義していきます。
| a) 「追加」をクリック | b) 「フィールド」を選択して「次へ」をクリック | c) 項目名をつけて「完了」をクリック |
 |
 |
 |
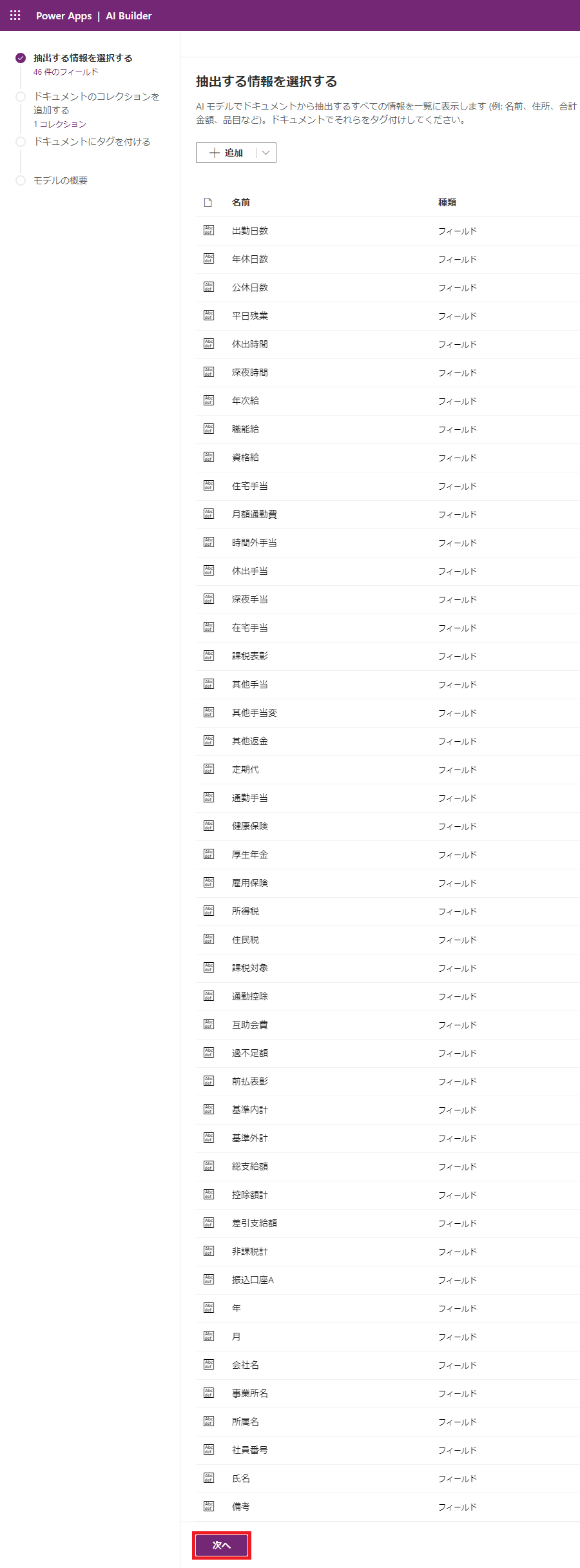
(4) データ項目を必要な分だけ定義したら、次へ進みます。
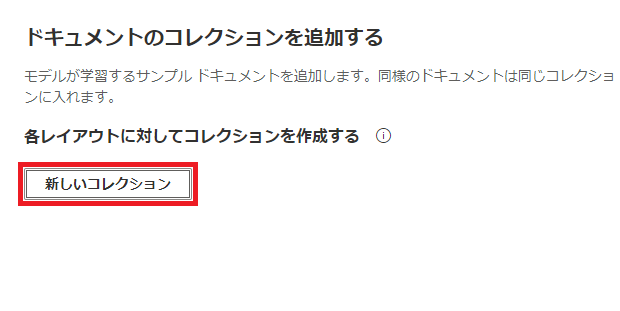
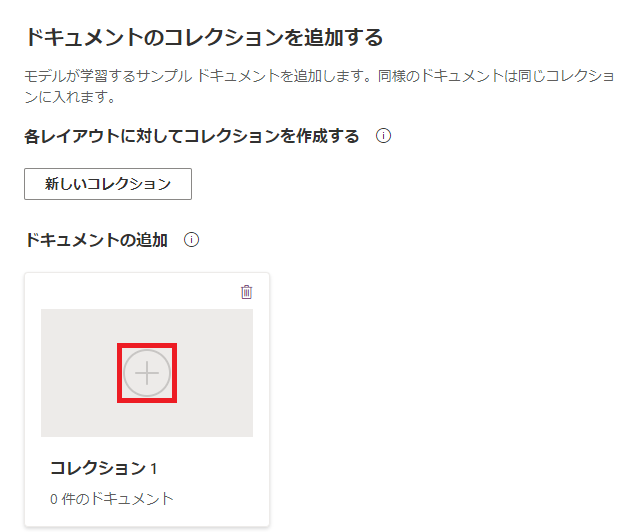
(5) 次に、トレーニング用データの格納先となる「新しいコレクション」を追加して、PDFファイルをアップロードします。
| a) 「新しいコレクション」をクリック | b) 「+」をクリック |
 |
 |
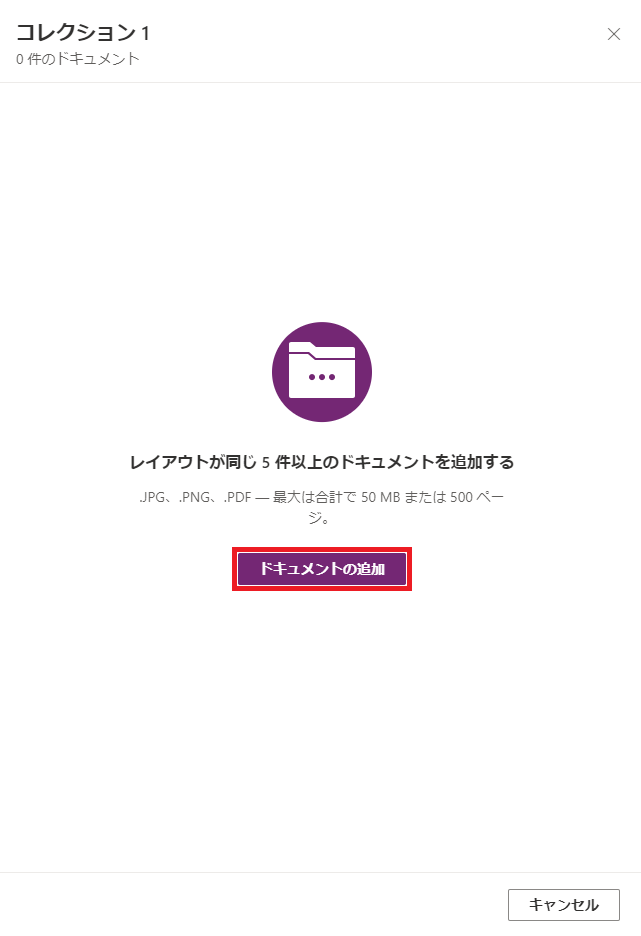
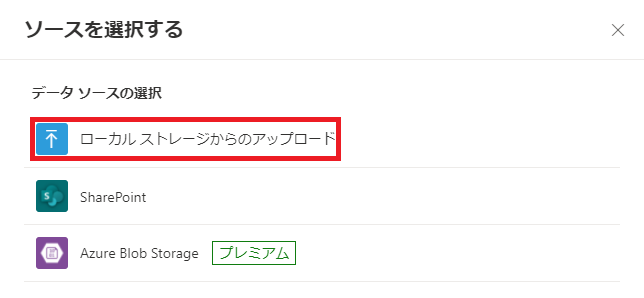
| c) 「ドキュメントの追加」をクリック | d) 「ローカルストレージからのアップロード」をクリック |
 |
 |
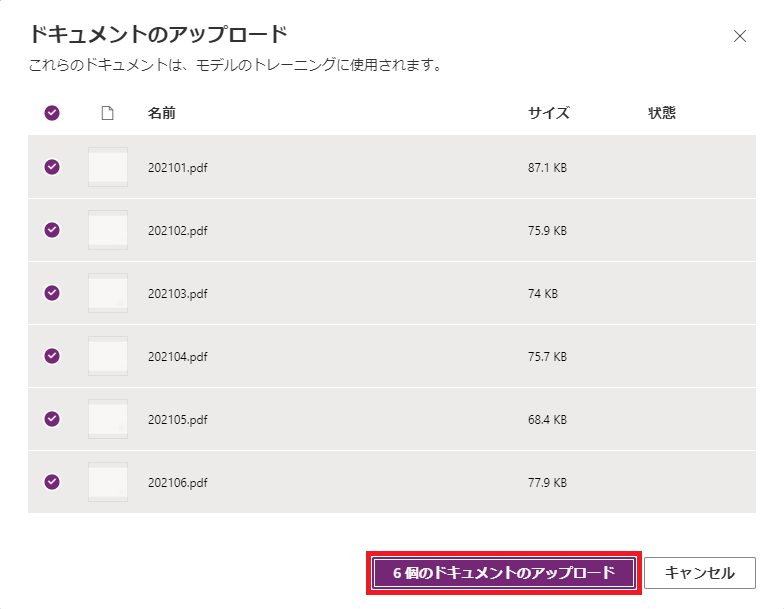
| e) PDFファイルを最低5つ選択して、アップロード | f) 「閉じる」をクリック |
 |
 |
(6) ファイルアップロードが完了したので、アップロードしたPDFファイルをもとに「分析」します。
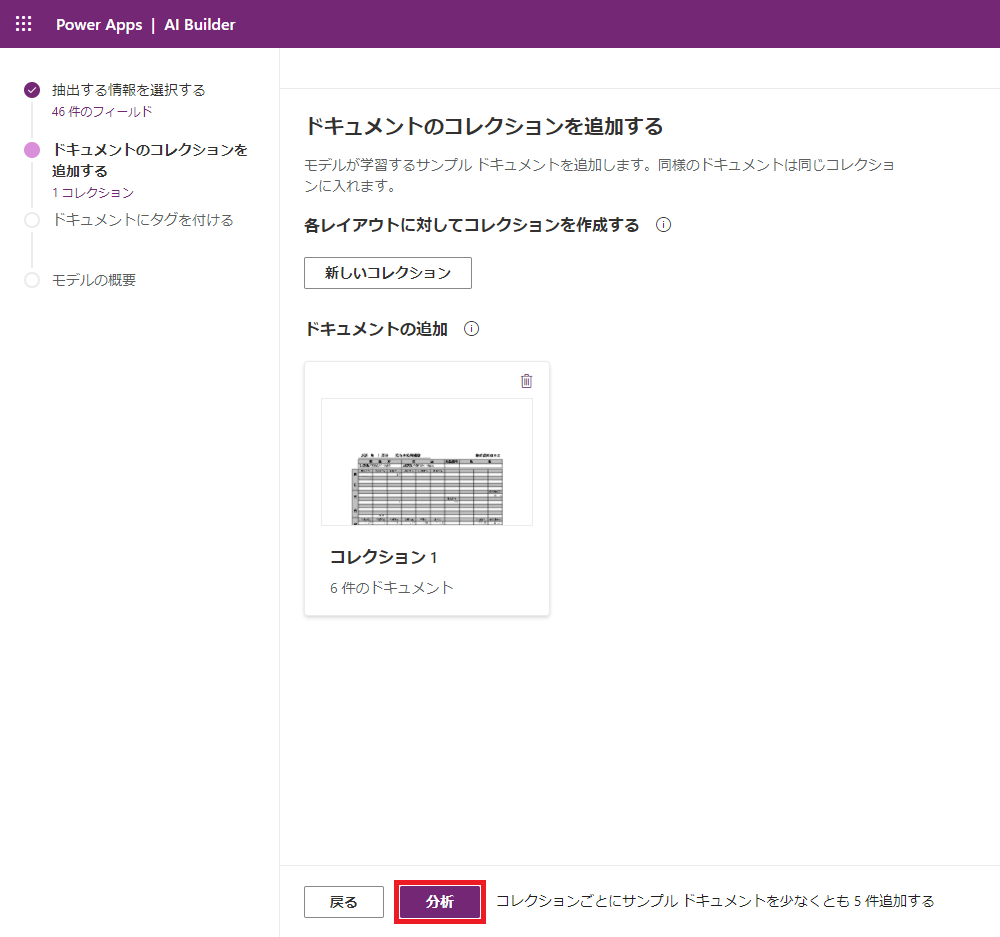 |
 |
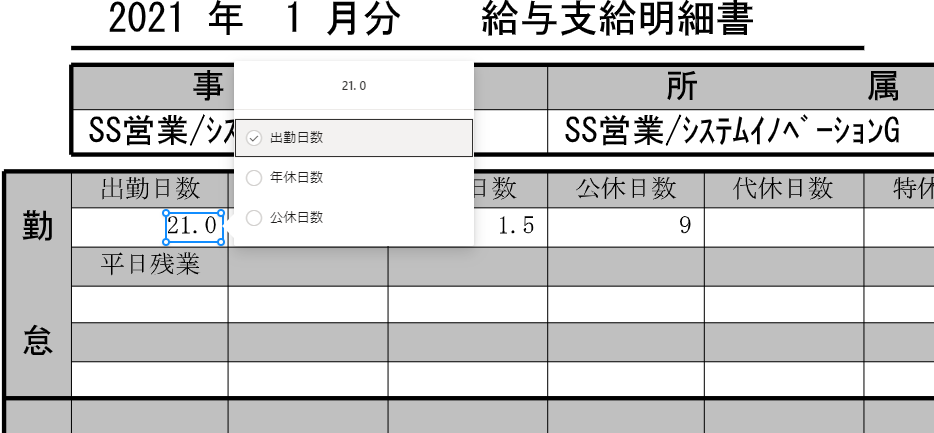
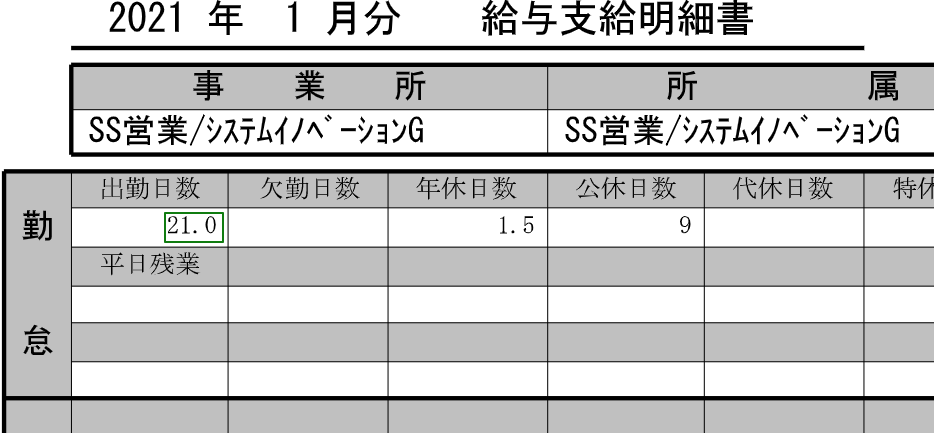
(7) 分析が完了すると、アップロードしたそれぞれのPDFファイルごとに、抽出できた情報に青い矩形が表示されます。この1つ1つに根気強くタグ付けを行っていきます。
※この時注意が必要なのが、当該PDFには出現しないデータ項目がある場合です。例えば給与明細の例でいうと、「年休日数」の項目において、「年休を1回も取得しなかった月」の給与明細には「0日」が出力されるのではなく文字列が何も出力されません。この時、文字列が出力されないので当然 (7) のような青枠も表示されず、タグ付けも行うことができません。そこで、右側のパネルにあるフィールド一覧から、「使用不可」のタグ付けを行う必要があります。
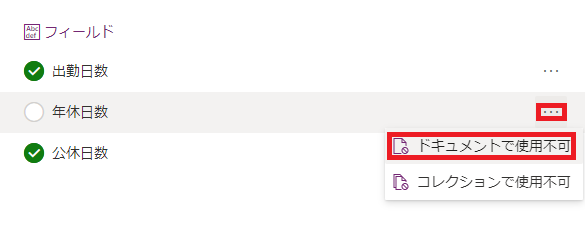
| a) 枠を選択 | b) 右クリックしてタグ付け | c) 枠線が緑色になればOK |
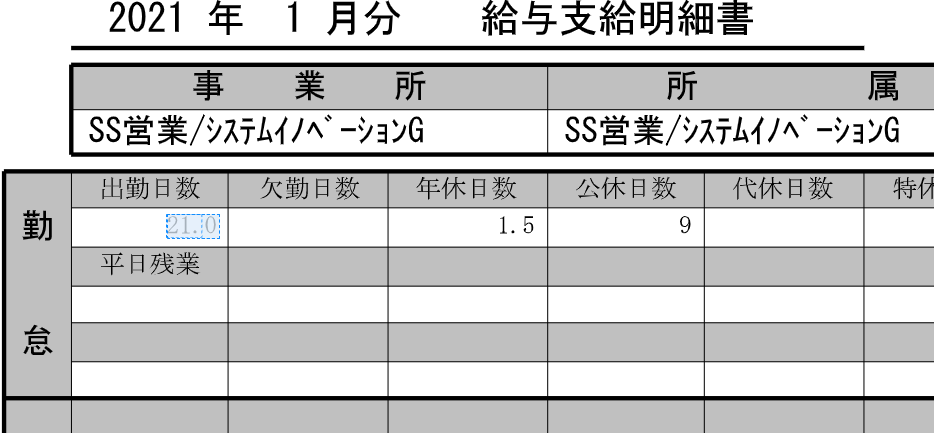 |
 |
 |
※この時注意が必要なのが、当該PDFには出現しないデータ項目がある場合です。例えば給与明細の例でいうと、「年休日数」の項目において、「年休を1回も取得しなかった月」の給与明細には「0日」が出力されるのではなく文字列が何も出力されません。この時、文字列が出力されないので当然 (7) のような青枠も表示されず、タグ付けも行うことができません。そこで、右側のパネルにあるフィールド一覧から、「使用不可」のタグ付けを行う必要があります。
(8) このように、アップロードしたすべてのPDFファイルの、すべてのフィールドに対して、項目名または「使用不可」のタグ付けを済ませると、チェックマークが表示され、次へ進むボタンが有効化されるので、これをクリックします(前の手順で「使用不可」のタグ付けを忘れるといつまで経っても有効化されません)。
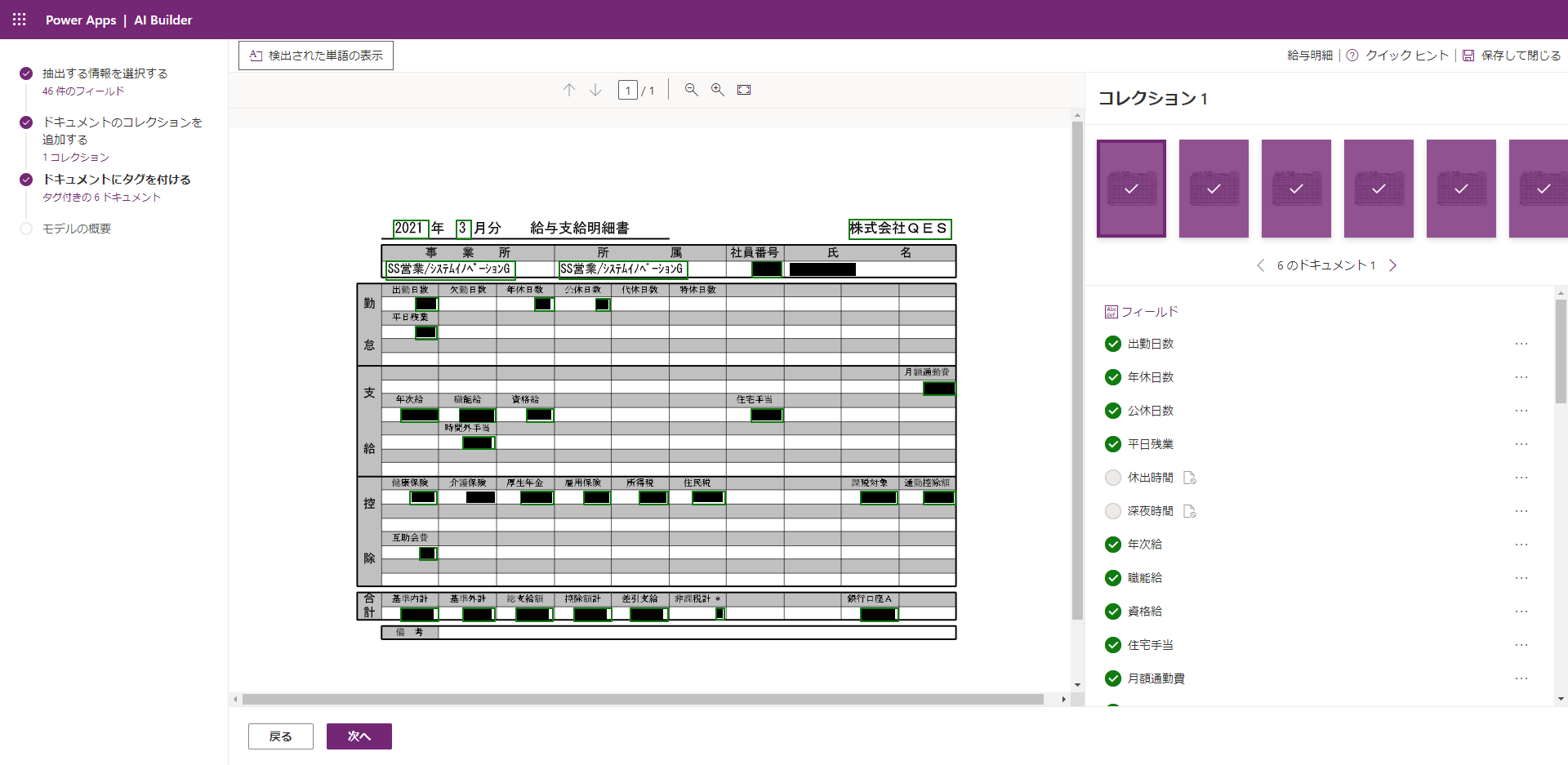
(9) 「トレーニングする」をクリックして先へ進みます。
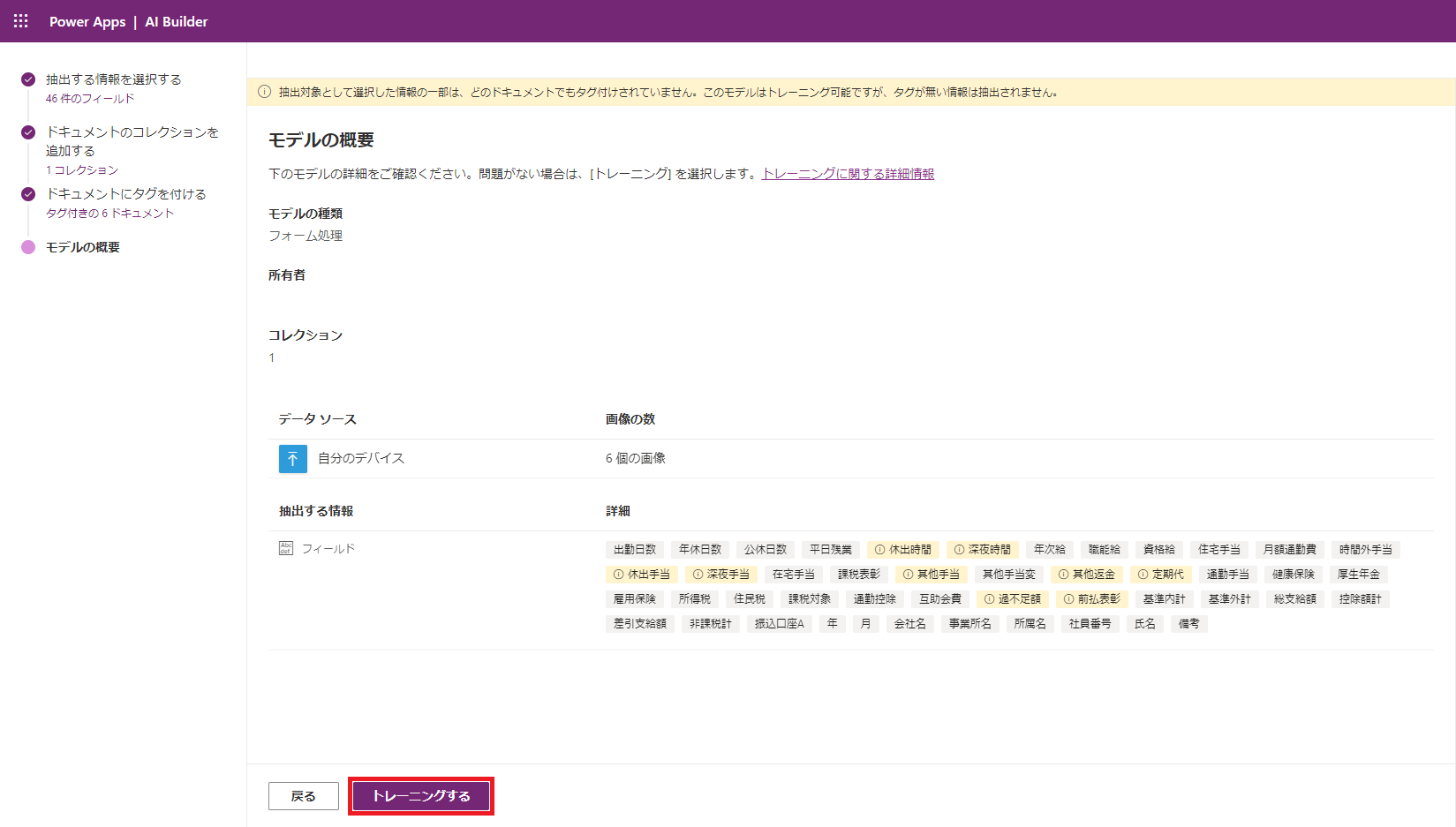
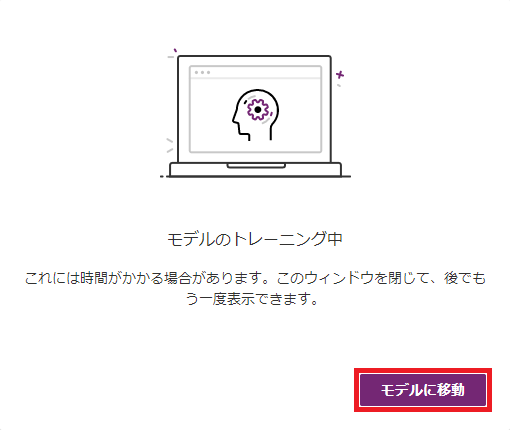
(10) トレーニングが開始されたら、一旦画面を閉じるために「モデルに移動」をクリックします。
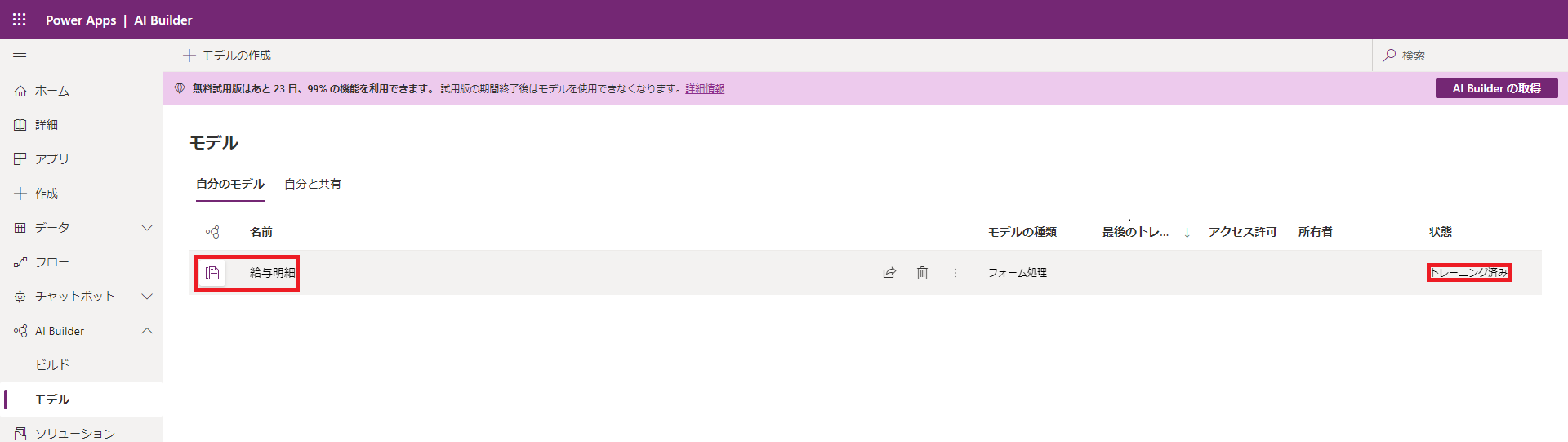
(11) モデルの「状態」が「トレーニング済み」になったら、名前をクリックして、詳細画面を開きます。
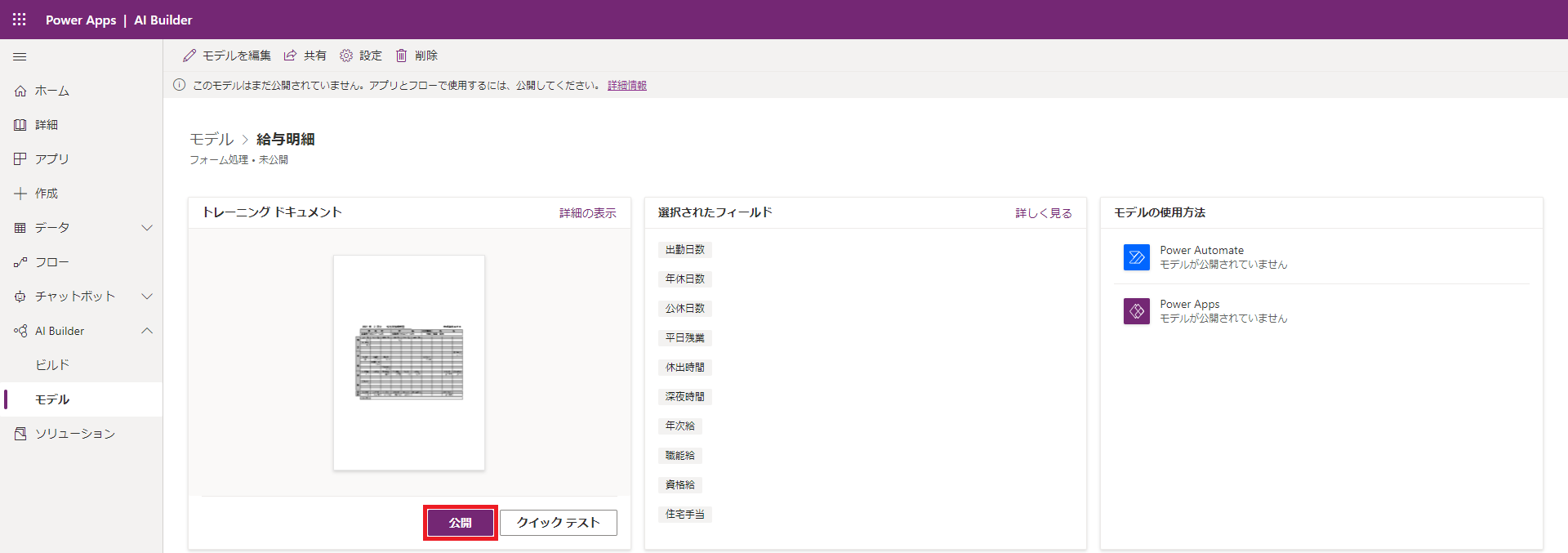
(12) 開いた画面で、モデルを「公開」します。
作成したフォーム処理モデルを利用する
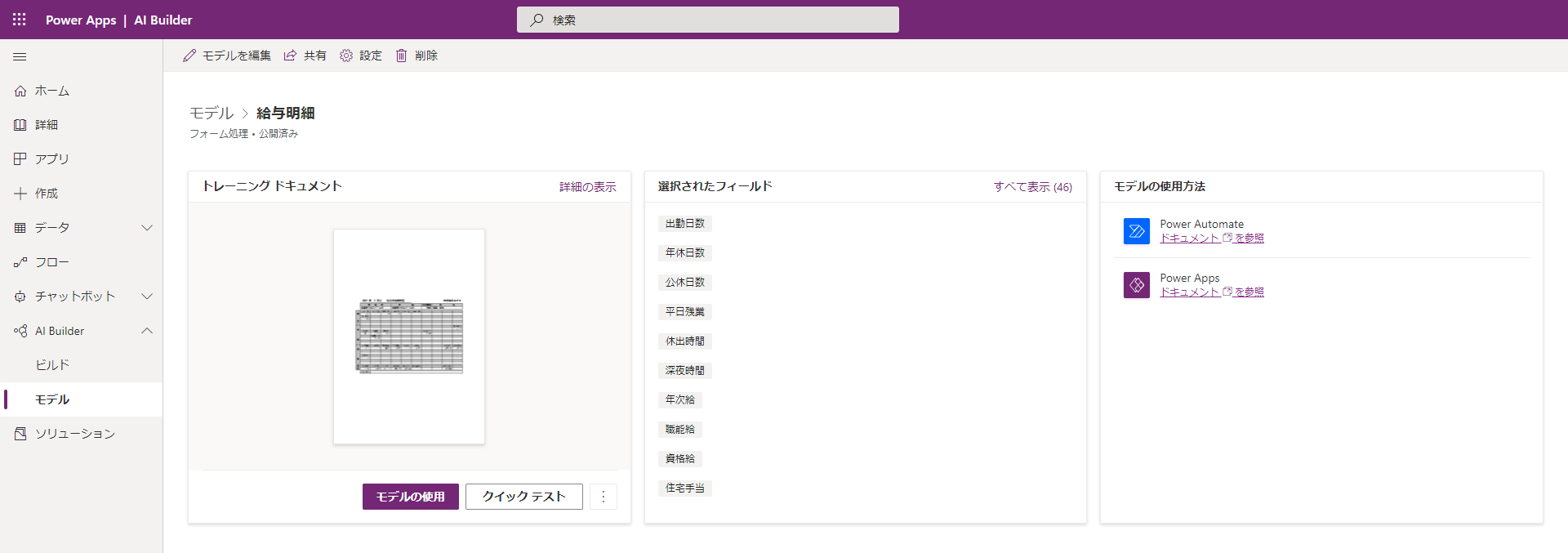
(13) 公開されたモデルの画面には、「モデルの使用」と「クイックテスト」というボタンが表示されます。
(14) まずは「クイックテスト」ボタンを試してみます。トレーニングに使用したのとは別の月の明細の PDF ファイルをテストデータとして、読み取り結果を確認してみます。
| a) テスト用の PDF ファイルを、ドラッグ&ドロップ | b) 読み取り結果と信頼度スコアを確認 |
 |
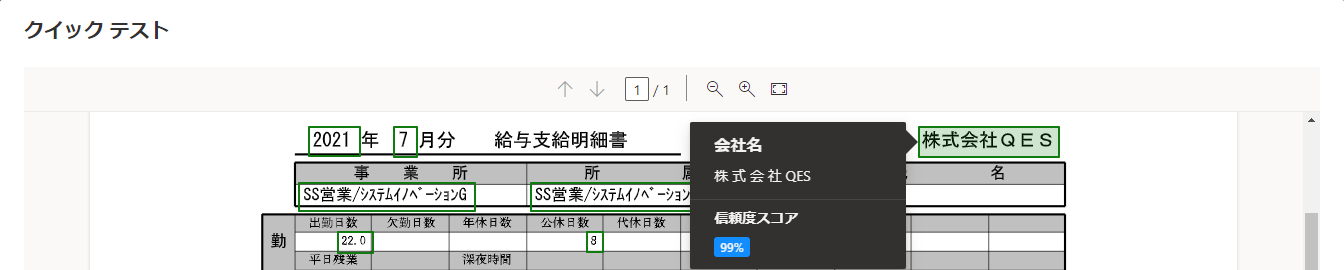 |
(15) 続いて、「モデルの使用」ボタンを試してみます。
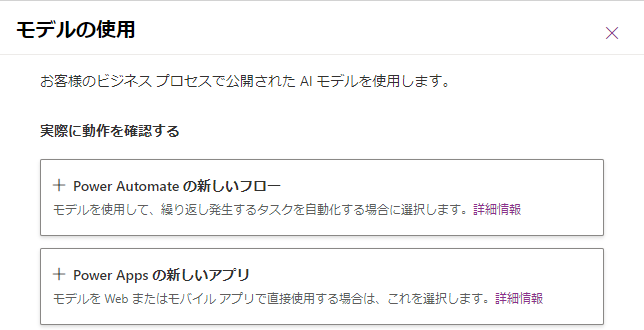
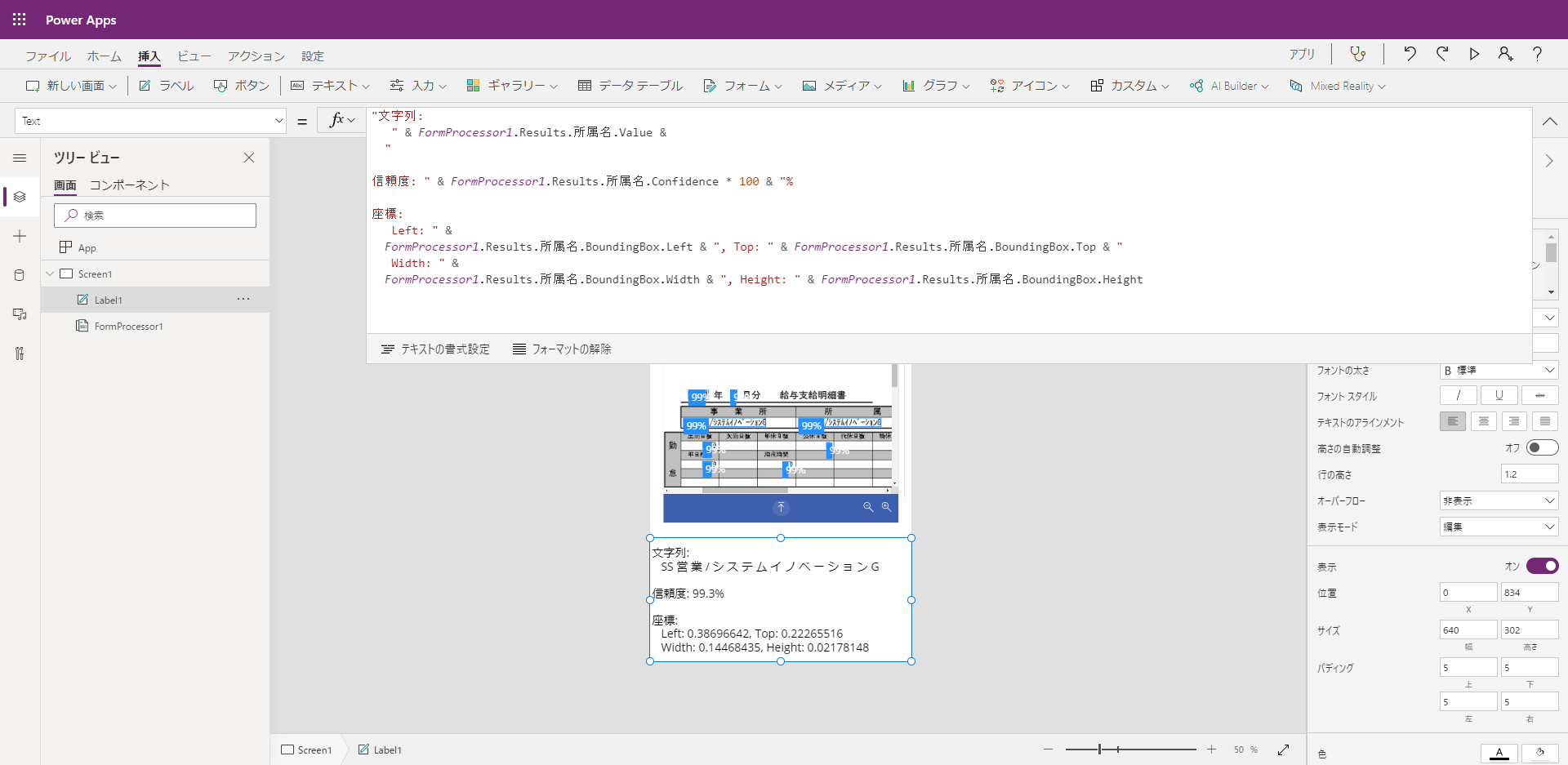
(16) Power Apps を選択すると、FormProcessorコンポーネントを含むキャンバスアプリが自動生成されます。クイックテストのような UI で結果を表示するだけでなく、他のコントロールから読み取り結果にアクセスすることもできます。次の図に、Labelコントロールに読み取り結果や信頼度、座標を表示してみた例を示します。
(17) 一方で、Power Automate を選択した場合には、読み取り項目のうちの3つ程度しか自動生成されたフローに含まれません。
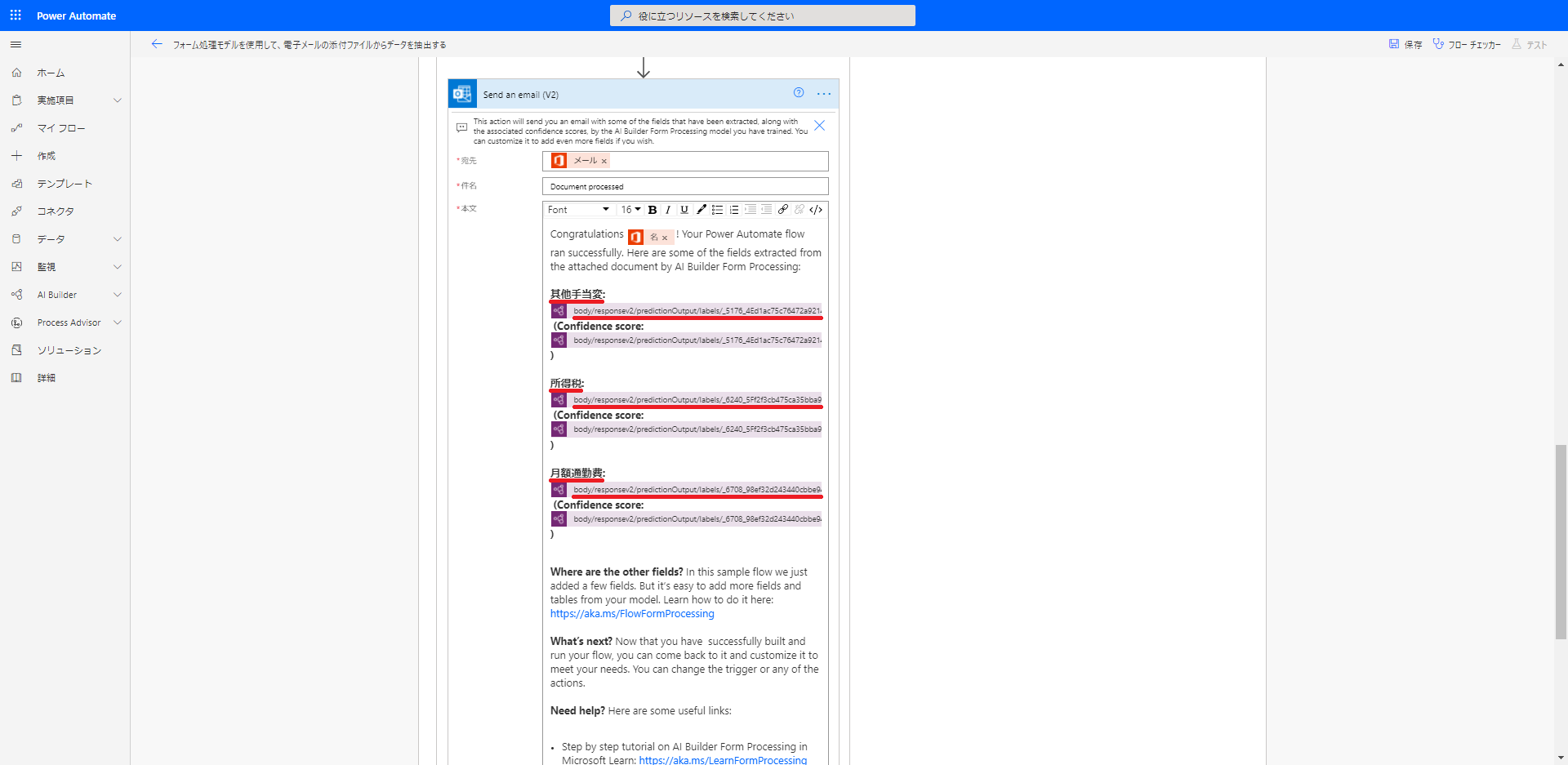
(18) 他の項目もフローに追加したい場合には、他の読み取り項目を示す内部的な ID を確認しなければなりません。
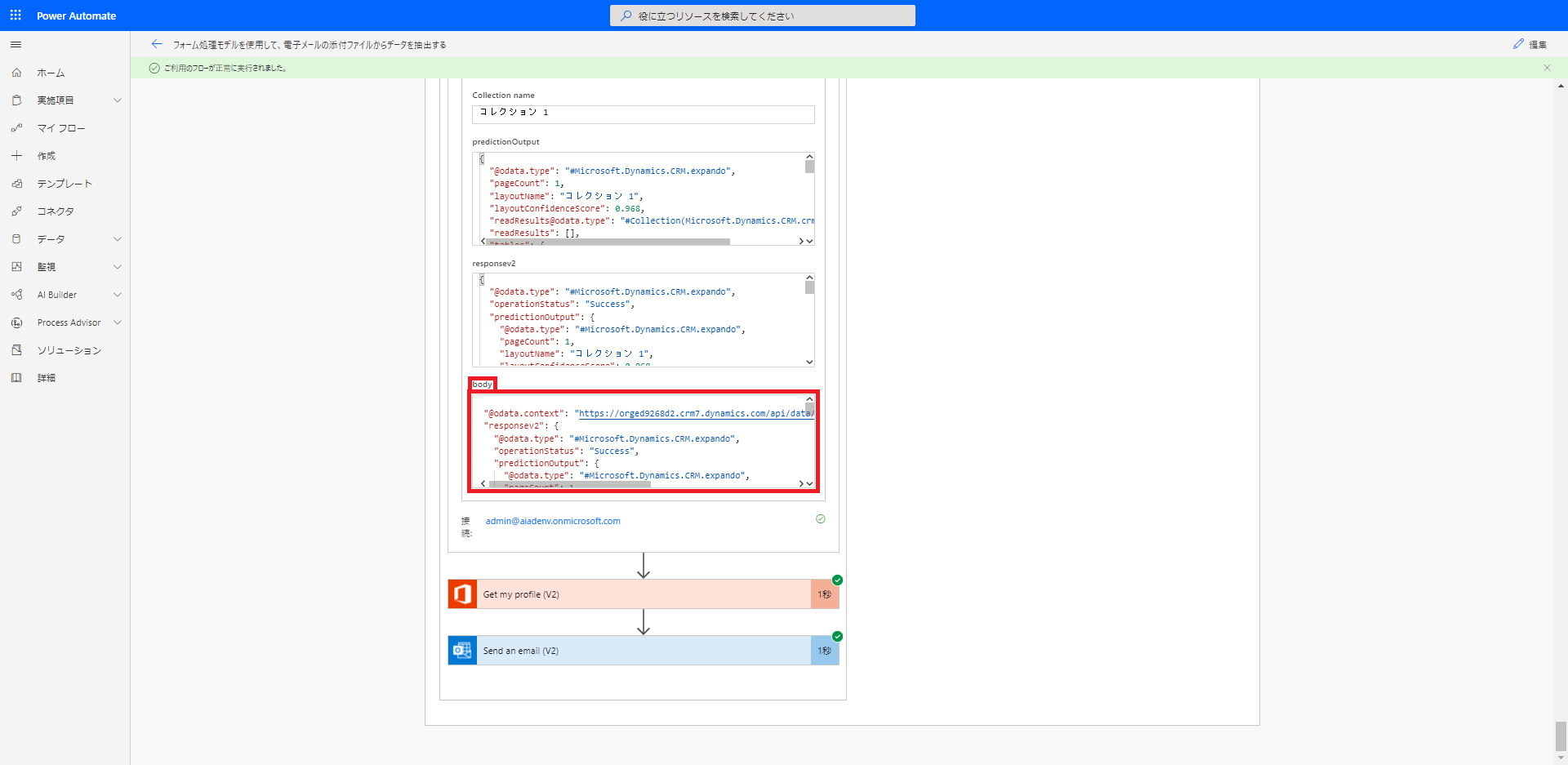
読み取り項目の内部IDを確認するためには、一度フローを実行してみて、フローの実行履歴から「Process and save information from forms」アクションの「body」をクリップボードにコピーします。フローのトリガーが「When a new email arrives (V3)」なので、自分自身宛てに添付ファイル付きのメールを送信すれば、このフローが実行されます。
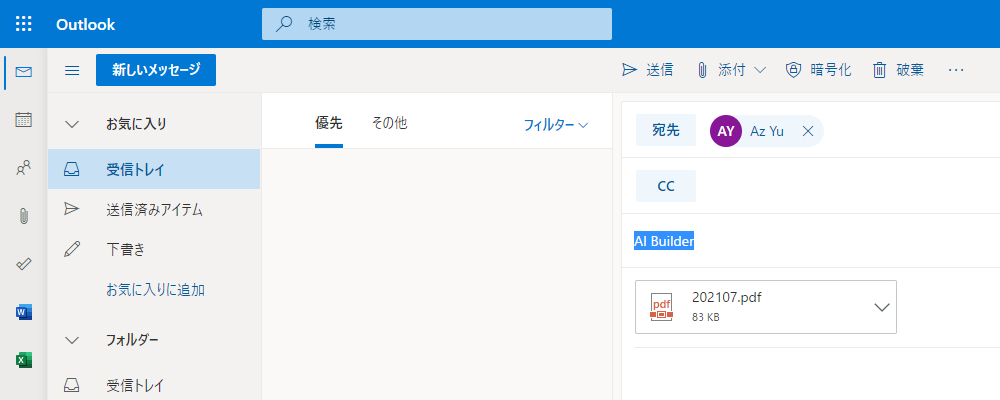
| a) テストデータを添付したメールを自分宛てに送信 | b) OCR読み取り結果(これをクリップボードにコピー) |
 |
 |
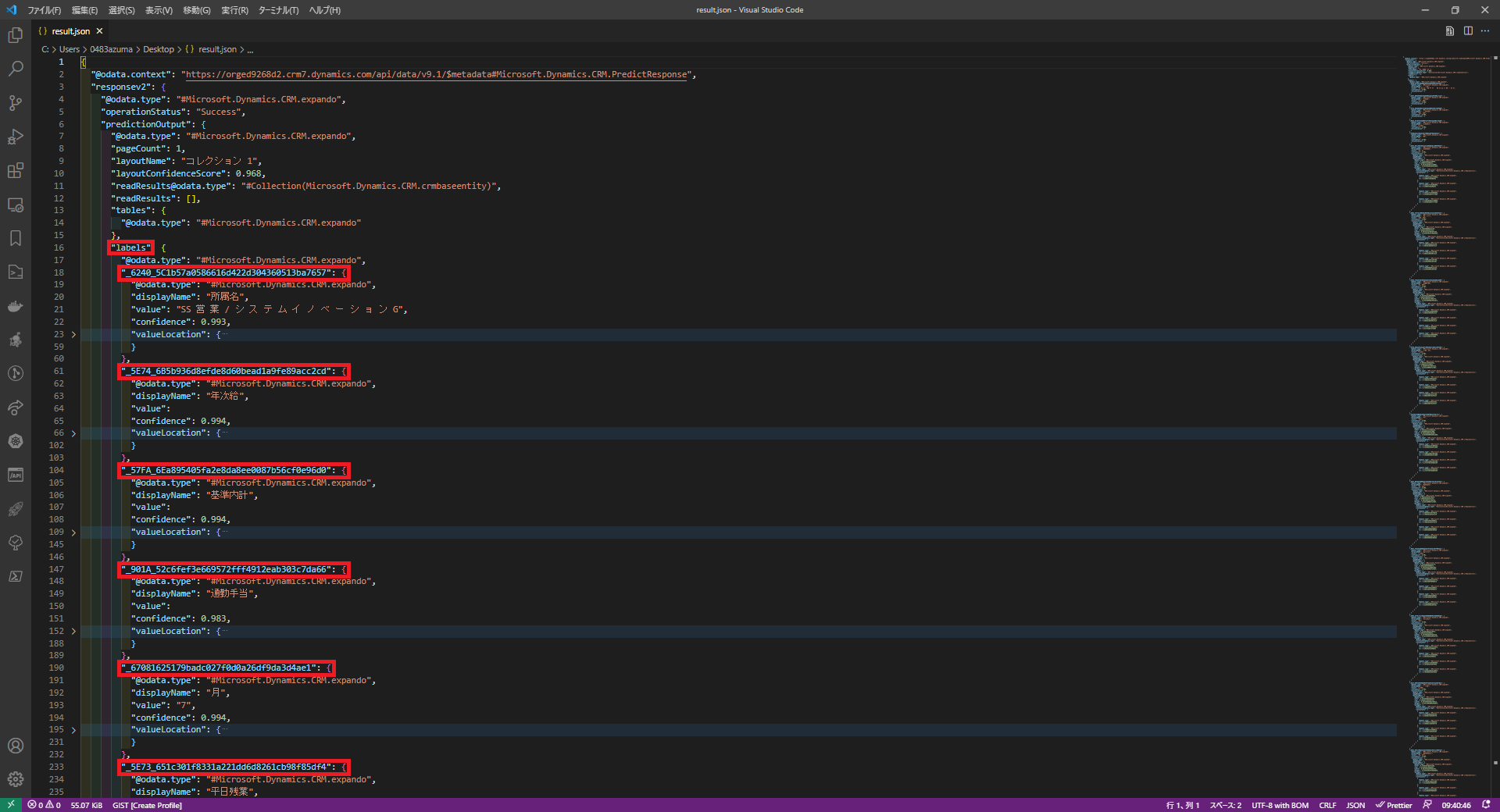
(19) コピーしたJSON文字列をVisual Studio Codeなどのエディターにペーストして整形します。
「labels」の中に、読み取り項目の一覧が記載されているので、日本語(ラベルを英語で定義すれば英語ですが)で書かれたvalueの値を参考に、必要な内部IDをピックアップしていき、Automateフローに反映させます。
(20) Power Automateフローで任意の項目を取得できるになると、Power Automateに用意された様々なコネクタを利用して、データを加工したり別のデータソースに書き出したりすることができます。
例えば、Excel Onlineへ書き出すアクションを利用してファイルに明細を出力して、Power BIでダッシュボードに表示してみた例が以下の図になります。
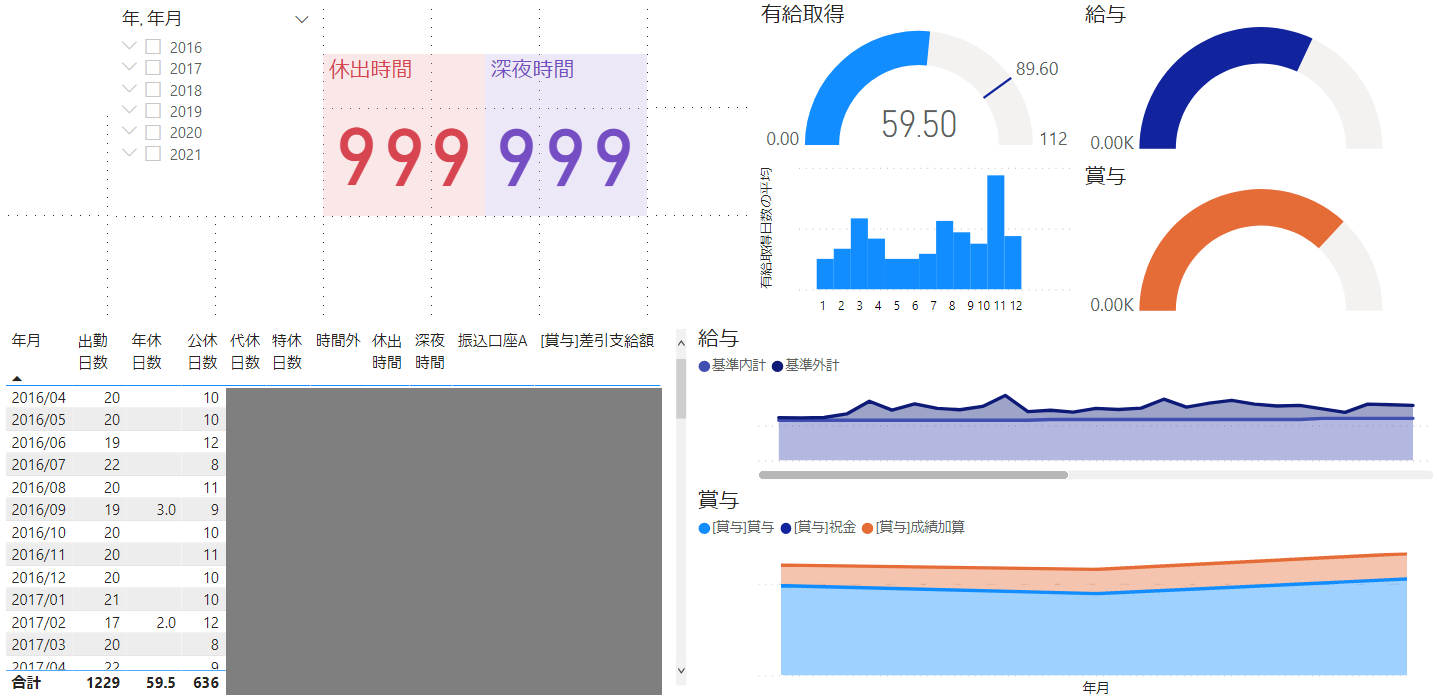
他にも、Dataverseへデータを書き込むアクションを利用して集計・一覧表示用キャンバスアプリから参照したり、オンプレミスデータゲートウェイ経由でオンプレのDBサーバーへデータを蓄積したりといった利用方法も考えられます。Power Automateで現在利用できるコネクタの一覧は、こちらの公式資料をご覧ください。
🎉これで完成です!!🎉
まとめ
今回は、ソースコードを書くことなくアプリ開発できるローコードツール「 Power Apps 」に含まれている、「フォーム処理」というOCR機能について簡単にご紹介しました。通常OCRを実装する時とは異なり、画像データの前処理、データアップロード機能の作成、AIモデルのトレーニングや評価・デプロイ(公開)、モデルを利用したOCRアプリケーションの作成まで、ほぼソースコードを書かずに行うことができました。
みなさんが、注文書や申請書といった「帳票」の取り扱いを自動化し、できる限り省力化・自動化するために、本記事の内容を役立てていただければと思います。
QESではPower Platform導入時の支援から、アプリケーション開発、導入後の保守サポートまで対応しております。
Power Apps/Power Platformに関して、お手伝いできることがありましたら何なりとご相談くださいませ。また以下のページもご覧ください。


このブログで参照されている、Microsoft、Windows、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
このブログで参照されている、Tesseractは米国github.inc社の登録または登録商標です。

