記事公開日
最終更新日
第3回 機械学習を試してみる(2/3)
第1章 事前処理(後編)
1.4. 欠損データの除去
データセットに含まれている欠損値を除去するための設定を行います。後ほど述べる学習モジュールでは、該当するデータがないことを示す「欠損値」が含まれている場合に、既定ではその部分のデータを固定値で置き換えてしまいますが、データの特徴によっては、元のデータが本来持つ傾向と異なってしまう可能性があるため、事前処理を行う必要があるのです。今回は、もしも欠損値を含むデータがあった場合には、信頼できないデータとして除去することとします。異なるデータセットを使用する場合など、異なる特徴を持つデータセットに対して学習を行う場合にどう取り扱うかについては、次の項で紹介します。
1.4.1.欠損データの除去手順
まず、「Clean Missing Data」モジュールを、画面中央の灰色の領域に配置します。
続いて「Select Columns in Dataset」モジュールの下部の丸印から「Clean Missing Data」モジュールに向けてドラッグアンドドロップします。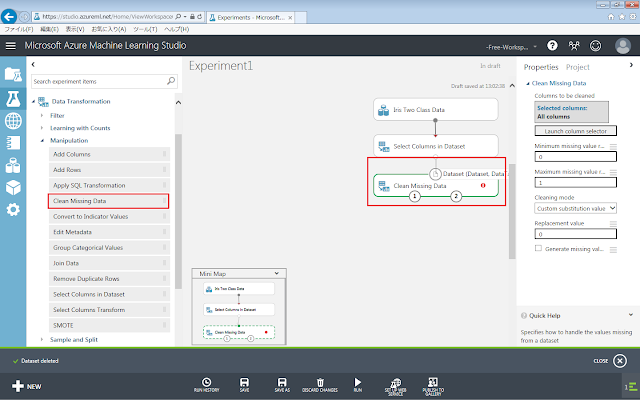
「Clean Missing Data」モジュールが選択された状態で、右側にある「Cleaning mode」セレクトメニューの値を「Remove entire row」へ変更します。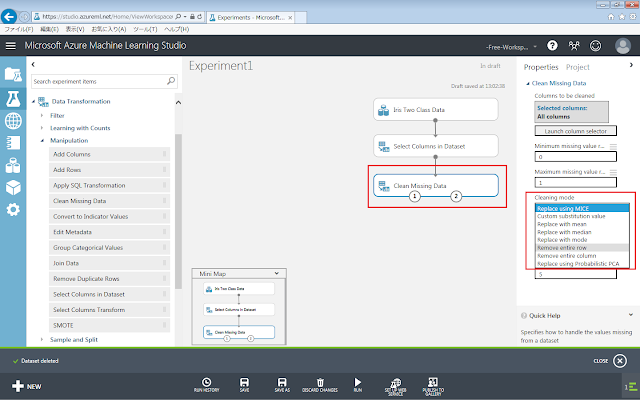
1.4.2. 解説
今回の事前処理では、データセットの中に欠損値が含まれるデータがあった場合には、そのデータを丸ごと除去しました。欠損値が含まれているデータの扱い方としては以下のような方法があります。
① リストワイズ法
…欠損値を含むデータ(欠損データ)を丸ごと除去するもの
② ペアワイズ法
…可能な限り多くの情報を残すために、データを丸ごと除去するのではなく、欠損値を含むようなデータの組み合わせのときだけ除去するもの
③ 代入法
- 欠損値を「0」(または他の定数)で置き換えるもの
- 欠損値を「他の正常なデータの平均値」で置き換えるもの
例に示したアヤメのデータセットの場合、中に含まれている花びらの長さや幅といったデータは0よりも大きい正の数しか取らないはずなので、欠損値を0に置き換えてしまうと平均値や最小値といった統計量に影響が出てしまうことになります。そのため欠損値を含むデータがあった場合には、信頼できないデータとして除去することとしました。
ただし、データセットに含まれるデータの総数を減らしすぎてしまうと、利用できるデータ数が不足して、正答率が下がってしまう可能性があります。そのため、「もしもデータが欠損していなかったらどのようなデータを取るのか」を予測できる状況であれば、削除するのではなく置き換えたほうが良いと考えられます。例えば、時系列データ(時間経過とともに変化するようなデータ)であれば、直前直後のデータを利用して近似することで、欠損値を補完することができます。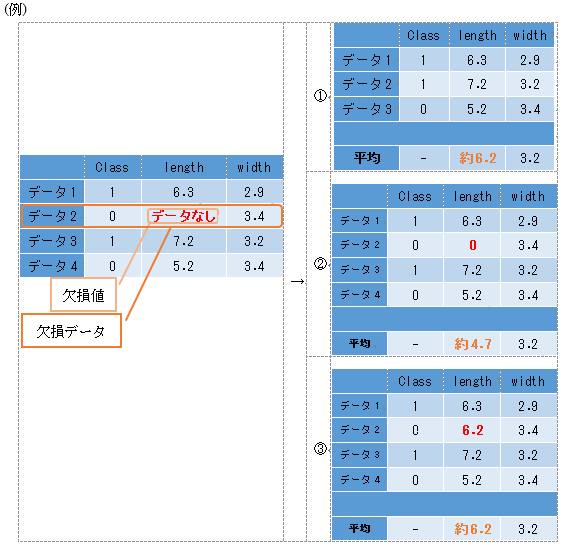
さらに、発展的な方法として、以下のようなものがあります。
④ 代入法
iii. 欠損値を、観測された他のデータから予測して置き換えるもの
⑤ 完全情報最尤推定法
…欠損値を置き換えるのではなく、欠損していない部分のみを最尤推定法(期待値最大化法)を用いて推定するもの
⑥ 多重代入法
…欠損値に異なるデータを代入したデータセットを多数用意して単一代入法を行い、それぞれで得られた複数の推定値を統合するもの
1.5.データセットの分割
学習させた結果がどのくらいの精度であるかを、ホールドアウト法(分割学習法)という手法を用いて評価します。これは、おおもとのデータセットを学習データと評価データの2つに分割することで、学習に使用していない未知のデータに対する予測精度を評価するものです。
1.5.1. データセットの分割手順
まず、「Data Transformation」→「Sample and Split」→「Split Data」モジュールを、画面中央の灰色の領域に配置します。
「Split Data」モジュールが選択された状態で右側のパネルを見てみると、いくつかのパラメーターを設定できるようになっています。「Split Data」モジュールを使用すると、単純にデータを等分割するだけでなく、分割する割合を変更したり、データセットの中にある個別のデータの値をもとに分割したりすることができます。
ここでは、データセットを学習データと評価データの2つに単純に分割することが目的なので、「Splitting mode」パラメーターには「Split Rows」を選択します。「Split Rows」を選択すると、「Fraction of rows in the first out dataset」テキストボックスが表示されます。この値は0から1の値をとる、データセットを分割する割合を示すものです。既定値である の場合、入力されたデータセットがデータセット①(左下の丸印)とデータセット②(右下の丸印)にそれぞれ5割ずつ振り分けられます。入力する値を例えば0.7へと変更すると、入力されたデータセットのうち7割のデータがデータセット①に、3割のデータがデータセット②に振り分けられます。
また、「Randomized split」チェックボックスが既定でチェックされていると思いますが、これはデータを分割する際にランダムに選び出して分けていくことを指定しています。このチェックがされていない場合、データセットの一番上から半分と一番下から半分とに機械的に分けられてしまいます。アヤメのデータセットのように品種列で整列されている場合には、このように分けると学習データと評価データの傾向に差が出てしまい、問題となります。評価のためなどで、毎回同じ乱数を使わなければならないときには、その下の「Random seed」テキストボックスに0よりも大きい数を指定することによって、乱数の種が固定され、乱数自体も一定のものを使用するようになります。
今回は使用しませんが、「Splitting mode」パラメーターに「Regular Expression」や「Relative Expression」を選択すると、データセットに含まれる個別のデータの値をもとに分割できます。「Splitting mode」パラメーターで「Regular Expression」を選択すると、「Regular expression」テキストボックスが表示されます。ここに例えば「\"Year" ^199」と入力し、かつデータセットに「Year」というデータ列が存在する場合、1990年代のデータだけをデータセット①に抽出し、残りのデータをデータセット②に出力させることができます。
また、「Splitting mode」パラメーターで「Relative Expression」を選択すると、「Relational expression」テキストボックスが表示されます。ここに例えば「\"Year" > 1994」と入力し、かつデータセットに「Year」というデータ列が存在する場合、1995年以降のデータだけをデータセット①に抽出し、残りのデータをデータセット②に出力させることができます。「Relative Expression」の場合、数値だけでなく日付や時刻などの値も比較させることができます。この場合「\"Time" <:17:30:01 & >08:59:59」のような指定を行います。
続いて、「Clean Missing Data」モジュールの左下の丸印から「Split Data」モジュールに向けてドラッグアンドドロップします。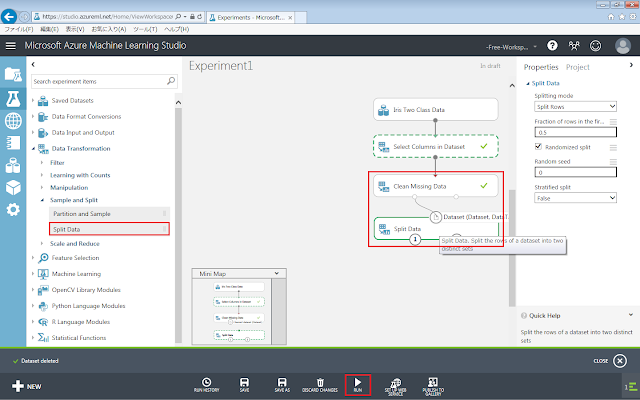
画面下部にある「Run」メニューをクリックし、ここまで配置したモジュールを実行します。
「Select Columns in Dataset」モジュールから「Split Data」モジュールへと処理が進むにつれて、各モジュールの右端に黄緑色のチェックマークが表示されていきます。
「Split Data」モジュールまで黄緑色のチェックマークが表示された後、「Split Data」モジュール下部の左右にある丸印をクリックすると現れるメニューの「Visualize」をクリックして、分割結果を確認します。
まず、「Split Data」モジュールの下部『左』側の「Visualize」を実行した結果を以下に示します。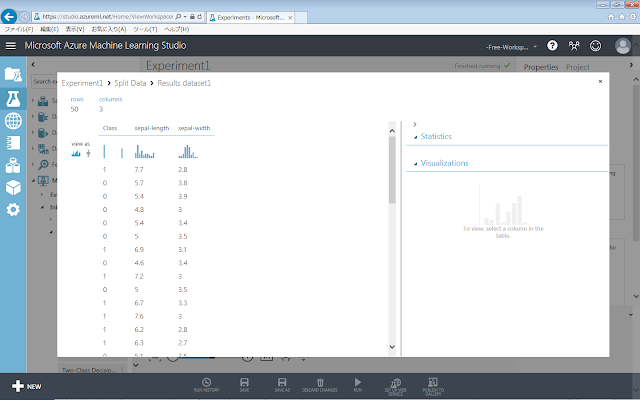
「Split Data」モジュールの下部『右』側の「Visualize」を実行した結果を以下に示します。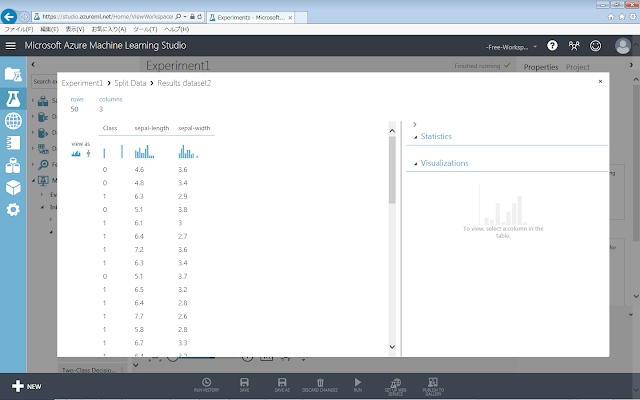
新しく左側と右側に作られた2つのデータセットのそれぞれに、データが50個ずつ含まれていることが確認できます。
1.5.2.解説
1.5.2.1. 処理内容
今回の事前処理では、ホールドアウト法(分割学習法)という手法を用いて評価するために、大元のアヤメのデータセットを「Split Data」モジュールを用いて、学習データと評価データの2つに分割しました。以下では、分割の途中経過をグラフとともに見てみます。
まず、加工前のデータセットを以下のグラフに示します。散布図に示すために、sepal-lengthとsepal-widthのみを取り出してそれぞれをx軸、y軸に当てはめています。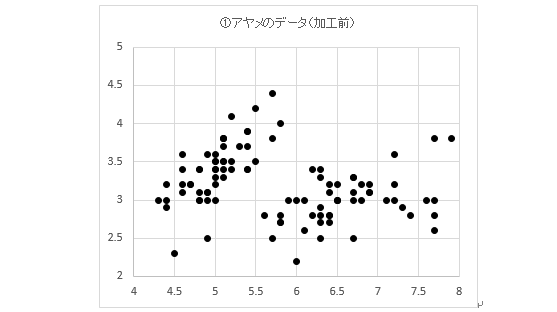
このグラフに対して、マーカーの種類で品種の区別を表したものが以下のグラフです。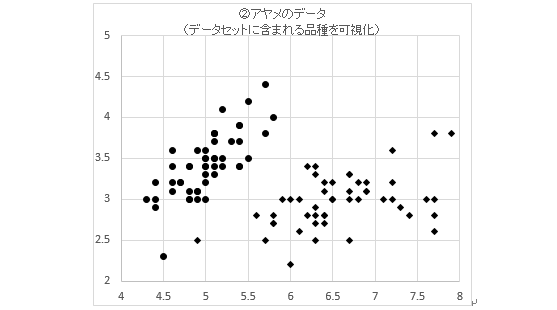
次に、このデータセットに対して「Split Data」モジュールを適用して、50%を学習用データセットに、残りの50%を評価用データセットとしたときのグラフを以下に示します。データセットに含まれる個々のデータをランダムに取り出しているため、大きな偏りがなく分割されています。
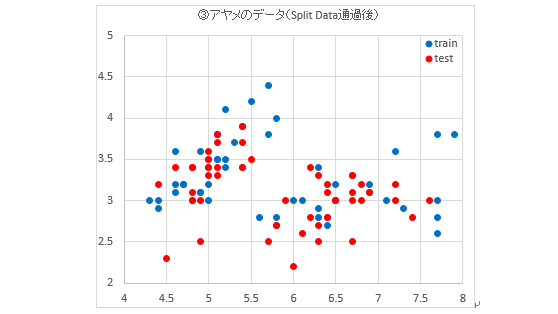
このグラフに対して、マーカーの種類で品種の区別を表したものが以下のグラフです。また、表に、分割されたデータセットそれぞれに含まれるデータの個数を示します。②のグラフと比較すると、データセット全体ではなく品種ごとの分割具合についても大きな偏りがないことが分かります。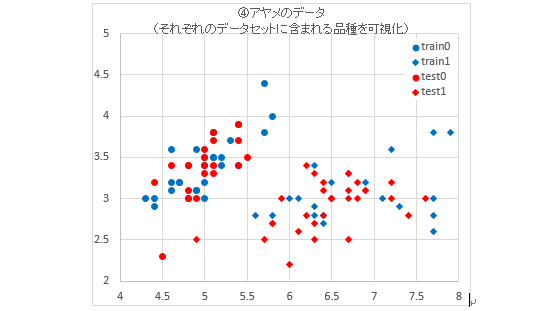

学習用データセットと評価用データセットで含まれるデータの傾向に差が生じてしまうと正しく評価できないため、検定と呼ばれる手順によって差がないことを確認しておく必要があります。検定には下の表に示したものの他にも多くの種類がありますが、ここでは 検定を使ってデータの傾向に差がないことを確認してみます。
検定を行うためのモジュールは、Azure Machine Learning上に用意されているので、今回はこれを使用します。
ここまでの手順を済ませると、以下の画面のような実験が出来上がっているでしょう。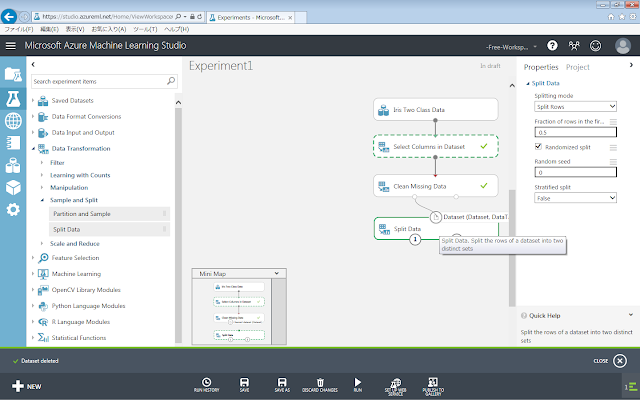
この項で紹介する手順は、本筋の操作手順とは無関係なので、一旦別名で保存しておきます。画面下端のツールバーにある「SAVE AS」ボタンをクリックし、別名で保存しておきます。
まず、「Add Columns」モジュールを灰色領域に配置します。
せっかく「Split Data」モジュールでデータセットを2つに分割したばかりですが、検定を行う「Test Hypothesis using t-Test」モジュールには1つのデータセットしか入力することができないために、「Add Columns」モジュールで1つのデータセットにまとめる必要があるのです。1つのデータセットにまとめるとは言っても、データセット内のデータ列はそれぞれ区別されます。
配置した「Add Columns」モジュールの左上、右上の丸印に向かって、既に実験の一番後ろに配置されている「Split Data」モジュールの左下、右下それぞれの丸印からドラッグアンドドロップを行い、線を結びます。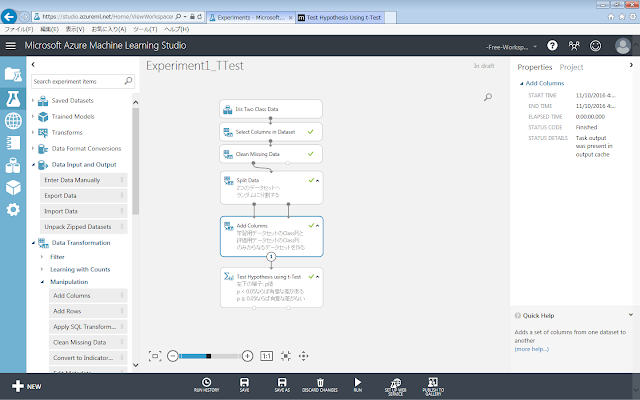
1.5.2.2. その他の評価方法
ホールドアウト法(分割学習法)以外にも以下のような評価方法があり、それぞれの評価方法に応じて事前のデータ分割が必要となります。いずれも、ホールドアウト法よりも使用するデータ数を減らさずに済みます。
l K分割
…データセットをK個に分割したサブデータセットを作成し、そのうちの1つを評価用データに、残りを学習用データとした評価をK回行い、得られたK個の結果を平均してデータセット全体の結果とするもの
l 1つ抜き法(一対他交差検証;Leave-one-out-cross-validation)
…K分割のKを総データ数としたもの
l 層化交差検証(Stratified cross validation)
…ラベルの比率に偏りがある場合に使用し、ラベルごとのデータの比率を保ったままK個に分割するもの
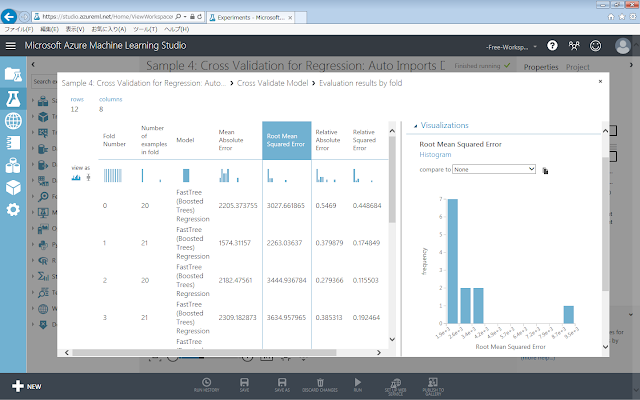
Kの値の上限はデータセットに含まれるデータの総数なので1つ抜き法(LOOCV)が最も正答率が高くなりますが、計算量や計算時間に制約からKの値は総データ数よりもなるべく小さい値を利用することが望ましいといえます。最適なKの値は、データセットごとに異なるため、目安となる値があるわけではなく、試行錯誤する必要があります。その際、モデルの妥当性を確認するための指標として、学習データセットと評価データセットから求める「平均平方二乗誤差(Root Mean Square Error)」がよく用いられます。Azure Machine Learningでは、「Cross Validation Model」モジュールの右下の丸印から「Visualize」メニューをクリックすると、以下のような評価結果画面が開き、RMSEが表示されます。