こんにちは!DXソリューション営業本部の大和矢です。
今回はMCP (Model Context Protocol) サーバ上で動作するAIエージェントツールとして、SLM (Small Language Model) を活用した「自然言語対応Gremlinクエリ実行ツール」を作成していきます。
こちらのツールは、Azure Cosmos DB for Gremlin に用意したグラフDBに対し、自然言語で指示を送るだけで、SLMがその意図を汲み取ってGremlinクエリを生成・実行するものです。
AI開発ではLLM(大規模言語モデル)の利用が主流ですが、今回はあえてSLM(小規模言語モデル)を選択しました。
SLMはLLMよりもパラメータ数が少なく、よりコンパクトで効率的なAIモデルのことを指しており、最近は以下の観点から注目されています。
- LLMの「無駄遣い」
現状、簡単なタスクにまで高性能なLLMが利用されていますが、これは明らかにオーバースペックであり、非効率だという声が上がっています。
- SLMの性能向上
最近のSLMは性能が飛躍的に向上しており、旧世代のLLMに匹敵、あるいはそれを上回るタスク処理能力を持っています。
- 圧倒的なコストパフォーマンス
運用コストがLLMに比べて、10分の1から30分の1に抑えられるという試算が出ており、コスト効率が非常に高いです。
- SLMの得意なタスク
要約、情報抽出、ツール呼び出しなど、定型的・反復的なタスクはSLMで十分対応可能ですあり、さらに、役割を特化させることで、その分野の「専門家」として驚異的な性能を発揮します。
「MCPって何?」と疑問に思う方は、以下のブログで紹介しておりますので、是非ご覧ください。
検証環境
今回使用するSLM、フレームワーク、データベースなどの環境は以下の通りです。
| 分類 |
使用する技術・サービス |
| SLM(MCPツール) |
Microsoft Phi-4 |
| LLM(AIエージェント) |
Azure OpenAI gpt-4.1 |
| AIエージェント構築フレームワーク |
LangGraph:ReActエージェント |
| グラフDB |
Azure Cosmos DB for Gremlin |
| MCPサーバ |
自作のローカルsse方式のMCPサーバ |
実装:自然言語を解釈するMCPサーバの構築
早速、今回のシステムの中核をなすMCPサーバの具体的な実装を見ていきましょう。
以下にサーバのPythonコードを示し、各部分を解説していきます。
import os
import json
import logging
import traceback
import asyncio
from contextlib import asynccontextmanager
from mcp.server.fastmcp import FastMCP
from gremlin_python.driver import client
from gremlin_python.driver.serializer import GraphSONSerializersV2d0
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
from azure.ai.inference.models import SystemMessage, UserMessage
from dotenv import load_dotenv
#.env ファイルを読み込む
load_dotenv()
# ロギング設定
logging.basicConfig(level=logging.INFO)
# Cosmos DB 接続情報
endpoint = os.environ.get("COSMOSDB_ENDPOINT", "")
primary_key = os.environ.get("COSMOSDB_PRIMARY_KEY", "")
database_name = os.environ.get("COSMOSDB_DATABASE_NAME", "")
graph_name = os.environ.get("COSMOSDB_GRAPH_NAME", "")
# SLM接続情報
slm_api_key = os.environ.get("AZURE_OPENAI_API_KEY_SLM", "")
slm_endpoint = os.environ.get("AZURE_OPENAI_API_URL_SLM", "")
slm_api_version = os.environ.get("AZURE_OPENAI_API_VERSION_SLM", "")
slm_deployment_name = os.environ.get("AZURE_OPENAI_DEPLOYMENT_NAME_SLM", "")
slm = ChatCompletionsClient(
endpoint=slm_endpoint,
credential=AzureKeyCredential(slm_api_key),
api_version=slm_api_version
)
@asynccontextmanager
async def gremlin_client_context():
"""Gremlinクライアントの非同期コンテキストマネージャ"""
client_instance = client.Client(
url=endpoint,
traversal_source='g',
username=f"/dbs/{database_name}/colls/{graph_name}",
password=primary_key,
message_serializer=GraphSONSerializersV2d0()
)
try:
yield client_instance
finally:
await asyncio.to_thread(client_instance.close)
async def execute_query_async(gremlin_client, query_string):
"""Gremlinクエリを非同期で実行し、結果をリストで返すヘルパー関数。"""
try:
logging.info(f"Gremlinクエリ実行: {query_string}")
def blocking_gremlin_call():
result_set = gremlin_client.submitAsync(query_string)
return result_set.result()
results = await asyncio.to_thread(blocking_gremlin_call)
return list(results)
except Exception as e:
logging.error(f"クエリ実行エラー: {query_string}\n{e}", exc_info=True)
return {"error": str(e), "traceback": traceback.format_exc()}
# MCP サーバインスタンスの作成
blog_mcp = FastMCP("BlogMCP")
# システムプロンプト
SYSTEM_PROMPT = """
あなたは、ユーザーからの自然言語の質問をGremlinクエリに変換する専門家です。
【極めて重要な指示】
- 生成するのはGremlinクエリのコードのみとし、説明や他のテキストは一切含めないでください**。
- **生成されるGremlinクエリの前後には、いかなる形式のバッククォート(`)やその他の記号、余分な空白、改行を含めないでください。純粋なGremlinクエリ文字列のみを出力してください。**
- 複雑な探索や長いクエリ(2段以上のエッジ連鎖や多段階の関係取得)は生成しないでください。1段階のシンプルなクエリのみを生成してください。
- 例: out('A').in('B')やout('A').out('B')のような多段階のエッジ連鎖は禁止です。
## スキーマ情報
## personノード
- 属性: id, label, partitionKey, name, age, gender
- 例: id: p1, label: person, partitionKey: p1, name: Hanako, age: 28, gender: female
- 関係: out('has_origin') -> cityノード, out('has_hobby') -> hobbyノード, out('works_at') -> jobノード, out('is_related_to') -> personノード
## cityノード
- 属性: id, label, name, country
- 例: id: c1, label: city, name: Tokyo, country: Japan
- 関係: in('has_origin') -> personノード
## hobbyノード
- 属性: id, label, name, category
- 例: id: h1, label: hobby, name: Reading, category: Art
- 関係: in('has_hobby') -> personノード
## jobノード
- 属性: id, label, name, company, industry
- 例: id: j1, label: job, name: Engineer, company: TechSolutions Inc., industry: IT
- 関係: in('works_at') -> personノード
# Few-shot Examples
- 質問: Hanakoさんの趣味を教えて
- クエリ: g.V().has('person', 'name', 'Hanako').out('has_hobby').valueMap('id', 'name', 'category')
- 質問: Hanakoさんの出身地を教えて
- クエリ: g.V().has('person', 'name', 'Hanako').out('has_origin').valueMap('id', 'name', 'country')
- 質問: Hanakoさんが働いている会社を教えて
- クエリ: g.V().has('person', 'name', 'Hanako').out('works_at').valueMap('id', 'name', 'company', 'industry')
"""
@blog_mcp.tool()
async def search_tool(context: str) -> str:
"""
自然言語の質問に答えるツール。人物や出身地や職業、趣味などの問いに回答します。
シンプルな質問に対する回答が得意です。
複雑な質問をする際は、シンプルな質問に分割して段階的にデータ取得してください。
"""
try:
response = await asyncio.to_thread(
slm.complete,
messages=,
model=slm_deployment_name,
max_tokens=2048,
temperature=0.8,
top_p=0.1,
presence_penalty=0.0,
frequency_penalty=0.0
)
generated_query = response.choices.message.content.strip()
async with gremlin_client_context() as gremlin_client:
result = await execute_query_async(gremlin_client, generated_query)
return json.dumps(result, ensure_ascii=False)
except Exception as e:
return json.dumps({"error": str(e), "traceback": traceback.format_exc()}, ensure_ascii=False)
if __name__ == "__main__":
print("BlogMCP サーバを起動しています...")
blog_mcp.run(transport="sse")
環境設定とクライアント初期化
コードの冒頭では、dotenvライブラリを使って.envファイルからCosmos DBやAzure AI Inferenceのエンドポイント、APIキーといった機密情報を安全に読み込んでいます。
その後、それぞれの情報を使って、Phi-4モデルと対話するためのChatCompletionsClientと、Cosmos DBに接続するための情報を変数に格納しています。
Gremlinクエリの非同期実行
gremlin_client_context
この関数はasynccontextmanagerデコレータを使って定義されています。
これは、データベース接続のようなリソースを管理するためのPythonにおけるベストプラクティスです。
withブロックの開始時に接続を確立し、ブロックを抜ける際に(たとえエラーが発生したとしても)finally句でclient_instance.close()が確実に呼び出され、接続が適切に閉じられることを保証します。
execute_query_async
データベースへの問い合わせを非同期で実行し、アプリケーションの応答性を維持するための関数です。
この関数のポイントは、gremlin_pythonライブラリが提供するブロッキング(同期的)な処理を、asyncio.to_thread()を使って別スレッドで実行している点です。
もしブロッキング処理をそのままasync関数内で呼び出すと、プログラム全体が停止してしまいます。
asyncio.to_thread()を使うことで、その問題を回避し、非同期処理のメリットを最大限に活かしています。
これは、非同期に対応していないライブラリを現代の非同期プログラムに統合するための、非常に実践的なテクニックです。
中核機能 search_tool とシステムプロンプト
@blog_mcp.tool() デコレータ
このデコレータが、search_tool関数をFastMCPサーバに「ツール」として登録する役割を担います。
これにより、LangGraphのReActエージェントはこのツールの存在を認識し、呼び出すことが可能になります。
また、ツールの定義("""自然言語の質問に答えるツール..."""の部分)も極めて重要です。
エージェントは、この説明文を読んで、どのような質問が来たときにこのツールを使うべきかを判断します。
SYSTEM_PROMPT
このシステムの「知能」の核心は、SYSTEM_PROMPTにあります。
このプロンプトは、SLMの振る舞いを精密に制御するために、いくつかのテクニックを組み合わせて設計されています。
- 役割設定:
あなたは...専門家ですという一文で、SLMに特定の役割を演じさせ、Gremlinクエリ生成に特化した思考モードに切り替えさせます。
- 厳格な出力形式の指定:
【極めて重要な指示】以下の部分は、このシステムの成功に不可欠です。
モデルに対して、Gremlinクエリ文字列「のみ」を出力し、バッククォートや説明文、余分なテキストを一切含めないよう強く指示しています。
モデルの出力はそのままデータベースクライアントに渡されるため、余計な文字が一つでもあれば構文エラーを引き起こします。
- 負の制約:
複雑な探索...は生成しないでくださいと明示的に禁止することで、タスクの複雑さを意図的に制限しています。
これにより、SLMが生成するクエリの信頼性が向上し、非効率的なクエリが実行されるのを防ぎます。
- スキーマ情報の提供:
##スキーマ情報以下で、データベースの「APIドキュメント」をモデルに提供しています。
ノードの種類(person, cityなど)、そのプロパティ(name, ageなど)、そしてそれらの間の関係(out('has_hobby')など)を定義することで、モデルが有効なクエリを構築するために必要な情報を与えています。
- Few-shot Examples(少数事例):
最後に、具体的な質問とそれに対応する正しいクエリの例をいくつか示すことで、我々が期待する入力と出力のパターンをモデルに学習させています。
モデルはこれらの例から一般化を行い、未知の新しい質問にも対応できるようになります。
グラフDB
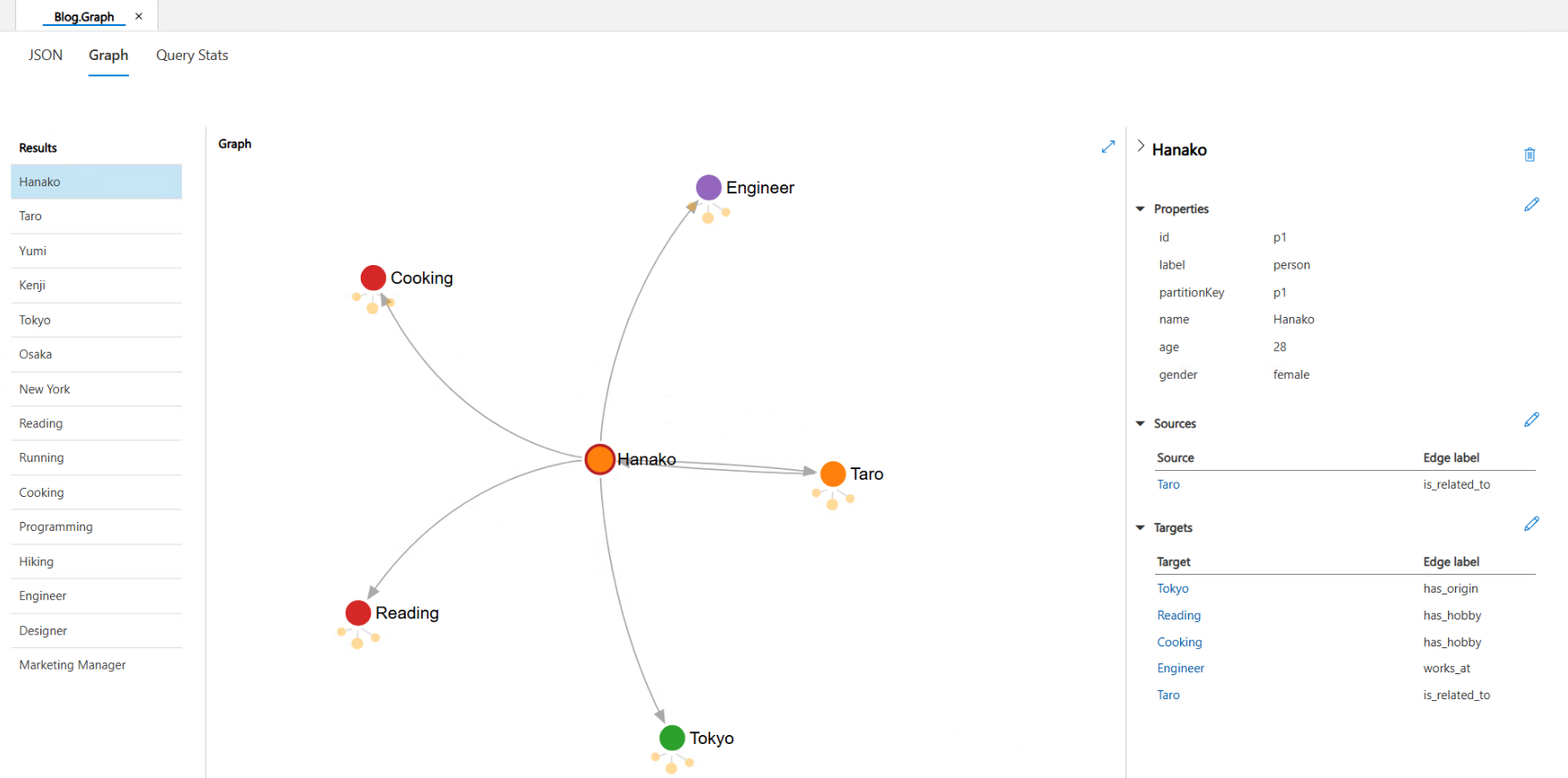
今回は、「人物・趣味・職業・出身地」といったノードを作成し、人物基点でエッジを構築しました。
以下のように、グラフDBを構成しております。
AIエージェント
今回は、AIエージェントの実装コードの説明は割愛します。
エージェントの役割は、ユーザーからの曖昧な自然言語の要求を解釈し、どのツールをどのような順番で使うべきかを判断することです。
エージェントの振る舞いを決定づける上で重要なのが、MCPサーバのSLMのシステムプロンプトと同様に、エージェント自身に与えるシステムプロンプトです。
このプロンプトは、エージェントの役割、性格、そして行動指針を定義します。
あなたは、ユーザーの質問に答えるための優秀なアシスタントです。
ユーザーからの質問を注意深く分析し、どのツールを使用すべきかを判断してください。
必要であれば、多段階のツール利用を実行してください。
ツールの実行結果を元に、最終的な回答を生成してください。
もし情報が不足している場合は、正直に「分かりません」と答えてください。
上記のシステムプロンプトに加え、先ほど作成したMCPサーバと接続し、ツールを付与することで、AIエージェントはMCPサーバを介してグラフDBからデータを取得してきます。
動作検証と考察
実際にMCPサーバを起動し、エージェントに質問を入力することで、動作を確認することができました。
以下で、質問とエージェントの動作、作成クエリを紹介しますが、ユーザーの質問に対して、サーバ側でGremlinクエリが正しく生成され、最終的に自然な日本語で回答が返ってきていることが確認できます。
Kenjiさんの出生地は?
まずは、人物ノードの隣にある出生地について、一段階のクエリでデータ取得可能な質問を投げます。
AIエージェント側のログ
user: Kenjiさんの出生地は?
---
[思考] ツールを使って情報を取得する必要があります。
[アクション] ツール'search_tool'を呼び出します。入力: {'context': 'Kenjiの出生地'}
---
[観察結果] ツールから以下の結果が返されました:
[[{"id": [], "name": ["New York"], "country": ["USA"]}]]
assistant: Kenjiさんの出生地はアメリカ合衆国のニューヨークです。
MCPサーバで作成・実行されたクエリ
INFO:root:Gremlinクエリ実行: g.V().has('person', 'name', 'Kenji').out('has_origin').valueMap('id', 'name', 'country')
適切なクエリが生成され、データが取得できていることが確認できます。
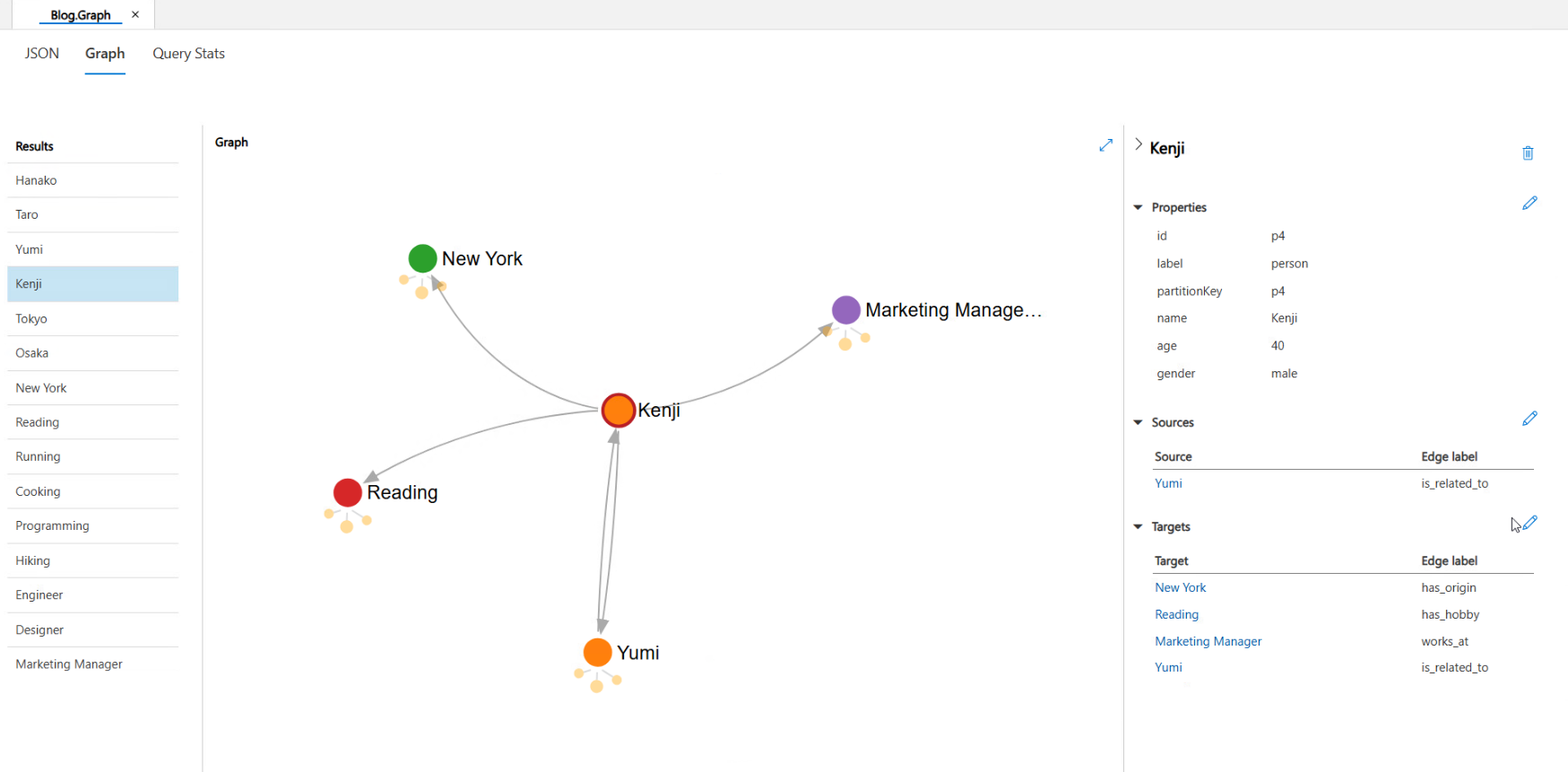
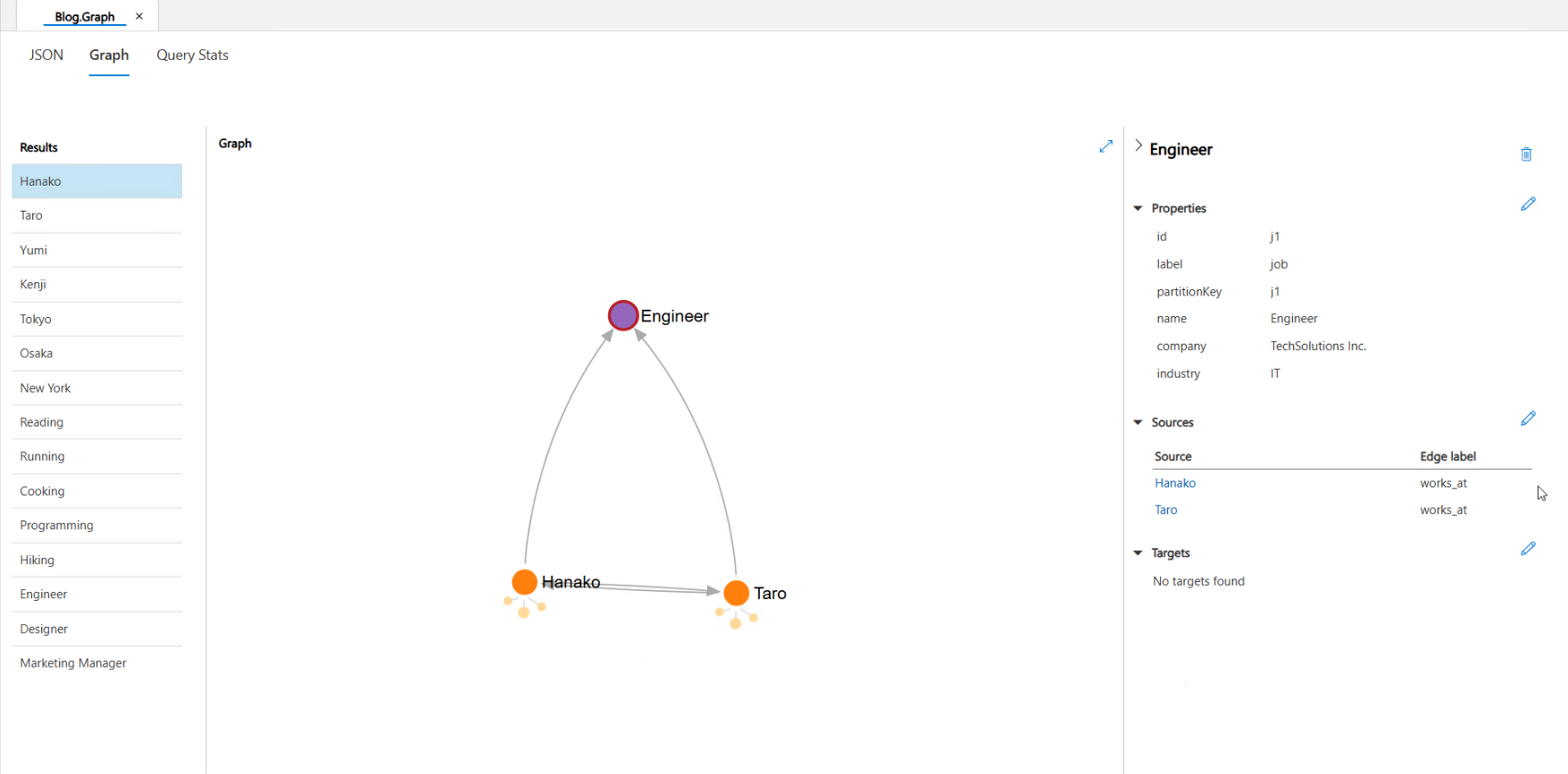
Taroさんと同じ職業の人は?
次に、二段階のクエリが必要な質問を投げかけます。
AIエージェント側のログ
user: Taroさんと同じ職業の人は?
---
[思考] ツールを使って情報を取得する必要があります。
[アクション] ツール'search_tool'を呼び出します。入力: {'context': 'Taroの職業'}
---
[観察結果] ツールから以下の結果が返されました:
[[{"id": [], "name": ["Engineer"], "company": ["TechSolutions Inc."], "industry": ["IT"]}]]
---
[思考] ツールを使って情報を取得する必要があります。
[アクション] ツール'search_tool'を呼び出します。入力: {'context': 'Engineerと同じ職業の人'}
---
[観察結果] ツールから以下の結果が返されました:
[[{"id": [], "name": ["Hanako"], "age": [28], "gender": ["female"]}, {"id": [], "name": ["Taro"], "age": [32], "gender": ["male"]}]]
assistant: Taroさんと同じ職業(エンジニア)の方として、Hanakoさんがいます。彼女もエンジニアとして働いているようですね。
MCPサーバで作成・実行されたクエリ
1回目のクエリ実行:
INFO:root:Gremlinクエリ実行: g.V().has('person', 'name', 'Taro').out('works_at').valueMap('id', 'name', 'company', 'industry')
2回目のクエリ実行:
INFO:root:Gremlinクエリ実行: g.V().has('job', 'name', 'Engineer').in('works_at').valueMap('id', 'name', 'age', 'gender')
こちらでも適切な二段階クエリが生成され、データが取得できていることが確認できます。
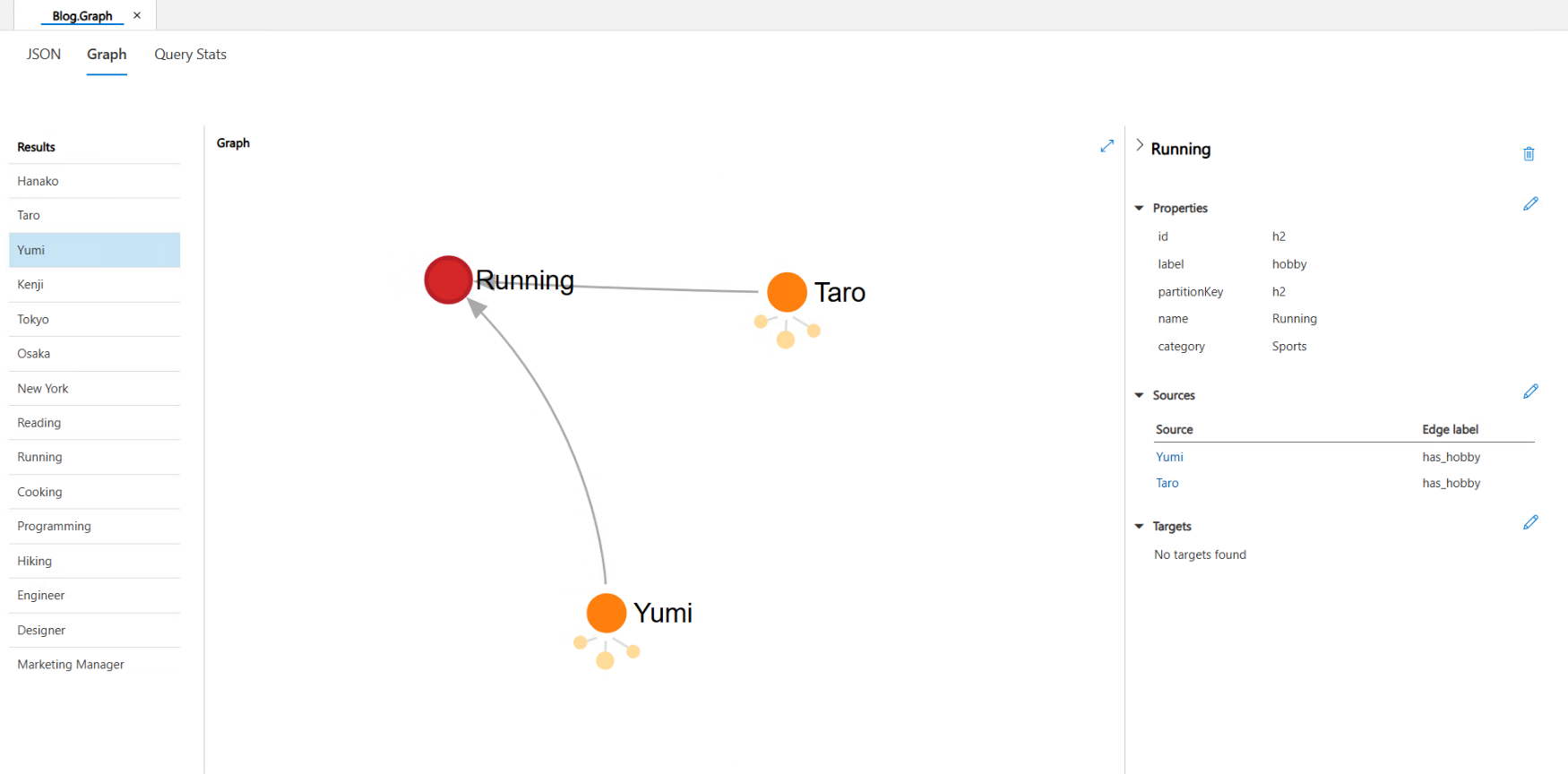
Yumiさんと同じ趣味の人は?
再度、二段階のクエリが必要な質問を投げかけてみます。
AIエージェント側のログ
user:Yumiさんと同じ趣味の人は?
---
[思考] ツールを使って情報を取得する必要があります。
[アクション] ツール'search_tool'を呼び出します。入力: {'context': 'Yumiと同じ職業の人'}
---
[観察結果] ツールから以下の結果が返されました:
[[{"id": [], "name": ["Taro"]}]]
assistant: yumiさんと同じ趣味を持つ人として「Taro」さんがいますよ!同じ趣味の仲間が見つかるのは嬉しいですね。
MCPサーバで作成・実行されたクエリ
INFO:root:Gremlinクエリ実行: g.V().has('person', 'name', 'Yumi').out('has_hobby').in('has_hobby').has('person', 'name', neq('Yumi')).valueMap('id', 'name')
今回の質問ではデータは取得できてはいますが、本来は二段階でクエリを実行してほしいところを、一回のクエリ作成・実行で完了しています。
考察
今回の検証では、「Taroさんと同じ職業の人」を尋ねた際には、想定通り二段階のシンプルなクエリを生成・実行されました。
しかし、「Yumiさんと同じ趣味の人」という同様の質問に対しては、一段階で完結する、より高度な単一のクエリを生成しました。
どちらのケースでも結果的に求めていたデータは取得できていますが、後者の挙動は「シンプルなクエリを、必要であれば多段階で実行する」という当初の指示とは異なります。
この結果から、AIエージェントおよびMCPサーバの挙動やとプロンプト設計について、2つの示唆が得られます。
- クエリ作成が成功した要因:正確なコンテキストの提供
SLMが一段階の複雑なクエリを正しく生成できた直接的な要因は、システムプロンプトを通じてグラフのスキーマ情報(ノードやエッジの定義)とクエリ作成時の制約(禁止事項など)を明示的に与えていたことにあると考えられます。
これらの情報がなければ、AIはグラフの構造を理解できず、適切なクエリを組み立てることは難しいです。
このことから、AIに専門的なタスクを解かせる上で、質の高いコンテキストを与えることの重要性を示しています。
- AIの「解釈」とツール定義の曖昧さ
一方で、なぜAIは「多段階で」という指示に従わなかったのでしょうか。
それは、MCPツールの定義の曖昧さにあります。
今回、ツールは以下のように定義しましたが、AIエージェント側が"複雑な質問"や"シンプルな質問"を理解しきれず、筆者が期待した「思考プロセスが分かりやすい二段階の処理」ではなく、「結果的に効率的な一段階の処理」をSLMに行わせるコンテキストを渡しました。
自然言語の質問に答えるツール。
人物や出身地や職業、趣味などの問いに回答します。
シンプルな質問に対する回答が得意です。
複雑な質問をする際は、シンプルな質問に分割して段階的にデータ取得してください。
まとめ
今回の検証を通じて、以下の2点を感じました。
- SLMの実用性:
SLMでも、適切にシステムプロンプトを設定すれば、単純なタスクはこなしてくれそうです。
しかし、やはりLLMに比べると、タスク遂行能力が低いと感じることは多々あったので、今後はSLMが適しているタスクや場面などを探っていく必要がありそうです。
- プロンプトエンジニアリングの重要性:
今回のシステムは、システムプロンプトの設計に大きく依存しています。
プロンプトは、モデルの振る舞いを規定しますが、今回はグラフDBのスキーマやクエリ禁止事項、クエリ例を与えるなどして工夫しました。
筆者は引き続きブログで、AI関連のテーマについて執筆していくので、ぜひご覧ください。
QUICK E-Solutionsでは、各AIサービスを利用したシステム導入のお手伝いをしております。
それ以外でも QESでは様々なアプリケーションの開発・導入を行っております。提供するサービス・ソリューションにつきましては こちら に掲載しております。
システム開発・構築でお困りの問題や弊社が提供するサービス・ソリューションにご興味を抱かれましたら、是非一度 お問い合わせ ください。
※このブログで参照されている、Microsoft、Azure、その他のマイクロソフト製品およびサービスは、米国およびその他の国におけるマイクロソフトの商標または登録商標です。
※その他の会社名、製品名は各社の登録商標または商標です。



