第7回 オープンデータを利用した予測/分類(1/3)
前回までは、Azure Machine Learning内に用意されているサンプルデータを対象として機械学習を行いましたが、本章では、より実社会に近いデータを機械学習で処理する例を示します。
機械学習を行う上で、最も手間がかかる作業はデータ収集ではないでしょうか。今回は、公的機関によって公開されているオープンデータを使用することで、データ収集コストを節約します。オープンデータとは、誰でも自由に使えて、再利用・再配布を行うことができるようなデータを指します。中でも特に、機械が判読できるデータ形式のものに限ってオープンデータと呼ぶ場合もあります。国や地方公共団体によっては、データカタログサイトと呼ばれるWebページに、オープンデータをまとめて掲載しています。
1.1. 使用するデータ
以下の統計情報を使用します。農作物の収穫量が気候に依存するという仮説をもとに、入力データには気象統計を、出力データには農作物収穫量統計を選択しました。
1.2. 予測/分類によって得たい結果と大まかな手順
今回は、農作物の収穫量を回帰分析によって予測する学習モデルを作ります。学習、評価のそれぞれで入出力するデータの種類を以下の表に示します。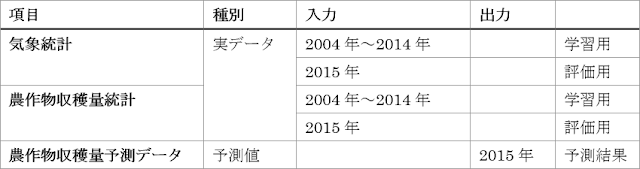
まず、使用するすべてのデータを含めたデータセットを、CSVファイルとして用意します。次に、データセットをAzure Machine Learningへアップロードして、2014年までの気象統計と農作物収穫量統計をもとに学習モデルを構築します。次に、構築した学習モデルに2015年の気象統計を入力して、2015年の農作物収穫量を予測させます。最後に、得られた2015年の農作物収穫量の予測データと実際に収穫された量である2015年の農作物収穫量統計とを比較して、予測精度を求めることで評価します。
ボリュームが多くなるため、本記事ではデータセットを作成するまでの手順をご紹介します。
1.3. データセットの作成
1.3.1. データセットに含める列
気象と農作物のデータセット(rice.csv) を作成します。このデータセットには、オープンデータとして官公庁から公開されている日本の都道府県別の気象統計と農作物の統計、各都道府県の経緯度のデータを含めます。このデータセットに含める列の一覧を以下に示します。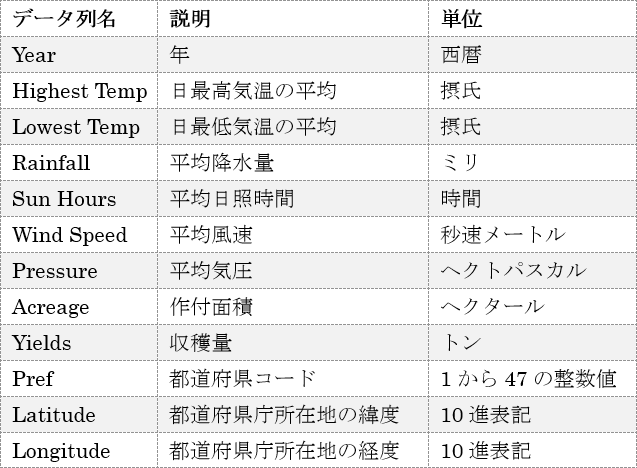
データセットに格納される値の例を以下に示します。
1.3.2. データ収集
まずは、官公庁によって公開されているオープンデータをダウンロードします。以下に操作手順とスクリーンショットを示しますが、より新しい情報が公開されるとページのレイアウトなどが変更されると思いますので適宜読み替えてください。
1つ目に、気象庁によって公開されている、過去の気象統計の取得方法をご紹介します。今回作成するデータセットには、気象統計の中でも特に、気温、降水量、日照時間、風速、気圧のデータを含めます。
①気象庁の過去の気象データ・ダウンロードを開きます。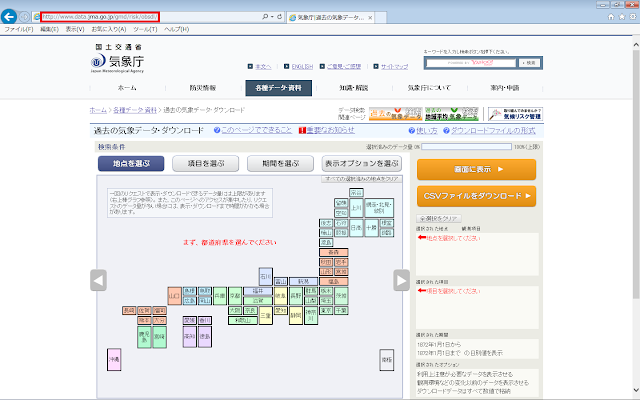
②都道府県、地名(気象台名)の順に選択します。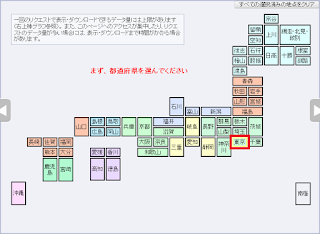
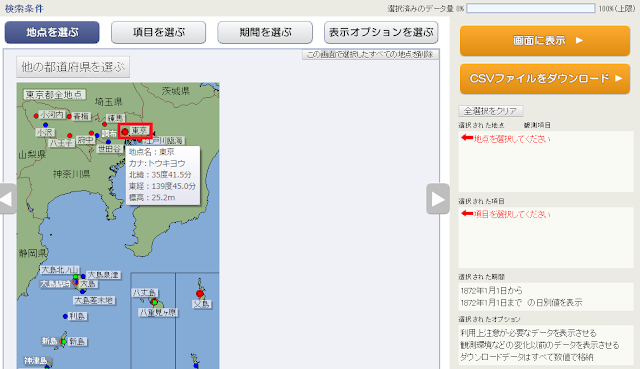
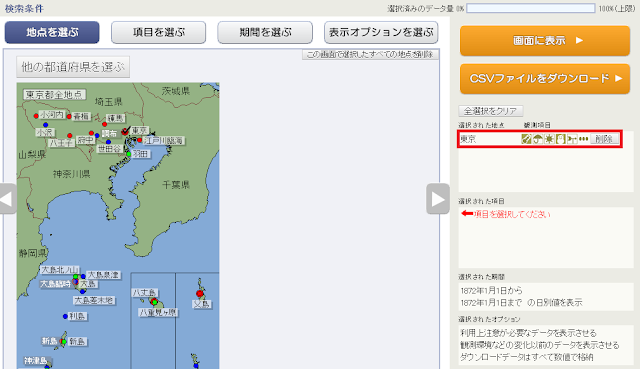
③「項目を選ぶ」ボタンをクリックします。左上の「データの種類」欄で「日別値」が選択されていることを確認してから、下の欄でダウンロードする項目のチェックボックスを入れていきます。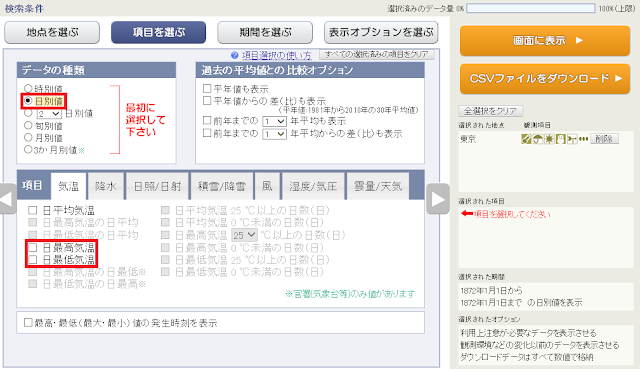
選択する項目と、それらが含まれているタブの一覧を以下に示します。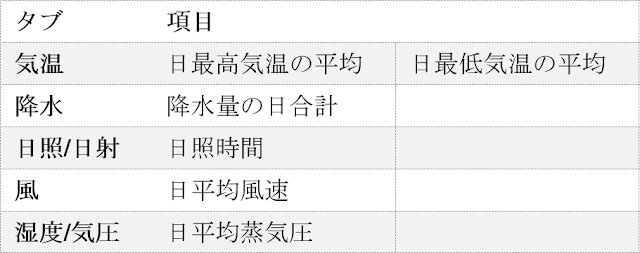
④右側の「選択された項目」を見て、必要な項目が選択されていることを確認したら次へ進みます。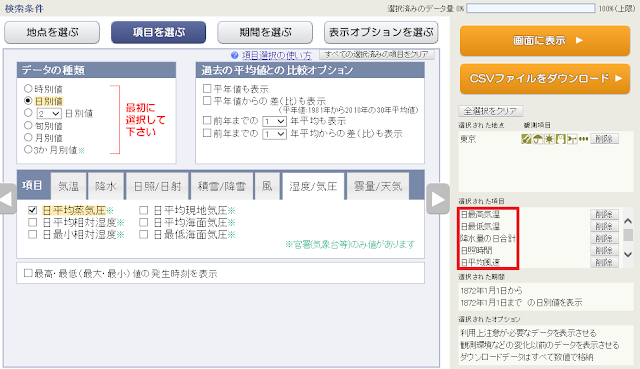
⑤「期間を選ぶ」ボタンをクリックし、ダウンロード対象とする期間を設定します。後で農作物収穫量統計と結合するために年別に加工するので、1月1日で始まり12月31日で終了するように設定しておくと良いでしょう。右上のオレンジのバーに表示される「選択済みのデータ量」が100%に届かないように期間を選びます。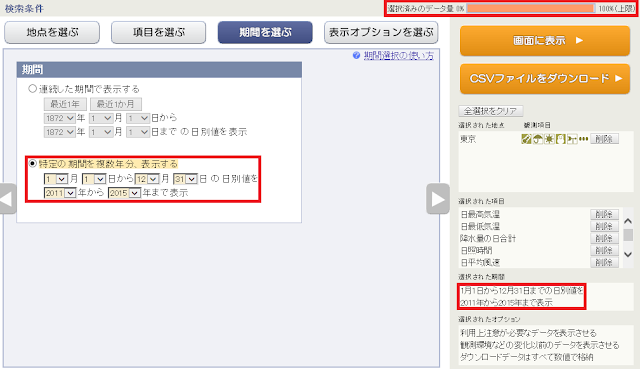
⑥「CSVファイルをダウンロード」ボタンをクリックします。

⑦ダウンロードしたCSVファイル「data.csv」を確認します。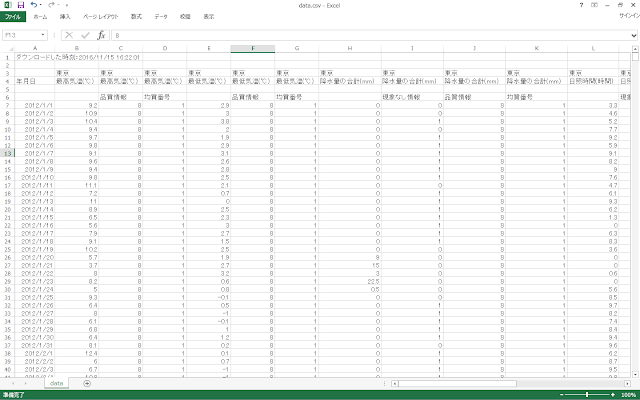
⑧他の都道府県、他の期間も同様にCSVファイルをダウンロードします。今回のデータセットでは、気象台の所在地を都道府県の気候を代表する地点とします。気象台の所在地と都道府県庁所在地が一致しなかったり、1つの都道府県に複数の気象台が存在したりするため、臨機応変な対応が必要となります。
例えば、千葉県には4つの気象台(以下の図の◎)がありますが、今回は農作物の収穫量を予測させるため、農業が盛んな「千葉北東部」にある銚子地方気象台を選択してみることにします。また、気象台によっては欠測データが多く、評価用データが不足することも考えられるため、データが存在する期間の長さも考慮して選択する必要があります。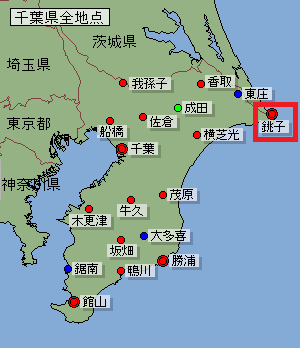
⑨ダウンロードした各CSVファイルには、設定画面で指定した統計項目以外のメタ情報などが含まれているので、それらを削除します。品質情報、均質番号、現象なし情報の列を削除した後に、1~3・5~6行目を削除します。
⑩ここまでの手順で得られた気象統計は日別のデータですが、この後追加する農作物統計は年別のデータになっています。そのため、気象統計については年別で日平均値をとることによって年別のデータへと変更する必要があります。「AVERAGE」関数等を用いて年ごとに平均値を求めたあと、地点別・年別にまとめて、CSVファイルとして保存します。この時Excelには以下のようなデータセットが出来上がっているはずです。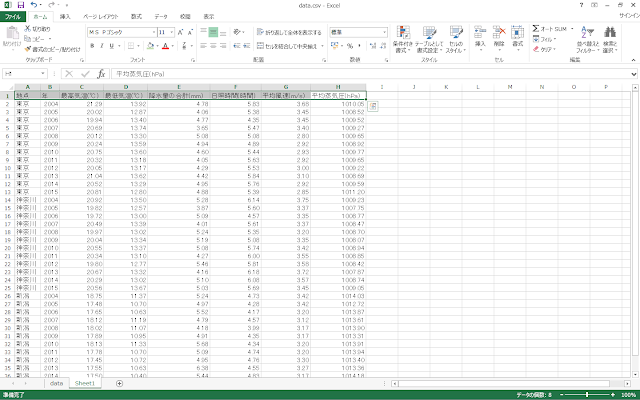
2つ目に、農林水産省によって公開されている、過去の農作物統計の取得方法をご紹介します。取得した農作物統計のうち、収穫量および作付面積のデータを使用します。
①農林水産省の統計情報を開き、「水稲の作付面積及び予想収穫量」のリンクをクリックします。
②開いたページで下方向にスクロールすると、「確報(統計表一覧)」という見出しがあるので、作物統計の、直近の年度のリンクをクリックします。
③開いたページで「水陸稲の時期別作柄及び収穫量(全国農業地域別・都道府県別) - 水陸稲計」の右横の「Excel」ボタンをクリックします。
④以前の年度のファイルも同様に保存していきます。
⑤ダウンロードしたExcelファイルを開きます。年と、都道府県ごとの作付面積と収穫量が含まれていることを確認します。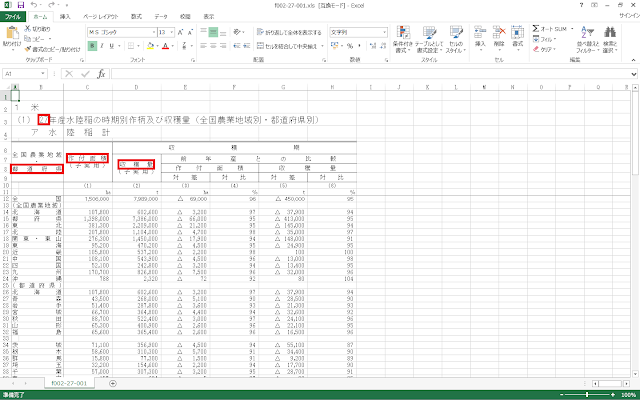
⑥Excelファイルを新規作成して、年別・都道府県別で作付面積・収穫量を整理します。「年」と「作付面積」の間に空の列が挟まっているのは、後で気象情報のデータ列を追加するためですが、学習させる上でデータ列の順番は問わないため、間に挿入せずに、右側に気象情報のデータ列を追加しても構いません。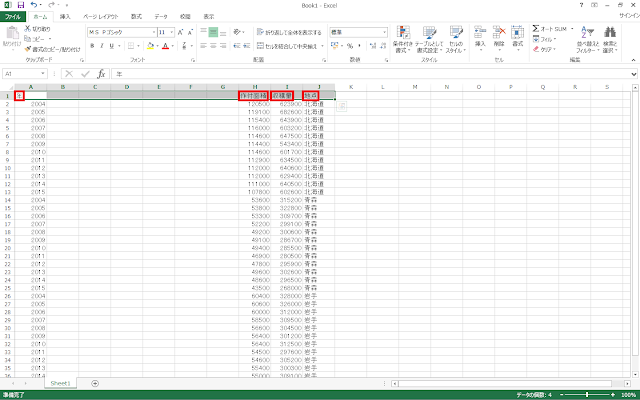
3つ目に、総務省・国土地理院によって公開されている、都道府県ごとの地理情報も取得して、データセットに含めます。今回は、都道府県コード、都道府県庁所在地の経緯度を使用します。
①総務省の全国地方公共団体コードを開きます。
②「都道府県コード及び市区町村コード」のExcelファイルをダウンロードします。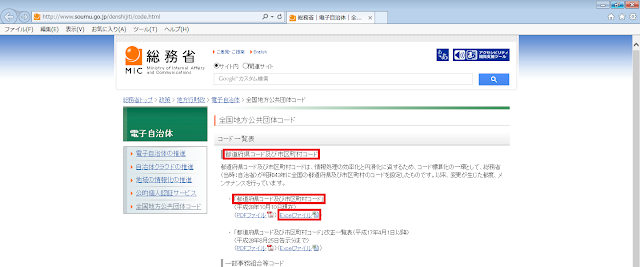
③ダウンロードしたExcelファイルを開きます。
④市区町村名が空欄ではない行をフィルタリングすることによって、都道府県名のみ書かれている行だけを抽出してみます。リボンにある「並べ替えとフィルター」>「フィルター」メニューをクリックし、「C1」セルに表示された「▼」ボタンをクリックした画面で、「(空白セル)」だけがチェックされている状態にします。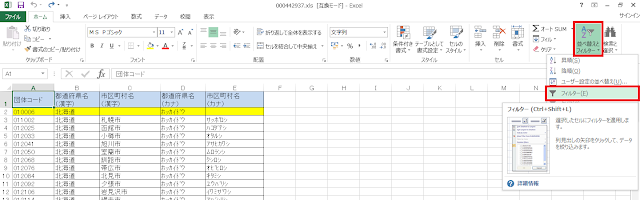
⑤下の図のように、フィルタリングされます。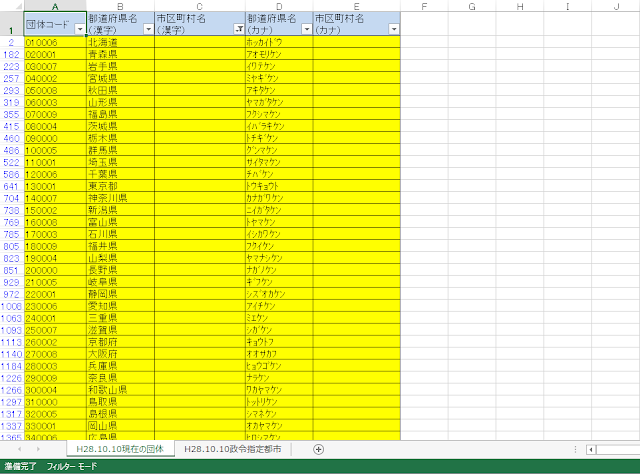
⑥「団体コード」の先頭2文字が、それぞれの都道府県に対応する「都道府県コード」になるので、先頭2文字をMID関数で取り出します。都道府県名および抽出した都道府県コードを、CSVファイルとして保存します。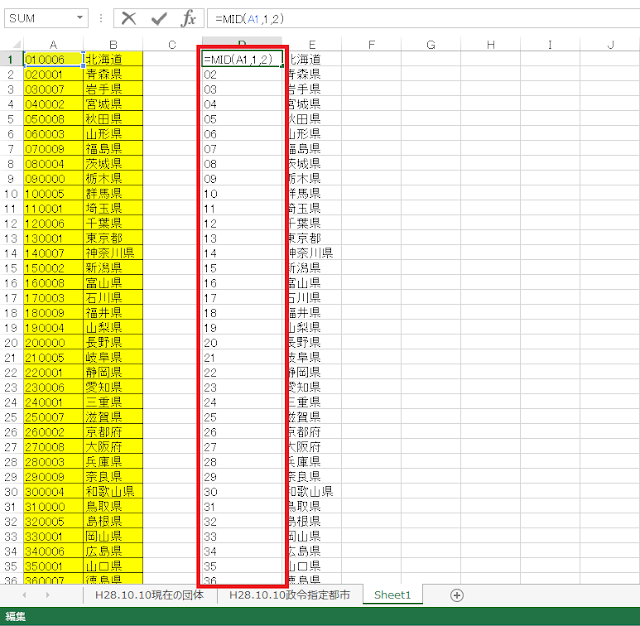
A1セルに団体コードが入力されている場合に、都道府県コードを取り出すための数式は以下のようになります。
|
=MID(A1,1,2) |
⑦続いて、都道府県庁所在地の経緯度を入手します。国土地理院の都道府県の庁舎及び東西南北端点の経緯度(世界測地系)を開きます。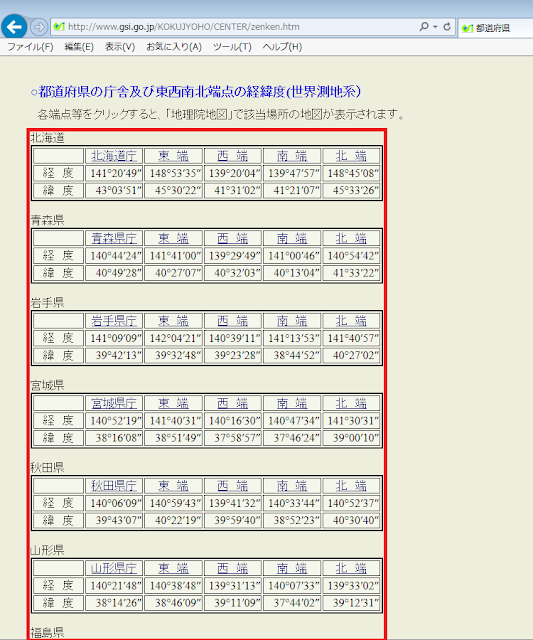
⑧Excelファイルを新規作成して、赤枠内にあるテキストをそのままコピーアンドペーストします。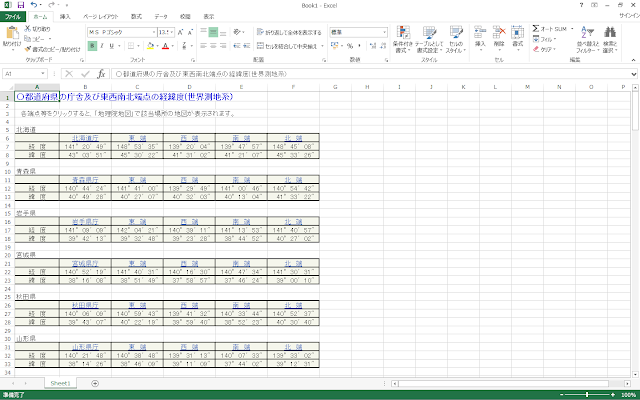
⑨このデータは、経緯度の値に「°(度)」、「′(分)」、「″(秒)」といった記号が含まれていて扱いづらいので、数値だけで経緯度を表現することができる「10進」形式へ変換してデータセットに組み込むことにします。⑧までの手順で用意した記号が含まれている経緯度値は「度分秒形式」なので、2つ目の表のⅱ番目の式を用いて変換します。
経緯度の表記方法や、それらの変換式は以下のようになっています。北緯/南緯や東経/西経が書かれていない場合は、プラスを北緯・東経、マイナスを南緯・西経と見なします。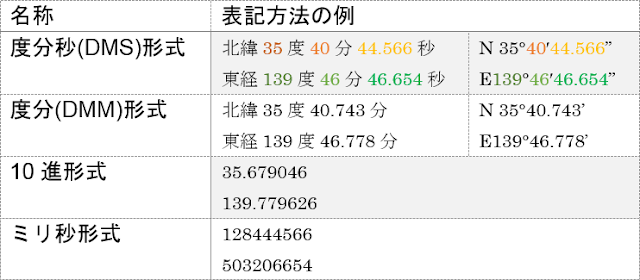
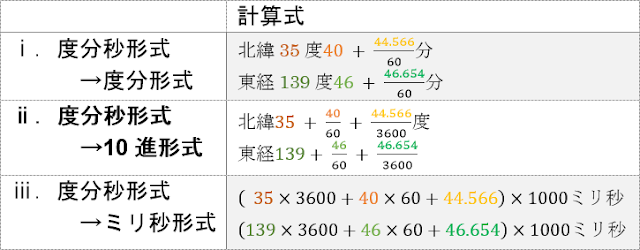
Excelを使用して変換する場合には、「都道府県コード」を加工した場合と同様にMID関数を使用すると、度/分/秒の各数値を簡単に取り出すことができます。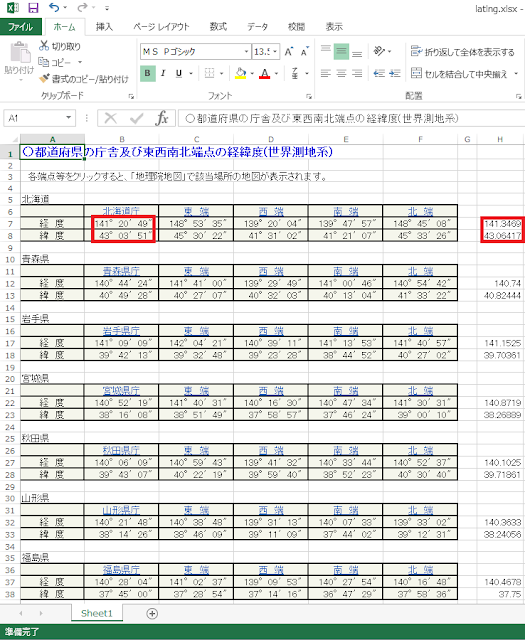
|
B7セルに経度が入力されている場合に、10進形式へ変換するためにH7セルに入力する数式 |
|
=MID(B7,1,3)+MID(B7,5,2)/60+MID(B7,8,2)/3600 |
|
B8セルに緯度が入力されている場合に、10進形式へ変換するためにH8セルに入力する数式 |
|
=MID(B8,1,2)+MID(B8,4,2)/60+MID(B8,7,2)/3600 |
⑩全都道府県について10進形式へ変換すると以下のような表が出来上がります。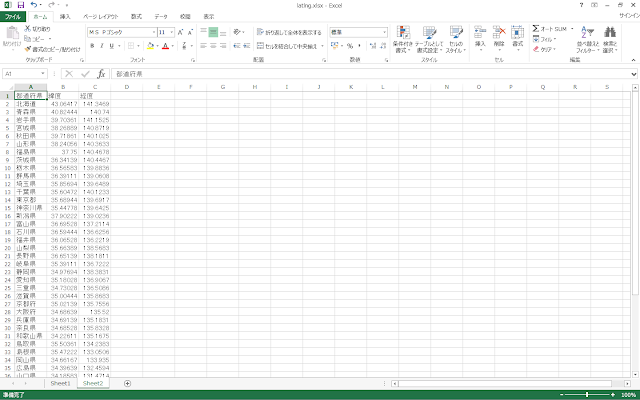
1.3.3. データ整形
ここまでの手順で用意した日本の都道府県別の気象統計と農作物の統計、各都道府県の経緯度のデータを、1つのCSVファイルにまとめていきます。これが、Azure Machine Learningに入力するデータセットとなります。このCSVファイルに載るデータ列の一覧を再掲します。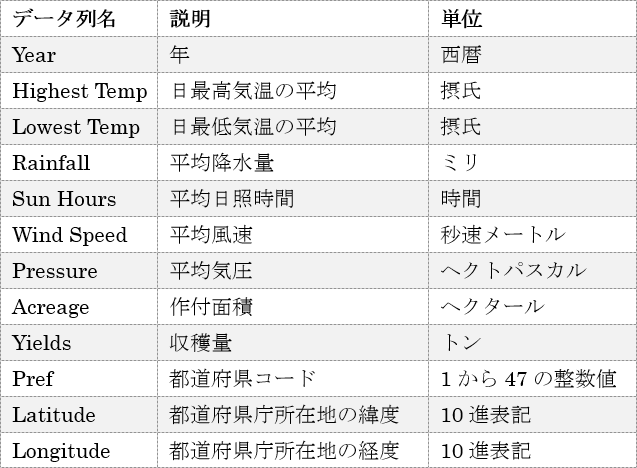
①CSVファイルを新規作成して、用意した各データを貼り付けます。拡張子が「xlsx」のExcelファイルだとAzure Machine Learningへアップロードできないので、CSVファイルで保存する必要があります。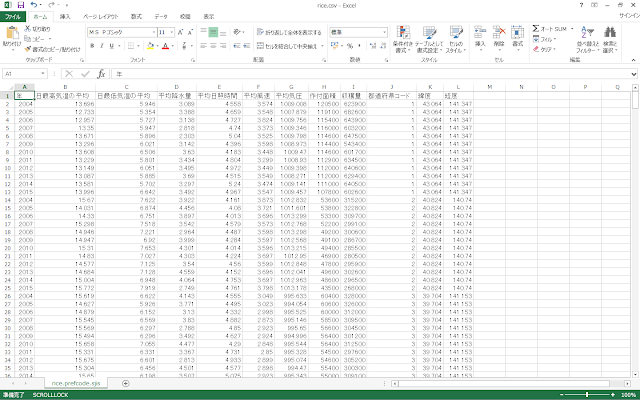
②Excelで保存されたファイルは文字コードがシフトJIS形式ですが、Azure Machine Learning上ではデータをUTF-8で扱うため、文字エンコーディングの違いが原因でエラーが発生する可能性があります。これを未然に防ぐために、データ列名の日本語を英語に直しておきます。
ここまでの手順で、CSVファイルの形でデータセットを用意することができました。
次回は、作成したデータセットをAzure Machine Learning上にアップロードし、本データセットに対する実験の作成を行い、精度評価を行ってみたいと思います。


